
编辑:晓霖
供稿:妙生 郑嘻嘻
聪明生产力
在 Google Colab 直接调用 transformers 库
Google Colab(全称 Colaboratory)是一种托管式 Jupyter 笔记本服务,适合机器学习、数据分析和教育用途。用户无需设置,即可在浏览器上直接编写和执行 Python 代码。
近期,Colab 已默认集成 Hugging Face 的 transformers 库,只需执行import transformers即可接入。
你可以通过!pip install transformers --upgrade命令将 transformers 库更新至最新版本。
此外,近期已支持通过hf://datasets/的方式,直接从 Pandas 读取 Hugging Face Hub
上的数据集,进一步简化了数据处理和模型训练的工作流程。
大模型动态
GPT 应用商店推迟至 2024 年初推出
12 月 2 日,OpenAI 的 ChatGPT 团队向 GPT 开发者发了一封邮件,宣布 “GPT 商店” 将推迟至 2024 年发布。目前他们正在改进 GPT 功能,更新配置界面以实现一键测试,还准备增加预览中的调试信息,并支持多个域名。值得注意的是,在使用代码解释器时,上传的文件可以被用户下载。目前这个功能已经默认关闭,并增加提示。
不过,你不必等到明年。现在立即访问活水智能上线的 “活水大师”,随时随地与专属的 GPT 大师们对话!
“活水大师”是基于大模型打造的大师级顾问,包含技术、效率、心理、生活等七大类别,每类提供六位大师,总计 42 位大师帮你解答生活中的难题。
活水大师阵营中,有中文写作大师周爱文、哲学大师苏格拉底、心理学大师贝克 & 罗杰斯等等。如果这么多大师仍无法满足需求,还有 GPT 大师,帮你从成千上万个选择中匹配出你最想找的 GPT 大师。
活水大师官网:https://42master.io

访问活水大师官网,点击对应的大师,即可开启你与大师的对话。
ChatGPT 一周年
去年11月30日,OpenAI 推出 ChatGPT。随后一年,尤其是今年3月14日推出 GPT-4 之后,GPT 更大范围地进入大众视野。活水智能邀请 GPT-4 与人工合作梳理了这一年来 GPT 的里程碑事件。
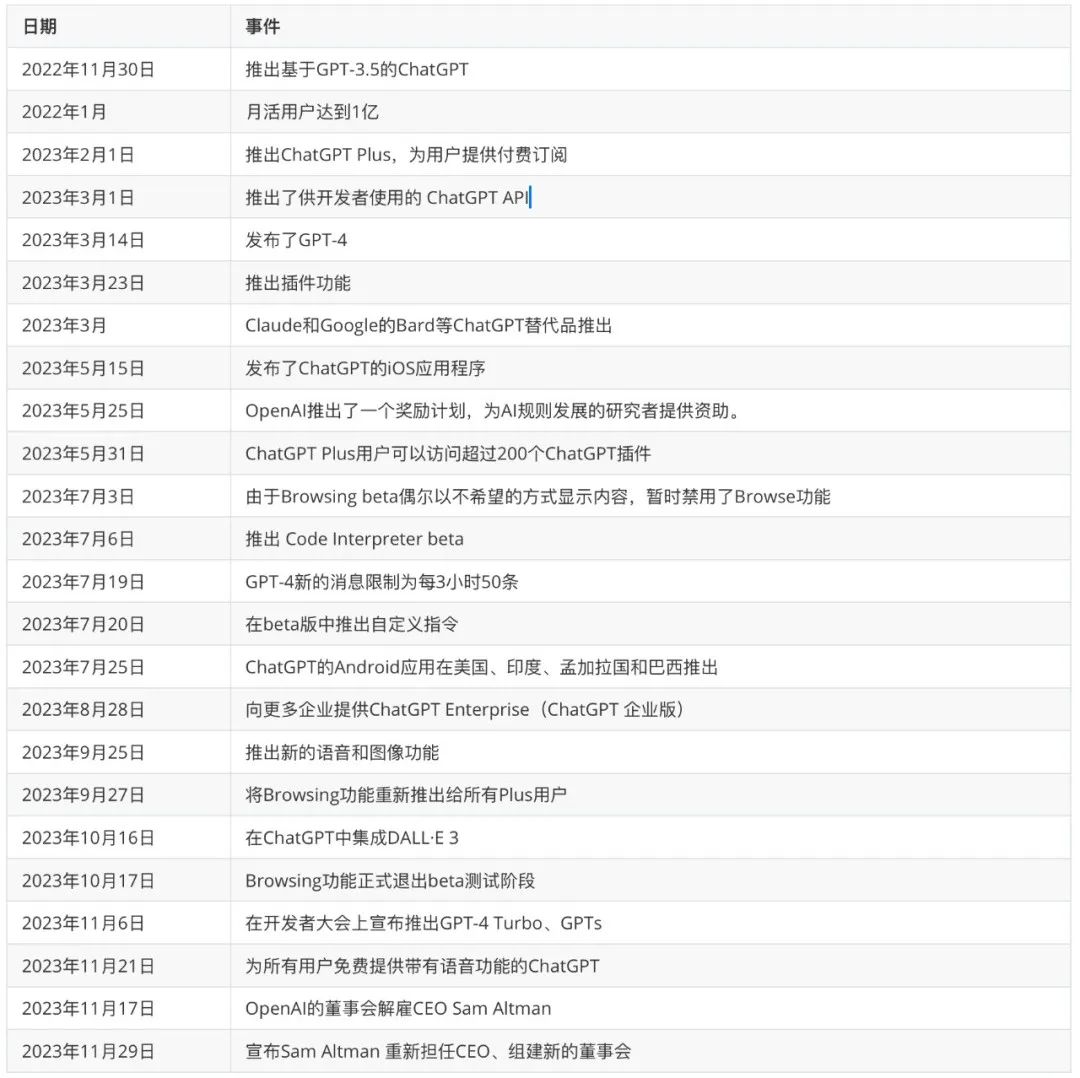
▲ GPT推出一年来的里程碑事件
**
**
更多模型可供选择
一年前,ChatGPT 几乎是消费者通过网络用户界面与大型语言模型(LLM)交互的唯一选择,而 OpenAI 的模型则是开发者调用 API 的主要选择。现在,无论是开源还是闭源大型语言模型,用户都有更多选择。
对于普通消费者来说,除了与 ChatGPT 交流,还可以选择 Microsoft Bing、Google Bard、Anthropic Claude、Inflection Pi 和 Perplexity.ai 等产品。对于开发者来说,除了 OpenAI,还可以选择 AWS、Azure、Cohere、Google Cloud, Hugging Face 等公司提供的 API 服务,实现更复杂的人工智能功能。这不仅体现了技术的进步,还意味着市场的良性竞争。
开源模型迎头赶上
随着技术的快速发展,许多开源大模型和小型专有模型正在迎头赶上,自托管或在本地运行的开源模型也表现出相当不错的性能。在许多情况下,这些模型的性能已经可以与一年前的 ChatGPT-3.5 相媲美。
与此同时,开源的 GPT4All、MLC 和闭源的 LM Studio,也让用户在本地运行模型变得更加简单。即使没有太多技术背景,你也可以借助这些工具配置和运行大语言模型。
GPT4All:https://gpt4all.io/index.html
MLC:https://llm.mlc.ai
LM Studio:https://lmstudio.ai
这篇论文调研了在各个领域与任务中与 ChatGPT 表现相当甚至更好的开源大模型: ChatGPT’s One-year Anniversary: Are
Open-Source Large Language Models Catching
up?__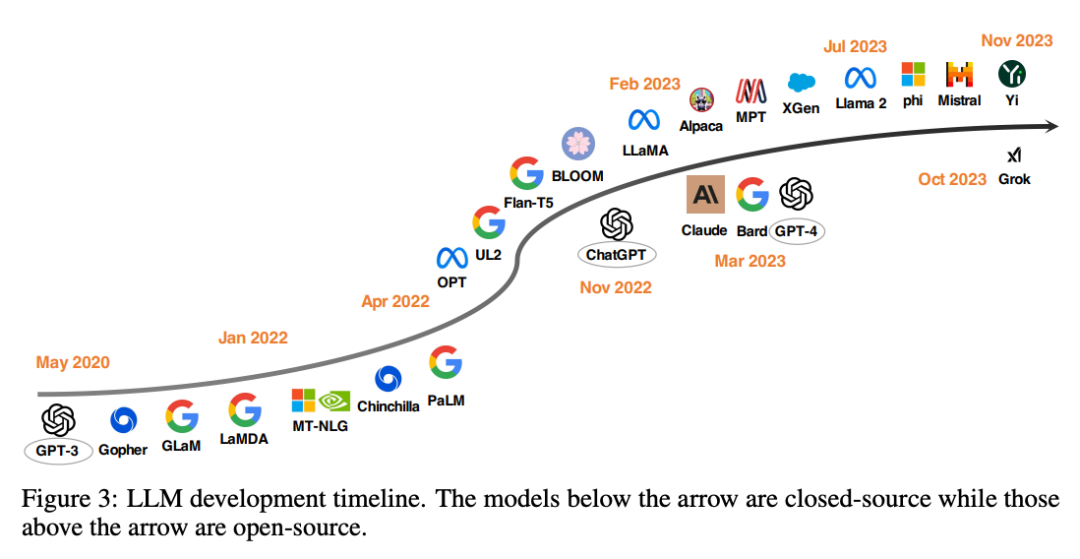
论文链接:https://arxiv.org/pdf/2311.16989.pdf
数据代码:https://github.com/ntunlp/OpenSource-LLMs-better-than-OpenAI
AI时代洞见
人工智能:一种新的智能
如果你关心未来人类将如何与更加智能的 AI 共处,杨立昆(Yann LeCun)在 AI: Grappling with a New Kind of Intelligence 的精彩发言也许能给你启发。以下是他的部分观点:
「智能」与「控制欲」没有必然联系
毫无疑问,未来我们将拥有智力水平可与人类相媲美的人工智能(AI)系统,这可能将发生在几十年后。这些 AI 系统不仅在特定领域专业化,而且可能在人类擅长的所有领域都比人类更聪明。
你可能会担心,这样的系统会不会掌控世界?其实,「智能」与「控制欲」之间并没有必然联系。以人类为例,虽然有些人有控制欲,但并非所有人都是如此,而且通常不是最聪明的人才有控制欲。国际政治舞台上的种种事件每天都在证明这一点。这背后可能有进化上的原因:不够聪明的人需要依赖他人,因此会试图影响他人;而聪明的人可以独立生存。
我们已经习惯与比自己聪明的人合作
我曾领导一个研究实验室,只雇佣比我聪明的人。与比自己更聪明的人共事是一种美妙的经历。想象未来 10 到 20 年,我们可能拥有比自己更聪明的 AI 助手。它们的存在并不是为了控制我们,而是帮助我们变得更聪明,我们指导它们,它们服务于我们。智能本身并不意味着渴望控制。
「控制欲」源自于我们作为社会性物种的本性。我们像黑猩猩、狒狒、狼等社会性动物一样,有着等级制的社会组织。进化赋予我们这种特征。而非社会性物种,如猩猩,即使智力接近人类,也不表现出控制他人的渴望。
「智能」与「控制欲」是两码事,我们完全可以设计一个极为智能但不具备控制欲的系统。这些系统被设计得非常聪明,你给它们一个目标,它们可以帮你实现。但设定目标的是我们人类,这些系统制定子目标。
基础架构必须开源,训练方式必须众包
如果未来我们与数字世界和信息世界的所有互动都通过 AI 代理来完成,这些 AI 代理将成为所有人类知识的宝库,类似于一个能进行对话和推理的 “超级维基百科”。就像如今的互联网,它必须是开放的公共平台,不能是专有的。只掌握在少数公司手中的超级智能 AI 将是非常危险的。如果少数几家公司控制着这些超级智能 AI,他们可以左右每个人的观点、文化等等。或许美国政府会接受这种情况,但全世界的其他政府绝不会同意,他们不希望自己的文化被美国文化所主导。因此,它们可能会开发自己的大语言模型(LLM)。
解决这一问题的唯一方式是基于开源的基础架构。这就是 Meta 开源 Llama2 的原因之一,因为它是基础设施的一部分。此前,Meta 还发布了用于构建人工智能系统的软件系统 PyTorch,而 ChatGPT 就是基于 PyTorch 构建的。这些系统必须开源,并且它们的训练方式也必须众包,成为所有人类知识的仓库。所有人都必须对其做出贡献,而不仅仅是贡献给 OpenAI、Meta 或其他公司的专有系统。无论这听起来多么危险,这是未来的必然走向。
完整视频:http://www.youtube.com/watch?v=EGDG3hgPNp8
Reference
https://mp.weixin.qq.com/s/KcbNkABash79jv8dxBBHEw
https://www.deeplearning.ai/the-batch/issue-225

活水智能 致力于通过人工智能提高知识工作者的生产力,作为「AI时代的生产力专家」,我们的核心目标是为用户提供最先进的AI技术和工具,帮助用户更高效、更智能地完成工作。