
作者:Estampa
编译:活水智能
人工智能(AI)的广泛普及激发了人们的想象力。在这些技术日益成熟之际,探索它们与人类活动及更广泛领域之间的联系显得尤为重要。
是什么样的技术、机构和资源组合,使我们可以在线与AI对话,或在数秒之内获取图像?
本文从21个维度,绘制了人工智能技术与人类活动交织的复杂图景。以下为上篇。
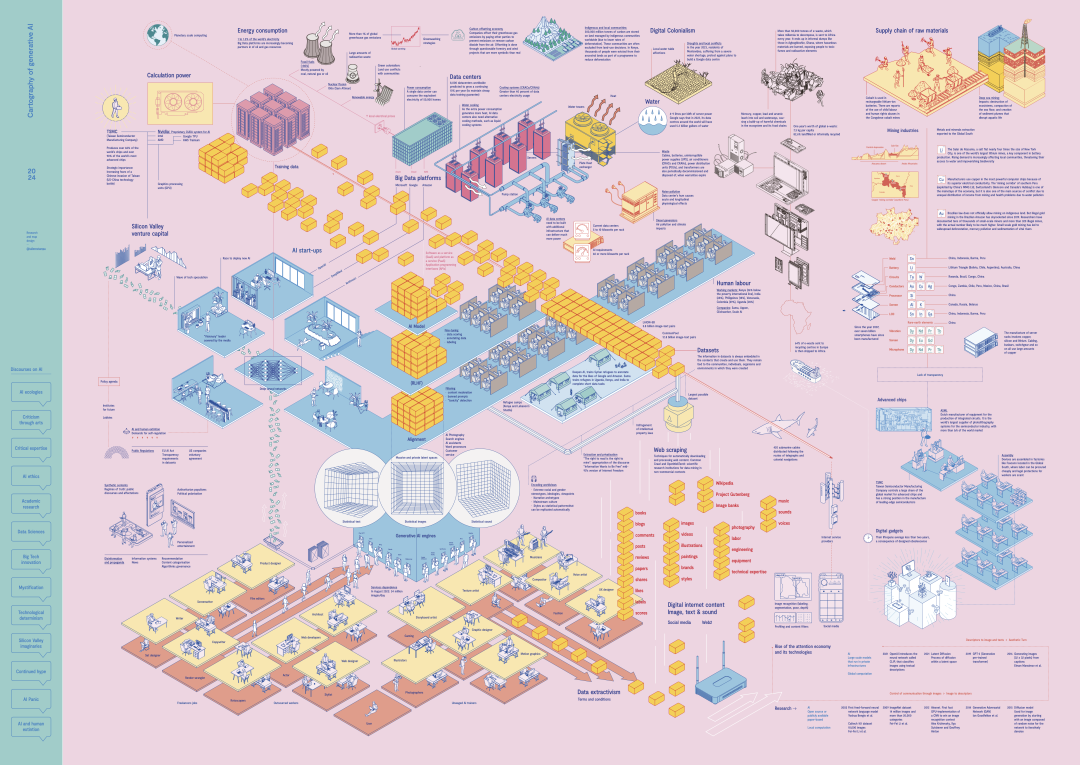
高清大图下载:https://cartography-of-generative-ai.net/genai_cartography.pdf
01. 生成式AI(Generative AI)
生成式AI工具被用来自动化诸如写作或生成图像等任务。
这种自动化并非通过编程步来实现,而是依赖于示例。如果我们有大量案例,就可以利用统计网络处理,这些网络通过分析反复出现的模式自我配置。
无论是处理文字、像素还是声音,我们都能通过分析和探索训练数据集来构建一个统计模型。
可以说,生成式AI工具通过计算概率,将语言(无论是视觉的还是文本的)解构后重新组合。
从最初被训练用于生成具体表达(如一张脸的图像、特定风格的文本),到现在能够超越这种具体性,生成多种类型和风格的内容,这种泛化能力基于处理更大、更多样化的数据集,以应对各种提示。
因此,生成式AI的变革规模之大,已经推动了新经济的发展,并加速了对生态系统的依赖。
02. 数据集(Datasets)
通过从互联网这个最大数字档案库中提取内容,实现了训练数据集的工业级编译。通过自动化“抓取”数百万互联网用户发布和共享的在线内容获得。
这种提取的最初动机并非为了今天的商业开发,而是出于学术和非商业研究的愿望。现在,这些庞大的数字档案库被用来按需生成文本和图像,我们因此面临文化产业内的一系列悖论和争议。
一方面,大数据意识形态将互联网内容视为可以被提取、处理和自动化的巨大资源库;另一方面,这种提取行为被其他文化参与者视为对数百万互联网用户创造力的大规模私有化。
03. AI模型(Statistical imitation models)
文化产业生产了许多供AI模型使用的图像、文本和声音,并反过来成为它们的主要和潜在用户。
摄影师、设计师、插画家、音乐家、作曲家、编剧、作家、开发人员、动画师和电影制作人的作品正在被用来训练这些AI模型。
尽管目前生成内容的美学与现有的图像库、照片库或声音库相似,但这些自动化服务的运作速度是任何人类竞争者无法比拟的。
因此,文化生产中最具社交性和最不稳定的工作将成为最受影响和最依赖生成式AI的领域。
04. 微调(Fine-tuning)
尽管数据集是原材料,但它们本身不足以精炼出当前在线AI服务所提供的个性化互动水平。
为了提升用户体验,需要一小部分微工作者来精炼模型:评分它生成的答案、标记图像或文本、进行注释和其他涉及认知劳动的评估过程。
大型企业将这些就业服务外包给第三方公司,这些公司又将它们转移到全球南部贫困率高的国家,使每个工人的成本/小时成为微不足道的费用。
一些外包公司已被记录在难民营中运营,训练黎巴嫩、乌干达、肯尼亚和印度的流离失所者执行与数据相关的微任务,利用这些人的经济困境。
05. 内容审查(Filtering)
在后期,有必要过滤大型AI模型生成的内容。这一阶段最常见的任务是针对所谓的有害内容进行审查:仇恨、政治争议、极端或明显的性和暴力,这些内容最初包含在训练数据集中。
在肯尼亚或乌干达等国家的劳动力市场(甚至在北方的大都市中,包括移民社区)开展的审查工作,致力于识别和分类带有暴力、谋杀、强奸或虐待儿童内容的文本和图像。
因此,在AI工具的自主外观背后,我们发现不同层次的人力资源被转移到不同的地理位置,被技术创新产业边缘化和隐形化。
06. AI初创公司(AI start-ups)
这些外包人力资源项目,依赖于生成式AI初创公司(OpenAI、DeepMind、Anthropic等),这些公司得益于AI模型的价值和硅谷科技投机的新浪潮。
生成式AI初创公司围绕专业知识和专门研究建立,但也作为全球参与者,协调这些微劳动市场,与大型平台计算结盟,并吸引金融资本。
它们是当前全球数字创新市场热潮的明星,弥补了科技风险资本利润增长的放缓,并得益于一种便利的论述,即将AI辩论的焦点放在其对人类灭绝的潜在威胁上。

07. 公共话语(Public discourses)
由研究所和慈善基金会推动、初创公司“有远见”的领导者支持的AI恐慌话语,通过媒体传播,并在公众舆论中产生了预期的警示效果。
在这些技术首次接受监管程序(欧洲议会在2024年初通过了第一部AI法律)之际,挑动存在威胁信息的目的是为了支持AI产业对公共管理的自我调节要求。
与此同时,在后真相一词定义的标准化信誉危机背景下,社交网络已经充斥着这些工具生成的合成消息、图像或文本。
在不断增长的错误信息和政治极化背景下,公共话语的自动化及其影响将成为未来几年媒体议程的核心。
08. 计算能力(Computing)
年轻的AI产业的出现离不开与大数据浪潮的平台(微软、谷歌、亚马逊、Meta等)的联盟。
这些技术巨头在提取和商业化在线服务用户数据的基础上建立了经济霸权,现在拥有全球规模的计算基础设施。
在它们的数据中心,处理从网络提取的大量图像、文本和声音。
这是一项只能由专业超级计算机处理的任务:大量专用服务器集中工作,全天候训练AI模型的最新更新,其规模比之前的版本大得多。
09. 算力(Calculation power)
这些基础设施的核心是关键设备:图形处理单元(GPU)。

它们提供了加速机器学习工作负载所需的计算能力——十年前的AI研究在对图形卡的需求中找到了这种能力,以满足要求苛刻的视频游戏行业。
这些设备掌握在少数几家公司手中,它们在全球享有近乎垄断地位(尤其是Nvidia,它巩固了自己的专有系统)。
它们的生产外包给了更为集中的半导体市场:台湾半导体制造公司(TSMC)生产了90%的最先进芯片,并依赖荷兰公司ASML的光刻印刷设备。
这个工业集团最终为全球8000多个数据中心制造核心服务器组件。
10. 芯片(Chips)
半导体芯片是驱动服务器和用于信息共享的移动设备的核心,连同电池、电源、配电单元以及其他电子组件,它们是一连串复杂投资、生产和设备整合过程的成果。
但合成微小集成电路以及电池、电源、配电单元和其他电子设备组件需要大量金属、矿物和其他原材料。
专门研究数字媒体物质性的Jennifer Gabrys教授分析了制造微芯片所使用的资源量:“生产一个两克的存储器微芯片,需要1.3公斤的化石燃料和材料。
在这个过程中,用于制造微芯片的材料只有一小部分实际包含在最终产品中,多达99%的材料在生产过程中被丢弃。
这些被丢弃的材料中许多是化学品——污染性的、惰性的,甚至是毒性未知的。”(Gabrys,2011)。
将技术创新的洁净室与这些矿物的提取联系起来的供应链,被一层方便的不透明面纱所掩盖,这得益于那些不证明其工作材料来源的公司和中间供应商。
11. 采矿业(mining industry)
采矿业为主要数字硬件制造商供货,遍布全球各地,主要集中在全球南部的国家。
I.
制造商因其更高的电导率而在最强大的芯片中使用铜。铜矿的一个极点可以在南美洲太平洋沿岸的国家找到,主要是智利和秘鲁。
在秘鲁南部是所谓的“采矿走廊”(由中国公司MMG Ltd、瑞士公司Glencore和加拿大公司Hubbay开采)。
在秘鲁,矿产出口是经济的支柱之一,但也是由于矿产收入分配不均和当地居民因水污染导致的健康问题而成为主要冲突来源之一。
II.
另一种受工业青睐的导电材料是黄金。它被用于智能手机、计算机和服务器的生产,主要技术平台的供应链部分从巴西进口黄金,其中28%的提取是非法的。
尽管巴西法律官方不允许在土著土地上采矿,但自2019年以来,巴西亚马逊的非法黄金采矿活动激增。
研究人员已记录了数以万计的小规模矿工和320多个非法矿场,实际数量可能更高。
小规模黄金采矿导致了大面积的森林砍伐和高水平的汞污染(Manzolli,2021)。
III.
电池生产依赖于一个关键组成部分:锂。智利是这种抢手矿物的世界领先生产国之一。阿塔卡马盐湖,一个几乎是圣地亚哥-德智利四倍大小的地区,是世界上最大的锂矿之一。
不断增长的需求日益影响当地社区,威胁他们的用水权,并贫化该地区独特的生物多样性。
IV.
锂电池的生产还需要钴,世界上近一半的钴储备集中在非洲,主要在刚果的军事化矿山中,那里有使用童工和侵犯最基本人权的证据。
在所有这些案例中,重复的模式是:外国公司与当地精英就土地开发进行谈判,忽视了当地社区的利益。
从这个意义上说,我们可以理解私人超级计算产业是如何建立在全球南方国家资源提取的殖民基础上的。
关注我,用AI提升生产力🌟
每周末赠送AI相关好书
推荐阅读
• 利用AI大模型,将任何文本语料转化为知识图谱,可本地运行!