
编辑:晓霖
聪明生产力
让 LLM 用 JSON 格式输出答案
如果你打算将 LLM 嵌入工作流,你可能希望 LLM 返回的结果能让机器识别并处理,以便程序顺着工作流自动执行后面的步骤。例如你要做一个评分系统,让 LLM
批量评估文本并打分,返回包含「分数」和「理由」的答案。如果它每次返回内容的格式都不一样,你的程序就要处理更多判断文本格式的工作,此时你会希望它返回一个标准的
JSON 格式,就像这样:{"score":8,"reason":"It is pretty good."}。
利用 API 的 JSON 模式
第一个方法是利用 Openai DevDay 推出的「JSON 模式」。在调用 gpt-4-1106-preview 或
gpt-3.5-turbo-1106 时,将response_format设置为{"type": "json_object"} 即可启用 JSON
模式,模型被约束为仅生成可解析为有效 JSON 对象的字符串。例如这样发送请求:
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
response_format={ "type": "json_object" },
messages=[
{"role": "system", "content": "You are a helpful assistant designed to output JSON."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
)
print(response.choices[0].message.content)
答案会返回一个 JSON 对象:
"content":"{\"winner\":\"Los Angeles Dodgers\"}"
需要注意的是,使用 JSON 模式时要明确要求模型生成 JSON,就像上面的例子那样在 System 消息明确要求。如果上下文没有包含 “JSON”
字符,API 会抛出错误。如果max token或finish_reason的设置发生冲突,答案太长时也可能会被截断,最终生成的结果不是完整的
JSON 格式。
利用 Function Calling 功能
Function Calling 可以让 LLM 在输出最终结果前,自动判断是否调用某个预设的函数。例如当你提问:“今天天气怎么样?” 时,LLM 在输出结果前会先判断一轮,认为这个任务需要调用查询天气的函数,于是将参数 “今天” 传入这个函数并执行。最终,LLM 根据函数返回结果输出答案。为了方便解析,Function Calling 在判断该调用什么函数时,会输出一个标准的 JSON 格式。我们可以利用这个特点来控制 LLM 的输出格式。
我们把 ChatGPT
输出的内容定义成一个函数,让它按函数的参数格式输出结果。以评分系统为例,我希望它输出这样的答案:{"score":8,"reason":"It is
pretty good."}。那么在调用 GPT 时,要先定义一个函数,将函数的参数格式与将要输出的 JSON 格式对应起来:
{
"name": "getScore",
"description": "Get score of text",
"parameters": {
"type": "object",
"properties": {
"score": {
"type": "number",
"description": "Text's score"
},
"reason": {
"type": "string",
"description": "Score's reason"
},
},
"required": ["score", "reason"]
}
}
当然,使用这个方法的前提是该模型支持 Function Calling。
在上下文给出格式示例
在上下文列出一个或多个输出格式的示例,让 LLM 按要求输出结果,是使用 Chat Completions 的常见方法,也就是 few-shot。在 Prompt 或者 System 消息指定 LLM 始终返回预设的 JSON 对象,也是一种简单有效的方法。缺点是 LLM 可能不会每次都生成可解析为有效 JSON 对象的答案,这个问题在 GPT-3.5 比较常见,GPT-4 也偶尔出现。
如果你使用 GPT-4,还可以在上下文用 TypeScript 的类型定义要输出的格式,甚至用注释来说明字段含义,GPT-4 会按照给定的类型定义输出结果。
大模型动态
IBM 与 Meta 牵头组织 AI Alliance
AI Alliance 是一个由技术创造者、开发者和采用者组成的社区,致力于推进植根于开放创新的安全、负责任的人工智能,拥有 IBM、Meta、AMD、Anyscale、CERN、Cerebras、克利夫兰诊所、康奈尔大学、达特茅斯学院、戴尔科技、EPFL、ETH、Hugging Face、伦敦帝国理工学院、英特尔、 INSAIT、Linux 基金会、MLCommons、波士顿大学和哈佛大学运营的 MOC 联盟、NASA、NSF、Oracle、Partnership on AI、Red Hat、Roadzen、ServiceNow、索尼集团、Stability AI、加州大学伯克利分校、伊利诺伊大学、圣母大学、东京大学、耶鲁大学等 50 多个创始成员和合作者。
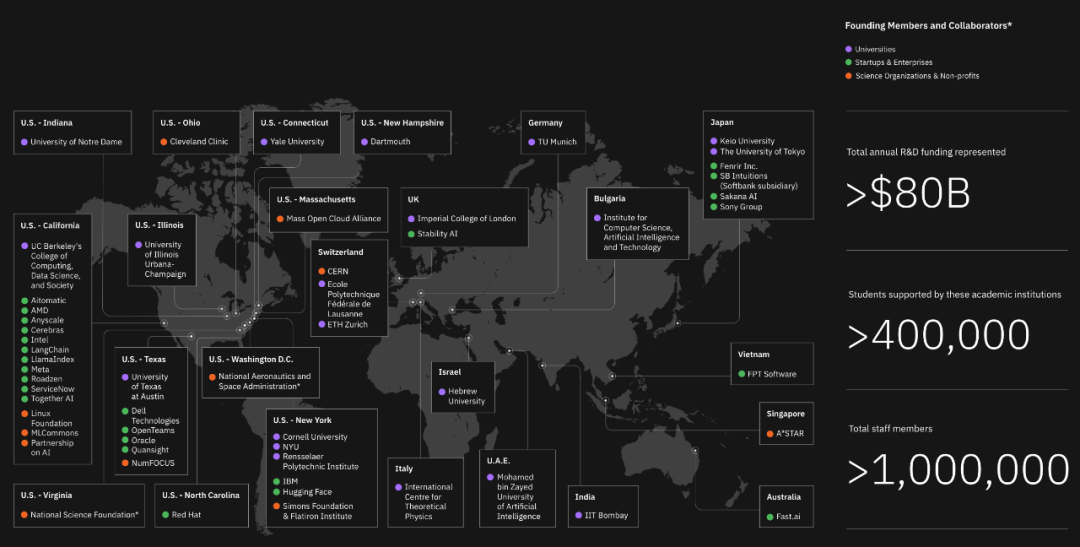
▲ AI Alliance 成员
AI Alliance 汇集了大量算力、数据、工具和人才,以加速人工智能的开放创新,专注于在人工智能技术领域加速和传播开放创新,以提高人工智能的基础能力、安全性、保障性和信任度,负责任地最大限度地为世界各地的人民和社会带来利益。AI Alliance 的目标是构建并支持跨软件、模型和工具的开放技术;使开发人员和科学家能够理解、试验和采用开放技术;与组织和社会领导人、政策和监管机构以及公众一起倡导开放创新。
官网:https://thealliance.ai
Google 推出 Gemini 三个版本大模型
当地时间 12 月 6 日,谷歌 CEO 桑达尔・皮查伊官宣 Gemini 1.0 版正式上线,包括能力最强的 Gemini Ultra、适用于多任务的 Gemini Pro 、适用于特定任务和端侧的 Gemini Nano,号称迄今为止规模最大,能力最强的谷歌大模型。
Gemini 是一个多模态大模型,使用网络、书籍、代码等文本数据以及图像、音频、视频数据进行预训练,可以泛化且无缝地理解、操作和组合文本、代码、音频、图像和视频等不同类型的信息。Gemini 还是谷歌迄今为止最灵活的模型,能够高效地运行在数据中心和移动设备等多类型平台上,Gemini 提供的 SOTA 能力将显著增强开发人员和企业客户构建和扩展 AI 的方式。
目前,Bard 已经升级到 Gemini Pro 版本,实现更强的推理、规划、理解等能力。谷歌预计将在明年初推出使用 Gemini Ultra 的 Bard Advanced。Pixel 8 Pro 录音机应用的总结功能和键盘的联想功能已经启用 Gemini Nano,可以离线使用。从 12 月 13 日开始,开发者和企业客户可以通过 Google AI Studio 或 Google Cloud Vertex AI 提供的 Gemini API 访问 Gemini Pro。
博客链接:https://blog.google/technology/ai/google-gemini-ai/#scalable-efficient
测试报告:https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
AI时代洞见
A16Z:Big Ideas in Tech for 2024
智能电网、语音优先的配套应用程序、可编程药物、儿童人工智能工具……
40 多位 A16Z 合伙人受邀展望 2024 年,分别预测一个即将推动 2024 年创新的大创意。文章分为美国活力、生物+健康、消费类技术、技术创意、加密货币、金融科技、游戏、成长期科技、基础设施+企业等九大部分。
全文:https://a16z.com/big-ideas-in-tech-2024
Reference
https://platform.openai.com/docs/guides/text-generation/json-mode
https://platform.openai.com/docs/guides/function-calling
https://baoyu.io/blog/prompt-engineering/how-to-parse-the-output-from-llm

活水智能 致力于通过人工智能提高知识工作者的生产力,作为「AI时代的生产力专家」,我们的核心目标是为用户提供最先进的AI技术和工具,帮助用户更高效、更智能地完成工作。