
作者:Estampa
编译:活水智能
人工智能(AI)的广泛普及激发了人们的想象力。在这些技术日益成熟之际,探索它们与人类活动及更广泛领域之间的联系显得尤为重要。
是什么样的技术、机构和资源组合,使我们可以在线与AI对话,或在数秒之内获取图像?
本文从21个维度,绘制了人工智能技术与人类活动交织的复杂图景。以下为下篇。上篇请查看:生成式AI全景图(一)
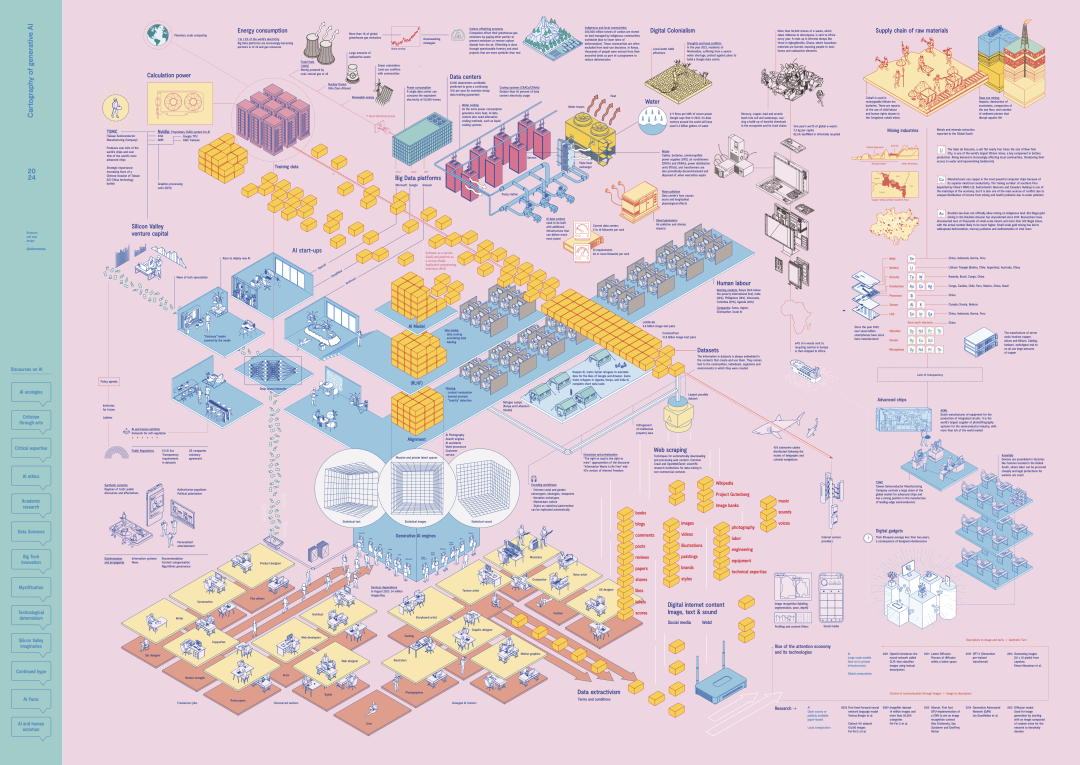
高清大图下载:https://cartography-of-generative-ai.net/genai_cartography.pdf
12. 能源(Energy)
自从生成式AI进入公众意识以来,对电力的需求前所未有。
近年来投资、应用和媒体报道的激增使得数据中心服务器的功率需求成倍增加。如今,一个数据中心的电力消耗量相当于50,000户家庭。
AI增加了能源依赖:三年前,一个服务器架消耗的电量为5-10千瓦,而今天专用于AI的服务器需要超过60千瓦。
这种突然的变化导致了设备投资和巨大的能源成本,因为目前增加的功率部分由柴油发电机提供(Pasek,2023)。
13. 化石燃料(Fossil fuels)
据估计,数据中心的电力消耗占全球总碳排放的0.3%,而当我们将笔记本电脑、智能手机和平板电脑等个人连接设备计算在内时,这一数字上升至全球碳排放的2%(Monserrate, 2022)。
在全球变暖的大背景下,计算基础设施的持续扩张——预计每年新增数据中心10%(Espinoza, Aronczyk, 2021)——在面对全球变暖和物种灭绝的未来挑战时显得难以为继。
数据中心消耗的电力大多来源于化石燃料。
尽管各大平台正努力减少排放,但减排似乎并非通过避免使用化石燃料实现(数字平台本身越来越多地与石油和天然气行业建立合作关系),而是通过利用碳抵消经济,即投资于往往象征性大于实际效果的林业或风能项目。
14. 碳补偿(Carbon offset)
许多碳补偿(Carbon offset)项目位于全球各地原住民社区管理的土地上,这些地区由于森林砍伐率低而吸引了投资者,因其具有再生能力。
然而,土地使用决策常常忽视了这些社区自身的利益,导致冲突或流离失所现象(Kramarz等,2021)。
此外,碳市场并未根本解决排放问题,反而推动了一种无限增长的幻想,将计算机行业的后果最小化,并将气候问题简化为买卖解决方案的交易。
同样,能源效率和可再生能源的投资也存在局限。大型太阳能和风能项目需要找到合适的场地,而这并非没有引发社区冲突。
如果要满足日益增长的计算需求,仅靠新的绿色电力项目是不足以实现脱碳的。更根本的是,它们无法支撑新兴AI平台预期的计算负荷。
这一事实并未被CEO们忽视,他们已开始投资于核裂变产业。大型生成式AI模型的发展需要更多的计算能力和更多的能源供应。与此同时,全球计算的碳足迹已经超过了航空业。
15. 热能(Heat)
AI的环境足迹不仅仅局限于碳排放。数字行业在运行过程中不可避免地产生热量。
处理数字内容会使数据中心内服务器机架所在房间的温度升高。如果不加以控制,过度的热量会威胁到设备的正常运行。
因此,必须不断地降低这些设备的温度。为了控制这一热力学威胁,数据中心依赖于空调——这些设备消耗的电力超过了中心总电力的40%(Weng等,2021)。
但这还不够:随着适应AI所需的额外功耗产生更多热量,数据中心还需要采用替代冷却方法,如液体冷却系统。
服务器通过连接到输送冷水的管道,该水从大型邻近站点抽取并返回水塔,水塔利用大型风扇散热并吸入新鲜水。

据谷歌称,这种水消耗量每千瓦时服务器功率为4至9升。对于通常比许多同行更关注可持续性的平台来说,这是一个相当大的数量。
公司数据中心的水消耗量在过去四年中增加了60%以上,这一增长与生成式AI的兴起相平行。
16. 水资源(Water)
新数据中心的建设对当地水资源造成压力,并加剧了气候变化引起的水资源短缺问题。
干旱影响特别缺水地区的地下水位,当地社区与平台的利益之间开始出现冲突。2023年,蒙得维的亚居民因水资源短缺而对建设谷歌数据中心的计划进行了一系列抗议。
面对高消耗的争议,微软、Meta、亚马逊和谷歌的公关团队承诺到2030年实现水循环,这一承诺基于一方面的封闭循环系统投资,另一方面是从其他地方回收水以补偿冷却系统中不可避免的消耗和蒸发。
17. 废物(Waste)
在数据中心,空调、变压器、电池或电源在保修期满时定期拆除并处置。
然后,拆卸的设备被列入电子废物清单。这些废物难以回收,尽管欧洲有一些地方性的倡议,但至少在高性能计算领域很少被再利用。
随着全球人均拥有超过三台设备,平均使用寿命不到两年,对最新创新或升级的追求意味着不断产生废物。
我们目前每人每年平均产生7.3公斤电子废物,其中82.6%最终被填埋或非正式回收(Forti等,2020)。
电子废物中所含原材料的回收是一个高度不受监管的市场,基于对第三国的出口(欧洲回收中心的64%电子废物被运往非洲)。
18. 化石废弃物(Fossils)
每年数万吨的电子废物需要数千年才能分解,最终被丢弃在像加纳的非正式垃圾场,那里的有害物质被焚烧,使靠回收生存的人们暴露在有毒烟雾和放射性元素中。
汞、铜、铅和砷渗入土壤和水道,将有害化学物质积累在生态系统及其食物链中。尽管人们的意识逐渐增强,新的法规逐步引入,但数字行业的废物是我们化石遗产最明显的标志之一。
如何将投资于计算设备的资源、矿物、金属和能源最终形成特定的沉积物,这将在深层地质时代中持续存在。

19. 美学转向(Aesthetic turn)
所有这些基础设施、提取、转化、投资、外部化、计算、统计模型和劳动市场的相互关联,最终塑造了所谓的生成式AI。
这是一个社会技术现象,它源于将概率作为认识论模型的主导地位,以应对当前的挑战。这些统计工具在越来越多的人类活动领域的应用,近年来已经采取了特定的转向。
最初,它们主要用于追踪、提取和分析网络通信内容,现在这种分析开始被用来合成通信的形式本身。
从这个意义上说,生成式AI现象可以被理解为一种美学转向。
如果模仿人类认知能力的追求一直驱动着机器学习研究,那么这种美学转向已将研究引向更具人类表达和创造力特征的领域。这一研究轨迹在近几年已经以多种方式发生了变异。
20. 规模(Scale)
总的来说,生成式AI研究已从学术和科学领域转向工业,并引发了一波投机。
在此过程中,触发了几个规模的变化。
首先是算力规模的变化。从2012年Alexnet项目首次使用GPU赢得图像识别比赛,到2024年Nvidia宣布将最新一代GPU的产量增加到200万台,这是一个影响并涉及上述整个供应链的规模变化。
其次,数据集的规模也发生了变化。虽然大型平台现在似乎对小规模模型的功能性更感兴趣,但近年来的重点一直是通用任务自动化。这意味着除了处理大型数据集外,该数据集还必须包含大量记录的多样性。
为了实现这种多样性,模型必须通过爬取和处理无法计量的网络可访问内容来训练。与这些规模变化并行的是,工具和知识在该领域的私有化程度增加。
大多数AI工具是开源的,但即使那些不是开源的工具也通常基于公开可用的学术论文,因此迟早会有人制作一个免费版本。
随着模型越来越大,研究人员的进入壁垒变得更难以克服。
当GPT-2文本生成模型,ChatGPT的前身出现时,任何拥有必要知识和适度强大计算机的人都可以下载网络到他们的计算机上,并用自己的数据集进行训练。
下一代模型,即参数和容量更高的GPT-3模型,现在只作为一个封闭模型提供,限于在平台的服务器上训练。
这一范式转变标志着这些工具在近年来的巩固和接受,以及用户界面和基于订阅的支付系统的推广。
初创公司与微软、谷歌和亚马逊等平台之间的商业协议意味着,在几年内生成式AI技术将成为基础设施,在前所未有的指数级升级中,真正生成的不是它们提供的合成内容,而是每次新更新带来的设备、辅助产业和环境影响的生成。
21. 多维关系图(Counter-mapping)
这里呈现的关系集合形成了一个难以把握的马赛克,因为它涉及不同种类和规模的对象和知识的链接。
围绕AI的话语往往带有强烈的神话色彩,伴随着一系列反复出现的隐喻和想象:脱离人类行动的算法机构、强加给我们未来的不可协商技术、数据的普遍性,或者生产无偏见或世界观模型的能力。
围绕这些技术的一系列话语,无论是更专业的还是更流行的,最终以某种方式塑造了它们。
《生成式AI全景图》项目的动机是提供一个概念地图,涵盖我们称之为生成式AI的这个复杂而多面的对象所涉及的大部分参与者和资源。
借鉴致力于夺取地图作为霸权真理制造者功能的批判性制图学的悠久谱系,这种可视化旨在绘制这一现象,考虑到使其成为可能的紧张、争议和生态系统。