作者:Hadi Arzouni
编译:活水智能
来源:Vectorize
检索增强生成(RAG)已成为构建大模型应用程序的标准架构。RAG通过整合外部数据,增强了大模型能力,让大模型的回应更全面和准确。然而,要充分发挥RAG系统的潜力,要识别并克服这项技术固有缺陷。
在接下来的章节中,我们将讨论构建大模型 RAG应用程序时,一些常见的数据相关的挑战,以及克服它们的策略。
1. 数据提取技巧
挑战 :解析复杂数据结构,如嵌入表格或图像的PDF文件,可能很困难,并且需要专门技术来准确提取相关信息。
目前为止,OCR(光学字符识别)仍然是一个主要解决方案,尤其是在扫描复杂文件,如发票时。
策略 :
-
• 先从文本数据管道开始。如果你的RAG系统无法在文本数据上表现良好,那么它在图像和音频上的表现也不会好。
-
• 如果你的数据包含PDF文件,那么使用好的解析工具。一个非常常见的文档识别方法是:将问题分割成较低复杂度的子问题。例如:如果你正在构建一个用于阅读医疗发票的RAG,那么你可以使用OCR工具识别特定字段,如总金额、税额等。如果需要,还可以使用高级视觉模型(GPT-4视觉在处理复杂PDF文档方面表现出色)。
-
• 值得注意的是,微软Azure可能拥有最佳的企业级预构建文档识别/理解工具(产品名称:Document Intelligence)。
2. 处理结构化数据
挑战 :大模型擅长处理非结构化数据,如自由流动的文本,但在处理结构化数据方面表现不佳,例如表格数据。
当尝试使用大模型处理表格数据时,会出现许多问题,包括高比率的幻觉问题。我的建议是,尽量避免在表格数据上使用大模型。如果没有选择,那么:
策略 :
-
• 将表格数据转换为非结构化文本。在此过程中,你需要小心:
-
• 数值表示:传统的分词方法,如字节对编码(BPE),将数字分割成不对齐的令牌,这使得大模型进行算术运算变得复杂。新型模型,如LLaMA,单独对每个数字进行分词,改善了对符号和数值数据的理解。
-
• 分类表示:表格数据中列过多,可能导致序列化输入字符串超出大模型的上下文限制,从而导致数据修剪和性能问题。分类特征表述不清晰,如无意义的字符,也可能阻碍LLM的处理和理解。
-
-
• 采用如链式表格方法等技术。该方法结合了表格分析与逐步信息提取策略,增强了RAG系统中的表格问答能力。
3. 确定分块策略
挑战 :
确定将文档划分为语义上独立部分的最佳块大小,同时平衡对全面上下文的需求和快速检索的需求。更长的上下文会导致更长的推理时间(尝试使用Gemini 1.5 pro,上下文令牌为1M!),而较小的上下文块可能导致回答不完整。
另一个分块策略的主要挑战是分块策略本身,即你应该基于句子分块?段落?字数?等等
策略 :
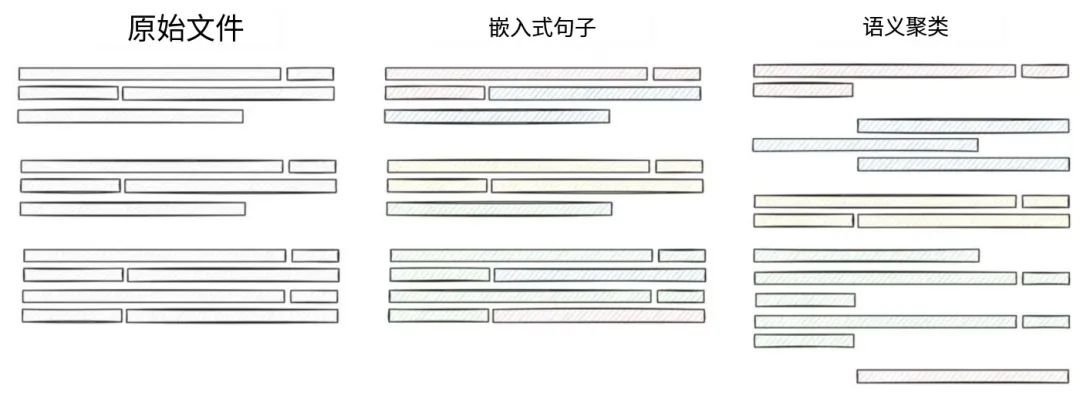
从简单的开始并迭代:首先选择一个简单的分块策略,进行评估,测量一切,我在这篇文章中更详细地谈到了分块策略:https://heycloud.beehiiv.com/p/text- splitting-chunking-rag-applications。
块大小应该遵循分块策略,而不是相反,意思是:首先确定你想要遵循的策略,然后考虑到你的策略和LLM的上下文大小来确定块大小。
例如:如果你的数据是新闻文章的集合,那么段落级别的分块可能会有效,而且由于大多数LLM的上下文大小大于一个段落,那么你可以采用可变的块大小,即一个段落的大小。
4. 创建可扩展的流程
挑战 :构建一个完善且可扩展的RAG流程,以处理大量数据,并持续地将其索引和存储在向量数据库中。大多数RAG应用程序构建者将这部分作为后期考虑,这是有道理的,因为你的首要目标是制作一个有效的东西。
然而,如果你知道你的应用最终将每小时处理TB级别的数据,那么你可能必须考虑到这一点来设计整个应用。
策略 :
-
• 再一次,从简单开始 🙂 我想你现在应该明白了!
-
• 尽早估计你的应用规模,即使你一开始不需要根据这些信息采取行动。
-
• 如有必要,采用模块化和分布式系统方法,将管道分解为可扩展单元,并采用分布式处理以提高并行操作效率。
-
• 使用经过实战测试的工具部署你的应用,如kubernetes。Kubernetes的好处是你可以根据需要进行扩展。例如,如果你需要一个定期的cron作业来清理新获取的数据,那么你可以安排它,并确保作业完成后它会消失,从而为你节省计算资源和金钱。
5. 让检索数据在上下文中
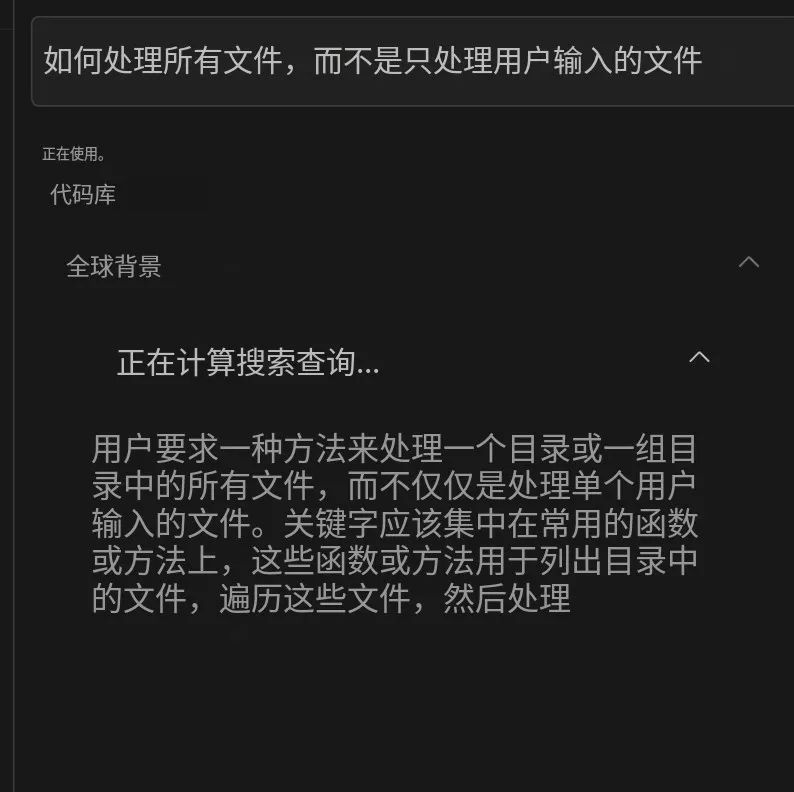
挑战 :RAG系统可能检索到不相关的数据,或者没有提供准确回应生成所需的必要上下文。这通常是由于:错误的嵌入、错误的用户查询、上下文截断等原因造成的。
策略 :
- • 使用查询增强/重写来增强用户查询,通过额外的上下文或修改来提高检索信息的相关性。Cursor.sh的查询重写就是一个很好的例子。
-
• 探索不同的检索策略,如从小到大的句子窗口检索和语义相似性评分,以将相关信息纳入上下文。
-
• 一个更高级的技巧是使用生成式UI来澄清用户意图。例如,你可以通过询问用户澄清其查询来回应用户的查询,以确保检索引擎检索到完整的上下文,然后再回答查询。Morphic.sh就是一个使用动态生成的UI来澄清用户查询的答案引擎的好例子。
-
• 投资于监控解决方案以可视化提示、块和响应。
6. 以任务为导向检索
挑战 :RAG应用程序应该能够处理各种用户查询,包括寻求摘要、比较或特定事实的查询。因此,用一个检索提示来处理所有用户查询可能不够。
策略 :
- • 实施查询路由,以根据初始用户查询识别适当的工具或来源子集,确保针对不同用例的适应性检索。路由通常涉及创建多个索引和一个分类器。分类器可以是一个小型且成本低廉的LLM,将查询分类并将其路由到相应的索引。
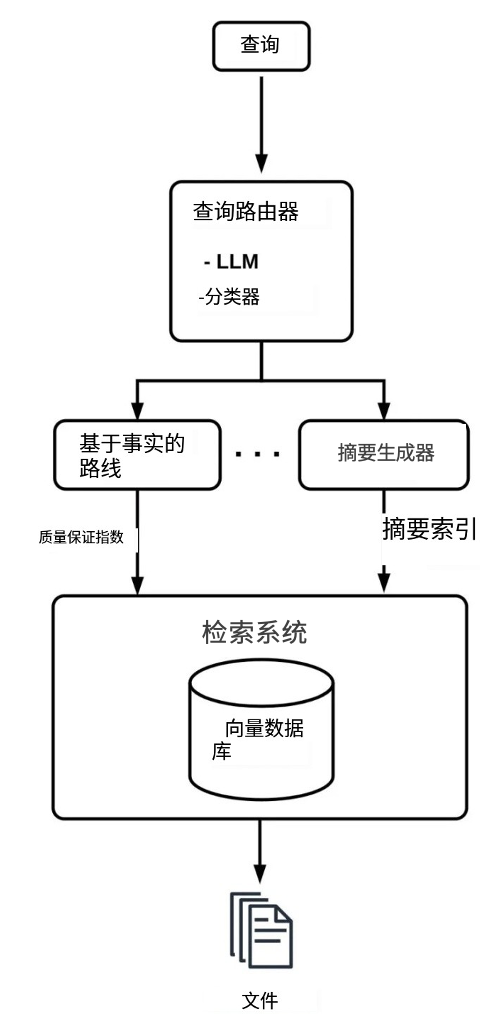
来源:https://mlnotes.substack.com/p/adaptive-query-routing-in-retrieval
7. 确保数据实效性
挑战 :确保RAG应用程序始终使用最新和最准确的信息,特别是当文档更新时。
策略 :
-
• 实施元数据过滤,它充当标签以指示文档是新的还是已更改的,确保应用程序始终使用最新信息。
-
• 如在“确保数据在上下文中”中所述,一个更高级的技巧是使用生成式UI来澄清用户对最新性的意图。例如,你可以通过询问用户澄清他们是否在询问最近的事件或一般事件等来回答用户查询。
-
• 在某些情况下,LLMs会混淆它们内部学习到的关于日期的信息和外部数据时间戳,因此,在提示中明确使用哪个是很重要的。
8. 应对数据安全
挑战 :确保在RAG应用程序中使用的LLMs的安全性和完整性,防止敏感信息泄露,并解决伦理和隐私考虑。
我在这里写了关于构建RAG应用程序时应考虑的安全威胁。总结如下:
策略和考虑 :
-
• 实施多租户以保持用户数据的私密性和安全性是最重要的缓解策略之一。
-
• 正确处理用户提示,确保它不会滥用LLM。
-
• 分析RAG数据以寻找任何数据污染的迹象。
结 论
数据是任何RAG系统的核心部分。数据问题可能会使你的RAG系统无法使用,或者更糟糕的是,使你的用户面临安全威胁。
因此,意识到常见挑战并采取最佳策略来正确处理RAG数据非常重要。在本文中,我们试图正是解决这些常见问题,从缺失的上下文到数据安全等。■
参考文献
-
https://www.anyscale.com/blog/a-comprehensive-guide-for-building-rag-based-llm-applications-part-1
-
https://mlnotes.substack.com/p/adaptive-query-routing-in-retrieval
-
https://arxiv.org/html/2402.17944v2
-
https://www.hopsworks.ai/dictionary/retrieval-augmented-generation-llm
-
https://humanloop.com/blog/optimizing-llms
-
https://gretel.ai/blog/how-to-improve-rag-model-performance-with-synthetic-data
-
https://www.rungalileo.io/blog/optimizing-llm-performance-rag-vs-finetune-vs-both
-
https://heycloud.beehiiv.com/p/cheaper-faster-rag-sql-layer
-
__
推荐阅读
• 多图预警!一文串联19篇顶级论文,带你厘清大模型发展脉络!