
在数据驱动的世界中,获取结构化数据并从中提取有价值的见解至关重要,尤其是在财务分析领域。资产负债表和其他财务报表中蕴含着丰富的信息,这些信息对于评估公司的财务健康状况和投资潜力至关重要。然而,这些报表通常是非结构化的,手动提取关键信息既费时又容易出错。
本文将展示如何利用Pydantic和AI大模型从非结构化数据中提取结构化财务数据,并以财务报表为例进行说明。这一过程可以帮助资产管理公司(AMCs)、经纪人和投资者更高效地分析财务数据,做出明智的决策。
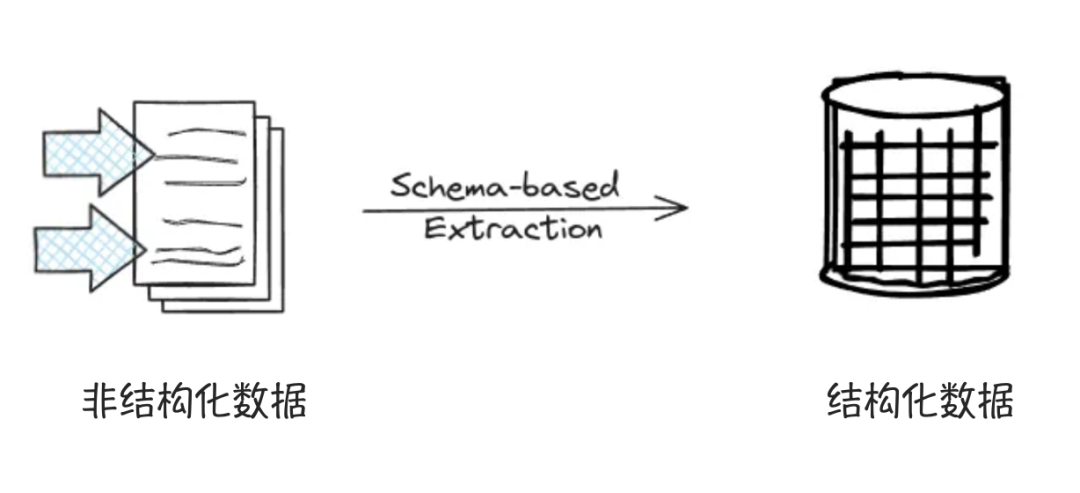
为什么选择结构化输出?
在基于检索增强生成(RAG)和大语言模型(LLM)的工作流程中,结构化输出不仅提高了数据的准确性和清晰度,还使数据更易于理解和分析。通过对公司发布的财务报告进行分析,投资者可以更好地了解公司的财务状况和未来规划,从而发现潜在的投资机会。
然而,财务报告通常以非结构化的形式存在,手动提取和整理这些信息不仅耗时,还容易出错。通过结构化数据的提取,可以大大简化这一过程,提高效率。
提取前的准备工作
基于模板的结构化数据提取
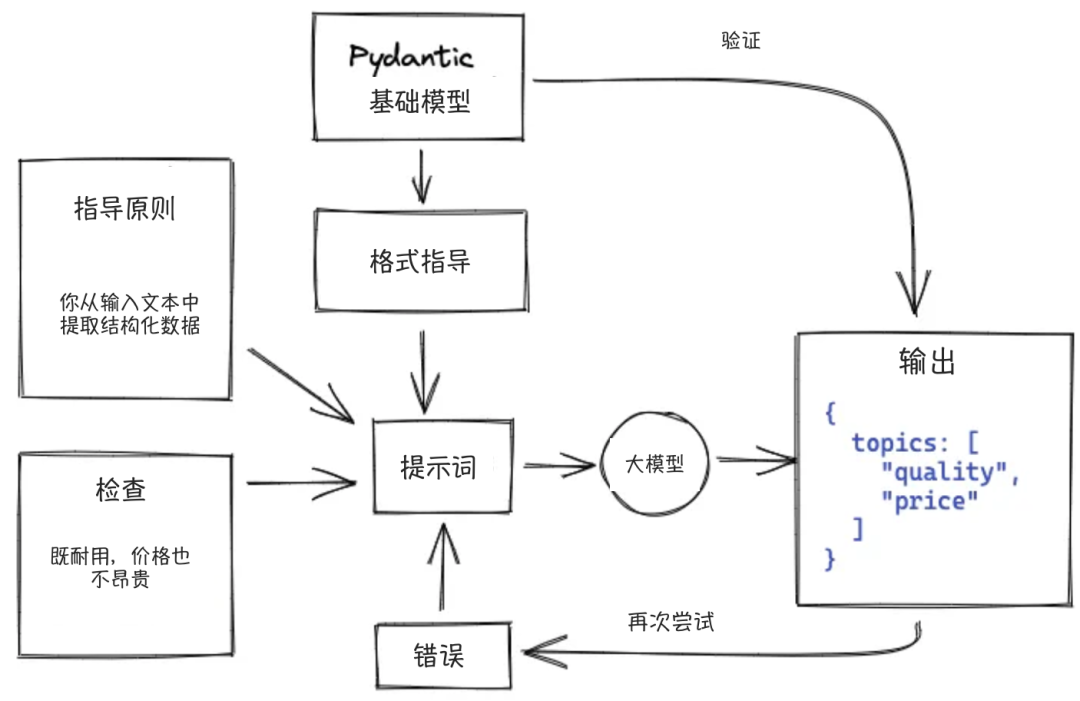
基于模板的提取方法相对简单,通过定义模式和属性类型,可以轻松利用Pydantic等工具进行数据提取。
为什么选择Pydantic?
- 简洁高效:Pydantic利用类型提示进行模式验证和提示,减少了代码编写量,并提供了更好的IDE集成。
- 高度可定制:Pydantic允许自定义验证器和错误信息,满足不同场景的需求。
- 广泛应用:Pydantic是Python中最受欢迎的数据验证库之一,月下载量超过1亿次,广泛应用于如FastAPI、Typer等流行框架。
关键组件
在从非结构化或半结构化数据中提取结构化数据时,以下组件至关重要:
- Pydantic BaseModel:这是提取流程的核心组件,准确命名并定义带有类型的属性是成功提取的关键。
- 提示词:提示词越详细和具体,得到的结果越好。通过定义一个Pydantic BaseModel,可以生成有效的提示词。
- 大语言模型(LLM):大模型根据提示词从文本中提取信息,并将其转换为JSON格式。选择合适的大模型可以显著提高提取结果的质量。
- 验证器:验证器确保大模型返回的结果准确无误。如果结果不正确,系统将报告错误并重新设计提示,重新进行提取过程。
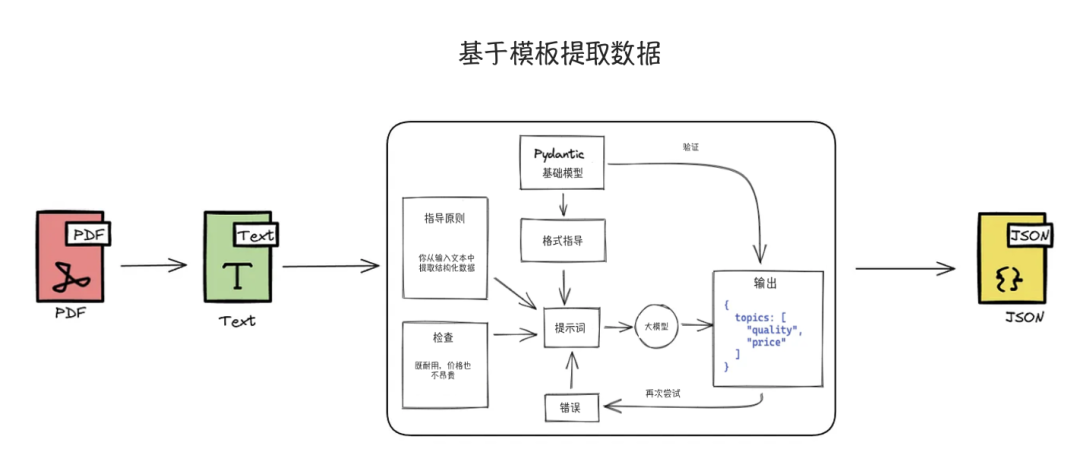
实施步骤
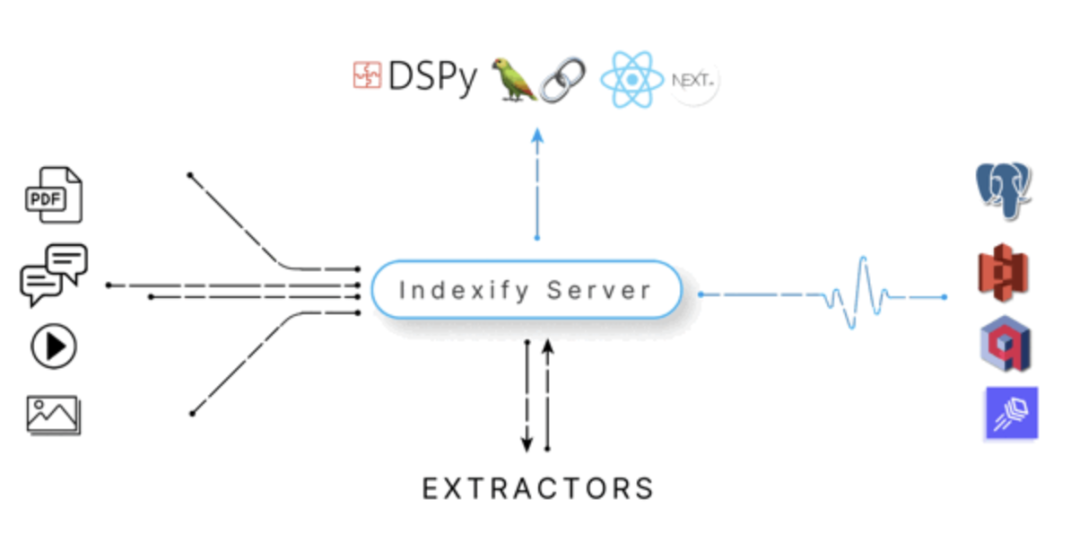
你无需从零开始,可以利用Tensorlake的Indexify框架来自动化提取关键数据。
Indexify是一个数据框架,专门用于构建非结构化数据的提取流程。通过声明式配置,Indexify可以在每个阶段使用AI大模型提取数据。一旦数据被提取,流程会立即开始运行,非常适合交互式应用和低延迟场景。
设置提取器
首先,安装必要的库并下载服务器和提取器:
pip install indexify indexify-extractor-sdk
curl https://getindexify.ai | sh
sudo apt-get install -y poppler-utils
indexify-extractor download tensorlake/chunk-extractor
indexify-extractor download tensorlake/minilm-l6
indexify-extractor download tensorlake/pdfextractor
indexify-extractor download tensorlake/marker
indexify-extractor download tensorlake/schema
安装完成后,重启运行环境,然后启动Indexify服务器。
打开两个新终端,分别运行以下命令:
终端1:
./indexify server -d
终端2:
indexify-extractor join-server
上传PDF并提取数据
将以下代码保存为 main.py,并下载你要处理的PDF文件:
from indexify_extractor_sdk import load_extractor, Content
from pydantic import BaseModel
# 初始化PDF提取器
pdfextractor, pdfconfig_cls = load_extractor("indexify_extractors.pdfextractor.pdf_extractor:PDFExtractor")
# 从PDF文件中提取内容
content = Content.from_file("BalanceSheet.pdf")
config = pdfconfig_cls()
pdf_result = pdfextractor.extract(content, config)
# 获取PDF中的文本内容
text_content = next(content.data.decode('utf-8') for content in pdf_result if content.content_type == 'text/plain')
# 定义数据模式
class Invoice(BaseModel):
year: int
capital_deposit: int
total_liability: int
total_assets: int
ratio_of_assets_by_liabilities: float
bills_collection: int
increase_in_deposits_from_2021_to_2022: float
schema = Invoice.model_json_schema()
client = IndexifyClient()
extraction_graph_spec = f"""
name: 'pdf_schema_extractor'
extraction_policies:
- extractor: 'tensorlake/marker'
name: 'pdf_to_text'
- extractor: 'tensorlake/schema'
name: 'text_to_schema'
input_params:
service: 'openai'
model_name: 'gpt-3.5-turbo'
key: 'YOUR_OPENAI_API_KEY'
schema_config: {schema}
additional_messages: '根据此模式提取 JSON 中的信息并仅返回输出。'
content_source: 'pdf_to_text'
"""
extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec)
result = client.create_extraction_graph(extraction_graph)
llm_content = next(content.data.decode("utf-8") for content in result if content.content_type == "text/plain")
# 输出所有提取的属性
print(llm_content)
将 YOUR_OPENAI_API_KEY 替换为你的实际API密钥。
激活虚拟环境并运行代码
激活由Indexify创建的默认虚拟环境来管理依赖项并防止包冲突:
source ~/.indexify-extractors/ve/bin/activate
然后运行包含上述代码的 main.py:
python3 main.py
输出结果将以结构化JSON格式显示,例如:
{
"year": 2022,
"total_income": 15592517400,
"total_liability": 20685350503,
"total_assets": 20685350503,
"ratio_of_assets_by_liabilities": 1,
"bills_collection": 569680463,
"increase_in_deposits_from_2021_to_2022": 2423670192
}
现在,你已经成功从PDF中提取了结构化数据,可以将这些数据通过API集成到数据库中进行进一步处理。
总结
本文展示了如何使用Pydantic和AI大模型从非结构化或半结构化文档中提取结构化数据。在示例中,我们展示了如何从PDF中提取财务数据,但同样的方法可以应用于其他类型的文档和数据源。
通过自动化提取流程,企业和投资者可以更高效地处理大量非结构化数据,从而做出更明智的决策。