作者:Abhishek Thakur
编译:活水智能
来源: https://huggingface.co/blog/abhishek/phi3-finetune-macbook
在这篇文章中,我会指导你如何在你的MacBook Pro上训练或微调最新的Microsoft Phi-3模型!你将需要一台配备M1或M2芯片的Mac。我们将利用AutoTrain Advanced进行操作。
首先安装AutoTrain Advanced,你可以执行以下命令:
``` pip install autotrain-advanced
`
注意:安装AutoTrain不会自动安装Pytorch、Torchvision等依赖,你需要手动安装这些。建议在一个新的Conda环境中安装:
$ conda create -n autotrain python=3.10
$ conda activate autotrain
$ conda install pytorch::pytorch torchvision torchaudio -c pytorch
$ pip install autotrain-advanced
安装完成后,你可以在你的Mac上通过命令行界面(CLI)或用户界面(UI)来使用AutoTrain!本文将介绍这两种方式。
AutoTrain不仅支持大语言模型(LLM)的微调,还包括文本分类、图像分类、dreambooth lora等多种任务。本文将重点讨论微调大模型。
通过以下命令,你可以查看所有可调整的大模型参数:
` autotrain llm --help
`
接下来是数据获取。我将向你展示如何在你的MacBook上进行SFT训练和ORPO调优(DPO的小型版本)。
-
• 对于SFT训练,需要一个只包含单一文本列的数据集,如timdettmers/openassistant-guanaco(https://huggingface.co/datasets/timdettmers/openassistant-guanaco)或类似alpaca的数据集。这些数据集已经按照系统提示、用户指令和助手消息的格式进行了组织。如果你的数据集是以下格式:
[ { ”content”: ”Definition: In this task, you need to count the number of vowels (letters ’a’, ’e’, ’i’, ’o’, ’u’) / consonants (all letters other than vowels) in the given sentence.\nInput: Sentence: ’a baseball player is in his hitting stance as a few people watch’. Count the number of consonants in the given sentence.\nOutput:”, ”role”: ”user” }, { ”content”: ”32”, ”role”: ”assistant” } ]
你可以利用AutoTrain的chat- template参数。我们将在本文后面讨论这个参数,但它将用于ORPO训练。因此,我们将使用预格式化的数据集进行SFT训练,并在ORPO训练中应用聊天模板。
- •对于ORPO训练,可以使用argilla/distilabel-capybara-dpo-7k-binarized(https://huggingface.co/datasets/argilla/distilabel-capybara-dpo-7k-binarized)这样的数据集,我们只关注
chosen和rejected两个字段。
在AutoTrain中,寻找或创建数据集可能是最耗时的部分。当我们准备好数据集后,可以开始SFT训练:
autotrain llm \
--train \
--model microsoft/Phi-3-mini-4k-instruct \
--data-path timdettmers/openassistant-guanaco \
--lr 2e-4 \
--batch-size 2 \
--epochs 1 \
--trainer sft \
--peft \
--project-name my-own-phi-3-on-mac \
--username abhishek \
--push-to-hub \
--token $HF_TOKEN
$HF_TOKEN是你的Hugging Face写入令牌,如果你打算将训练后的模型推送到Hugging Face Hub以便共享和部署,你将需要它。你可以在这里(https://huggingface.co/settings/tokens)找到你的令牌。
请注意,我们使用了lora技术,这是为什么我们需要--peft参数。如果你的数据集中的文本字段不是text,你还可以通过--text-column
your_datasets_text_column参数来指定。
如果你选择使用本地CSV或JSON文件而不是Hugging Face Hub的数据集,你可以将其命名为train.csv或train.jsonl,并放在本地目录中。此时,训练命令将稍有不同:
autotrain llm \
--train \
--model microsoft/Phi-3-mini-4k-instruct \
--data-path /path/to/folder/containing/training/file \
--text-column text_column_in_your_dataset \
--lr 2e-4 \
--batch-size 2 \
--epochs 1 \
--trainer sft \
--peft \
--project-name my-own-phi-3-on-mac \
--username abhishek \
--push-to-hub \
--token $HF_TOKEN
然后我们转到ORPO训练。对于ORPO训练,我们将--trainer sft改为--trainer orpo:
autotrain llm \
--train \
--model microsoft/Phi-3-mini-4k-instruct \
--data-path argilla/distilabel-capybara-dpo-7k-binarized \
--text-column chosen \
--rejected-text-column rejected \
--lr 2e-4 \
--batch-size 2 \
--epochs 1 \
--trainer orpo \
--chat-template chatml \
--peft \
--project-name my-own-phi-3-on-mac-orpo \
--username abhishek \
--push-to-hub \
--token $HF_TOKEN
在这个命令中,主要变化是列映射和训练器的选择,以及数据集的使用。一个重要的变化是引入了--chat-
template参数,设置为chatml。对于--chat-
template,你可以选择zephyr、chatml、tokenizer或None。
如果你已经按照需求格式化了数据,就可以选择None,就像我们在SFT训练中做的那样。
如果你觉得命令行界面(CLI)操作复杂,你也可以选择使用用户界面(UI),这更简单,还可以让你上传文件。
要使用UI,请执行:
$ export HF_TOKEN=your_huggingface_write_token
$ autotrain app --host 127.0.0.1 --port 10000
然后在你的浏览器中访问http://127.0.0.1:10000,享受AutoTrain的用户界面!🚀 如下图所示,这是使用上述ORPO训练参数的屏幕截图:
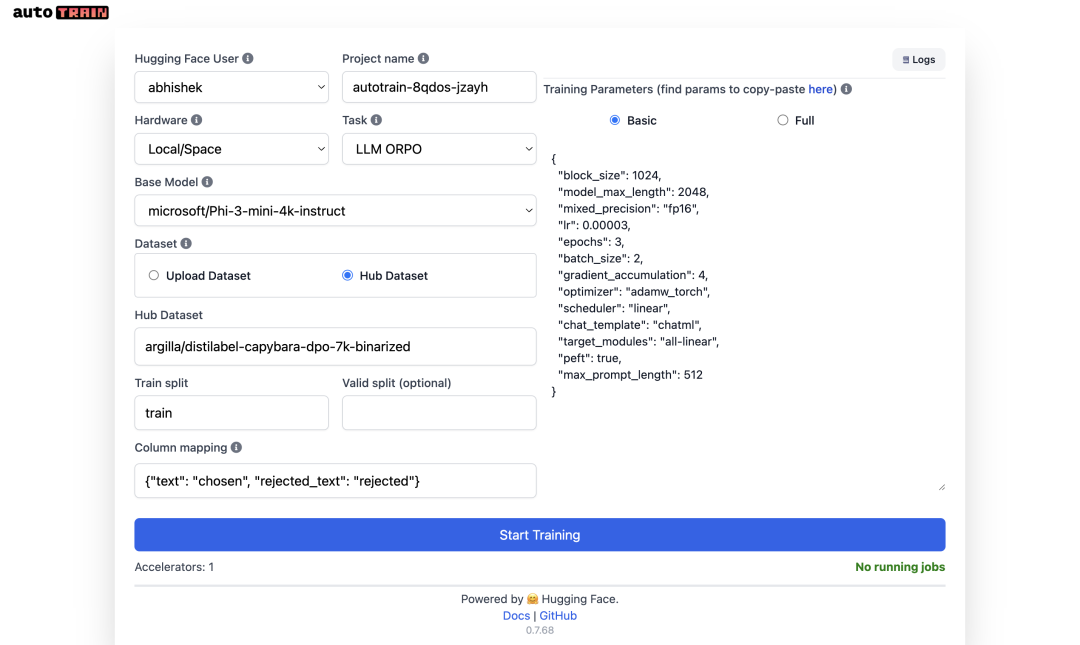
如果在模型下拉列表中找不到phi3,你可以使用这个URL:http://127.0.0.1:7860/?custom_models=microsoft/Phi-3-mini-4k-instruct。注意:我已经将phi-3添加为自定义模型。你也可以为Hub中的任何其他兼容模型进行同样的操作。;)
无论是SFT训练还是ORPO训练,都已在M2 Max MacBook Pro上成功测试。
如果遇到任何问题或有功能请求,欢迎使用github repo(https://github.com/huggingface/autotrain- advanced)。
附注:你可以在这里(https://hf.co/docs/autotrain)找到AutoTrain的详细文档。
祝你自动训练愉快!■
推荐阅读
• AI21 Labs 实践经验:让大模型从“新奇玩具”到生产力工具