前 言
在《231026 llama.cpp 极简》中,我介绍了使用 llama.cpp 来推理模型。如今,一个新的框架横空出世。MLX 是专为苹果芯片(即你的 MacBook 或 Mac Studio!)而设计的高效机器学习框架。在短短的一周时间里已经斩获了 8000 Stars。
MLX 与 PyTorch 的区别
MLX 和其他框架的一个显著区别对统一内存的原生支持。在 MLX 中,数组存在于共享内存中,比如对于下面这段代码。
a = mx.random.normal((100,))
b = mx.random.normal((100,))
mx.add(a, b, stream=mx.cpu)
mx.add(a, b, stream=mx.gpu)
变量 a 和 b 是没有副本的,虽然是在 cpu 和 gpu 这两个不同的设备上运行。而这个改进在 PyTorch 里较难实现。
MLX 的数组 API 与 Numpy 是一致的,有点像 Jax,这让调试变得十分容易。
框架总是越变越复杂,MLX 提供了一个很小的起点,对于想要探索新的想法的人,是一个很好的起点,比如对于没有丰富框架经验的研究者来说,通过 MLX 查询 Stack 是很容易的。同样,你也可以轻松地添加 Metal(GPU)内核来尝试新的优化。
案 例
使用苹果芯片微调与推理 Llama-7B 模型
在 https://github.com/ml-explore/mlx-examples/tree/main/lora 这个案例中,作者使用 M2 Ultra LoRA 微调 Llama-7B。使用的数据集是 WikiSQL 在使用 MLX 框架时模型 1s 能看 475 个 Tokens 这是个较为可观的速度。考虑到苹果芯片的功率远远低于 N 卡。
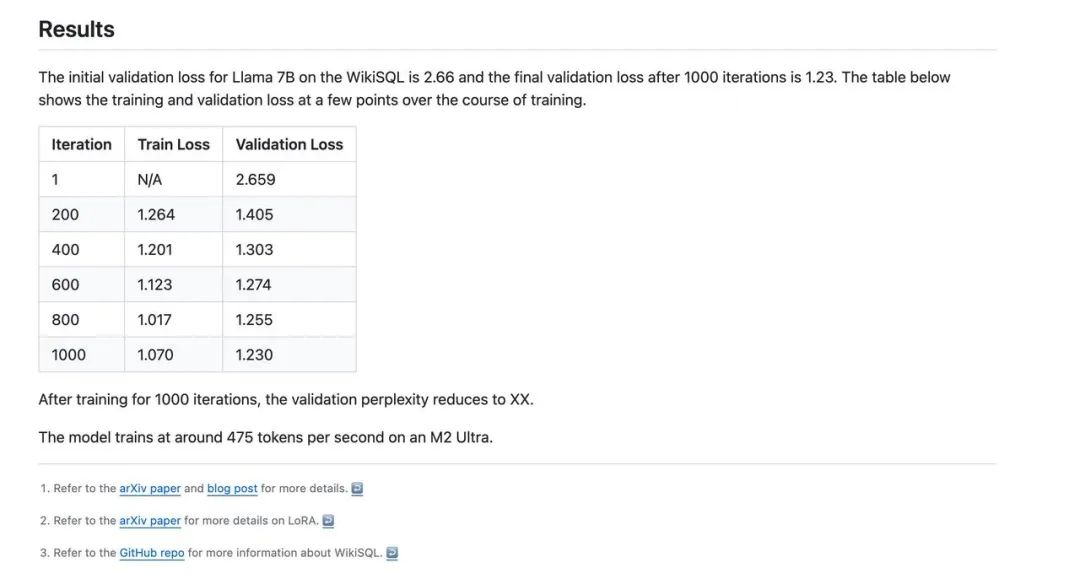
敝人也在第一时间使用了 M2 Max LoRA 微调 Llama-2-7B,此时:
-
1. 可训练的参数量为 2,090,000,大约为模型的 1%。
-
2. 使用 28m24s 分钟学习 426,000 个 Tokens。
-
3. 数据来源于 wikisql。
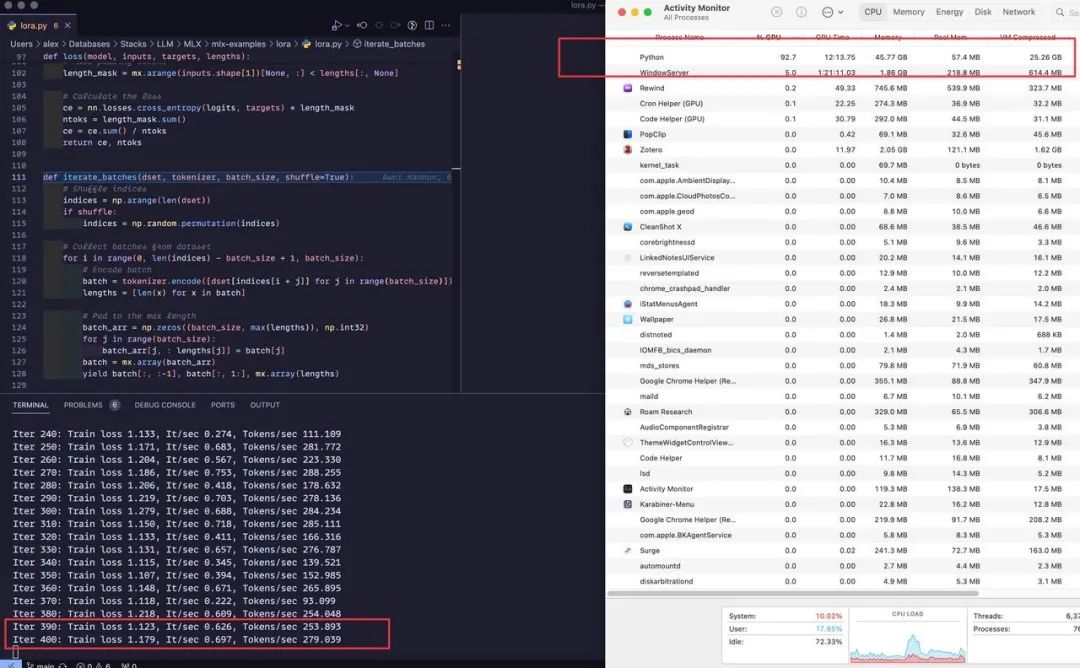
▲ 训练时的内存占用
Loading tokenizer
Loading pretrained model
Total parameters 6740.513M
Trainable parameters 2.097M
Loading datasets
Training
Iter 1: Val loss 2.631, Val took 87.426s
Iter 10: Train loss 2.570, It/sec 0.716, Tokens/sec 290.433
Iter 20: Train loss 2.515, It/sec 0.628, Tokens/sec 258.048
Iter 30: Train loss 2.506, It/sec 0.666, Tokens/sec 265.094
Iter 40: Train loss 2.396, It/sec 0.709, Tokens/sec 273.973
Iter 50: Train loss 2.107, It/sec 0.336, Tokens/sec 140.164
Iter 60: Train loss 1.891, It/sec 0.357, Tokens/sec 149.226
Iter 70: Train loss 1.765, It/sec 0.515, Tokens/sec 218.188
Iter 80: Train loss 1.633, It/sec 0.560, Tokens/sec 241.879
Iter 90: Train loss 1.659, It/sec 0.723, Tokens/sec 274.657
Iter 100: Train loss 1.464, It/sec 0.693, Tokens/sec 279.841
Iter 110: Train loss 1.458, It/sec 0.287, Tokens/sec 119.309
Iter 120: Train loss 1.430, It/sec 0.695, Tokens/sec 282.145
Iter 130: Train loss 1.351, It/sec 0.723, Tokens/sec 284.272
Iter 140: Train loss 1.296, It/sec 0.371, Tokens/sec 153.476
Iter 150: Train loss 1.289, It/sec 0.289, Tokens/sec 125.269
Iter 160: Train loss 1.227, It/sec 0.638, Tokens/sec 267.037
Iter 170: Train loss 1.297, It/sec 0.673, Tokens/sec 263.027
Iter 180: Train loss 1.260, It/sec 0.747, Tokens/sec 298.913
Iter 190: Train loss 1.301, It/sec 0.667, Tokens/sec 272.906
Iter 200: Train loss 1.208, It/sec 0.679, Tokens/sec 274.468
Iter 200: Val loss 1.367, Val took 89.204s
Iter 210: Train loss 1.253, It/sec 0.218, Tokens/sec 90.227
Iter 220: Train loss 1.252, It/sec 0.405, Tokens/sec 159.813
Iter 230: Train loss 1.209, It/sec 0.671, Tokens/sec 275.411
Iter 240: Train loss 1.133, It/sec 0.274, Tokens/sec 111.109
Iter 250: Train loss 1.171, It/sec 0.683, Tokens/sec 281.772
Iter 260: Train loss 1.204, It/sec 0.567, Tokens/sec 223.330
Iter 270: Train loss 1.186, It/sec 0.753, Tokens/sec 288.255
Iter 280: Train loss 1.206, It/sec 0.418, Tokens/sec 178.632
Iter 290: Train loss 1.219, It/sec 0.703, Tokens/sec 278.136
Iter 300: Train loss 1.279, It/sec 0.688, Tokens/sec 284.234
Iter 310: Train loss 1.150, It/sec 0.718, Tokens/sec 285.111
Iter 320: Train loss 1.133, It/sec 0.411, Tokens/sec 166.316
Iter 330: Train loss 1.131, It/sec 0.657, Tokens/sec 276.787
Iter 340: Train loss 1.115, It/sec 0.345, Tokens/sec 139.521
Iter 350: Train loss 1.107, It/sec 0.394, Tokens/sec 152.985
Iter 360: Train loss 1.148, It/sec 0.671, Tokens/sec 265.895
Iter 370: Train loss 1.118, It/sec 0.222, Tokens/sec 93.099
Iter 380: Train loss 1.218, It/sec 0.609, Tokens/sec 254.048
Iter 390: Train loss 1.123, It/sec 0.626, Tokens/sec 253.893
Iter 400: Train loss 1.179, It/sec 0.697, Tokens/sec 279.039
Iter 400: Val loss 1.269, Val took 84.119s
Iter 410: Train loss 1.111, It/sec 0.701, Tokens/sec 279.082
Iter 420: Train loss 1.123, It/sec 0.595, Tokens/sec 243.557
Iter 430: Train loss 1.113, It/sec 0.657, Tokens/sec 268.686
Iter 440: Train loss 1.046, It/sec 0.298, Tokens/sec 123.639
Iter 450: Train loss 1.034, It/sec 0.596, Tokens/sec 236.784
Iter 460: Train loss 1.096, It/sec 0.666, Tokens/sec 265.193
Iter 470: Train loss 1.197, It/sec 0.698, Tokens/sec 279.153
Iter 480: Train loss 1.087, It/sec 0.728, Tokens/sec 288.371
Iter 490: Train loss 1.040, It/sec 0.335, Tokens/sec 140.192
Iter 500: Train loss 1.052, It/sec 0.120, Tokens/sec 52.068
Iter 510: Train loss 1.094, It/sec 0.670, Tokens/sec 279.862
Iter 520: Train loss 1.084, It/sec 0.657, Tokens/sec 269.986
Iter 530: Train loss 1.113, It/sec 0.651, Tokens/sec 252.181
Iter 540: Train loss 1.111, It/sec 0.618, Tokens/sec 248.848
Iter 550: Train loss 1.181, It/sec 0.617, Tokens/sec 248.874
Iter 560: Train loss 1.162, It/sec 0.627, Tokens/sec 268.917
Iter 570: Train loss 1.111, It/sec 0.127, Tokens/sec 50.557
Iter 580: Train loss 1.189, It/sec 0.166, Tokens/sec 67.234
Iter 590: Train loss 1.075, It/sec 0.728, Tokens/sec 282.522
Iter 600: Train loss 1.100, It/sec 0.680, Tokens/sec 278.370
Iter 600: Val loss 1.232, Val took 85.148s
耗时 28m24s。
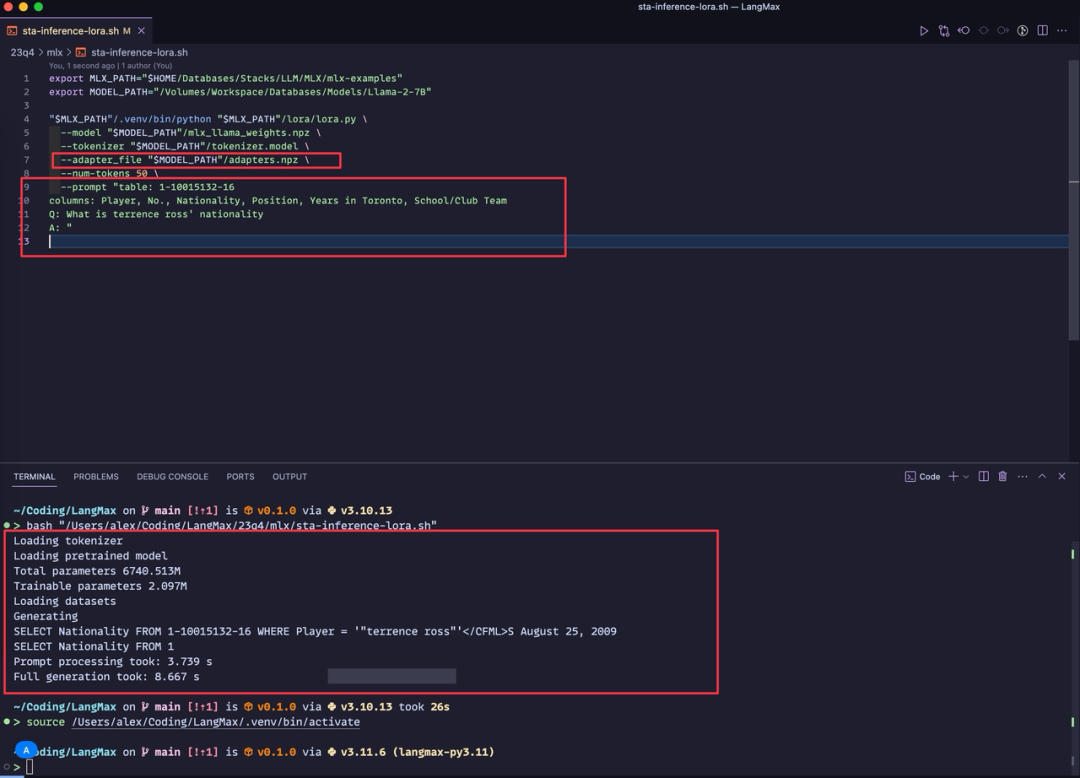
▲ 使用训练后的 Adapt 层来推理模型
在训练 28m 后可以使用自带的推理脚本来推理模型,如上图所示,模型已经部分学会了 SQL 语言。
下面的两个 Shell 脚本是使用官方的 lora.py 来训练与推理模型的教程,你需要的做的是:
-
1. 把官方的 mlx-examples 仓库克隆到本地。
-
2. 安装对应的 Python 依赖。
-
3. 下载并转换训练的模型为 npz 格式。
-
export MLX_PATH="" # 这里填写你克隆在本地的 https://github.com/ml-explore/mlx-examples/ export MODEL_PATH="" # 这里填写你下载并转换为 npz 格式的 llama 模型路径 python "$MLX_PATH"/lora/lora.py \ --model "$MODEL_PATH"/mlx_llama_weights.npz \ --tokenizer "$MODEL_PATH"/tokenizer.model \ --train \ --iters 600 \ --adapter_file "$MODEL_PATH"/adapters.npz export MLX_PATH="" # 这里填写你克隆在本地的 https://github.com/ml-explore/mlx-examples/ export MODEL_PATH="" # 这里填写你下载并转换为 npz 格式的 llama 模型路径 python "$MLX_PATH"/lora/lora.py \ --model "$MODEL_PATH"/mlx_llama_weights.npz \ --tokenizer "$MODEL_PATH"/tokenizer.model \ --adapter_file "$MODEL_PATH"/adapters.npz \ --num-tokens 50 \ --prompt "table: 1-10015132-16 columns: Player, No., Nationality, Position, Years in Toronto, School/Club Team Q: What is terrence ross' nationality A: "
使用苹果芯片推理 Mistral-7B 模型
备注一:Mistral-7B 是个开源模型。
备注二:非量化版本。
# 下载示例仓库
git clone https://github.com/ml-explore/mlx-examples.git && cd mlx-examples/mistral
# 此时记得开个 Python 虚拟环境
# 安装 Python 依赖
pip install -r requirements.txt
# 下载模型,大概 14gb 左右
curl -O https://files.mistral-7b-v0-1.mistral.ai/mistral-7B-v0.1.tar
# 解压缩模型与转换模型
tar -xf mistral-7B-v0.1.tar
python convert.py
# 推理模型
python mistral.py --prompt "It is a truth universally acknowledged," --temp 0
我的配置是 M2 Max 64g,初步测试,目前 MLX 原生没看到量化的推理,就只能和 llama.cpp 比较 F16 精度了,此时:
-
• llama.cpp 一秒钟大概 24 个 Tokens。
-
• MLX 一秒钟大概 30 个 Tokens。大概快 15-30%。
Stable Diffusion 图像生成性能
目前在 Batch size 为 1 的时候 PyTorch 会更加快,但在 Batch size 提高的时候,MLX 会胜过 PyTorch。下面的表格详细展示了性能对比。
| Batch size | PyTorch | MLX |
|---|---|---|
| 1 | 6.25 im/s | 4.17 im/s |
| 2 | 7.14 im/s | 5.88 im/s |
| 4 | 7.69 im/s | 7.14 im/s |
| 6 | 7.22 im/s | 8.00 im/s |
| 8 | 6.89 im/s | 8.42 im/s |
| 12 | 6.62 im/s | 8.51 im/s |
| 16 | 6.32 im/s | 8.79 im/s |
请注意,上表意味着使用 MLX 和无分类器引导的 50 个扩散步骤生成 16 张图像大约需要 90 秒,而使用 PyTorch 则需要大约 120 秒。
对于测试感兴趣的小伙伴可以参考 https://github.com/ml-explore/mlx- examples/tree/main/stable_diffusion。
Known Issues
M1 Max 不支持
Wing 尝试在 M1 Max 上进行操作,但这个 https://github.com/ml-explore/mlx/issues/20 似乎说了
M1Max 未能支持,直接 pip install mlx 也会报错,另外参考:https://ml-
explore.github.io/mlx/build/html/install.html。
直接执行 pip install mlx 可能会遇到:
ERROR: Could not find a version that satisfies the requirement mlx (from versions: none)
ERROR: No matching distribution found for mlx
MLX is only available on devices running MacOS >= 13.3 It is highly recommended to use MacOS 14 (Sonoma)
Reference
• https://twitter.com/awnihannun/status/1732184443451019431
• https://github.com/ml-explore/mlx
• https://github.com/ml-explore/mlx-examples
• https://github.com/ml-explore/mlx/issues/12