作者:myscale
来源:https://myscale.com/blog/how-does-retrieval-augmented-generation-system-
work/
本文我们将了解检索增强生成(RAG)系统是如何工作的。
大模型(大模型s)革新了自然语言处理(NLP)领域,开创了与技术交互的新方式。GPT和BERT等先进模型开启了语义理解的新纪元,使计算机能够处理和生成类似人类的文本,架起了人机交流的桥梁。
大模型正广泛应用在情感分析、机器翻译、问答、文本摘要、聊天机器人、虚拟助手等领域。
尽管大模型在实际应用中表现出色,但也面临一些挑战。它们被设计为通用模型,可能缺乏特定性。此外,由于它们是基于过去的数据进行训练,不能提供最新信息。
这可能导致大模型生成错误或过时的响应,产生”幻觉”——即模型因训练数据的局限而生成错误或不可预测的信息。
检索增强生成(RAG)系统通过解决特定性不足和实时更新等问题,为可靠地部署大模型提供了潜在解决方案。
什么是RAG
2020年,Meta研究人员提出了检索增强生成(RAG),将大模型的自然语言生成(NLG)能力与信息检索(IR)组件相结合,以优化输出。
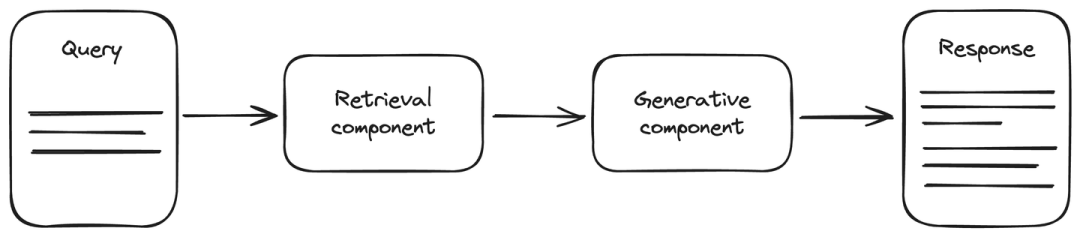
RAG在响应查询前,会参考训练数据以外的可靠知识源。你无需重新训练模型即可扩展大模型的能力。这提供了一种经济高效的方法,以增强输出的相关性、准确性和在各种情境下的可用性。
RAG架构包含一个最新的数据源,以提高生成式AI任务的准确性。它由两个主要组件构成:检索 和生成 组件。检索组件连接到一个数据源(通常是向量数据库),用于检索与查询相关信息。这些信息与查询一起提供给生成组件。生成组件是一个大模型,用于生成相应的响应。RAG提高了大模型的能力,让生成的响应更加准确和及时。
如何设置RAG系统的检索组件
首先,你需要收集应用所需的所有数据,并且剔除无关数据。将收集到的数据划分为易于管理的小块,并使用嵌入模型将这些数据用向量表示。向量用数值表示,语义相似的内容在向量空间中更接近 。这使系统能够理解用户想查询的信息,并与数据源中的相关信息匹配。
将向量存储在向量数据库中,并将源数据块与其嵌入关联,有助于检索与用户查询相似的向量对应的数据块。
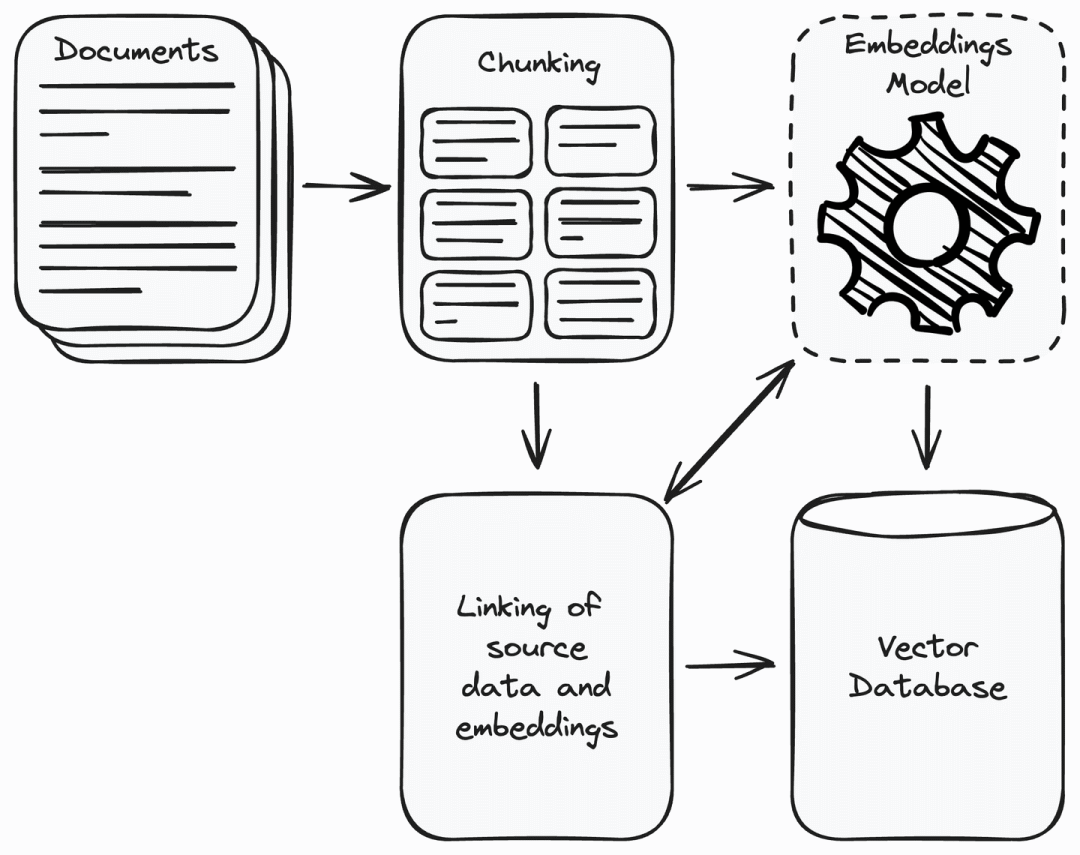
RAG系统如何工作
设置好检索组件后,我们就可以在RAG系统中使用它了。为了响应用户查询,我们可以用它检索相关信息,并在将查询传递给语言模型生成响应之前,将这些信息作为上下文附加到查询中。
下面我们了解下如何使用检索组件获取相关信息。
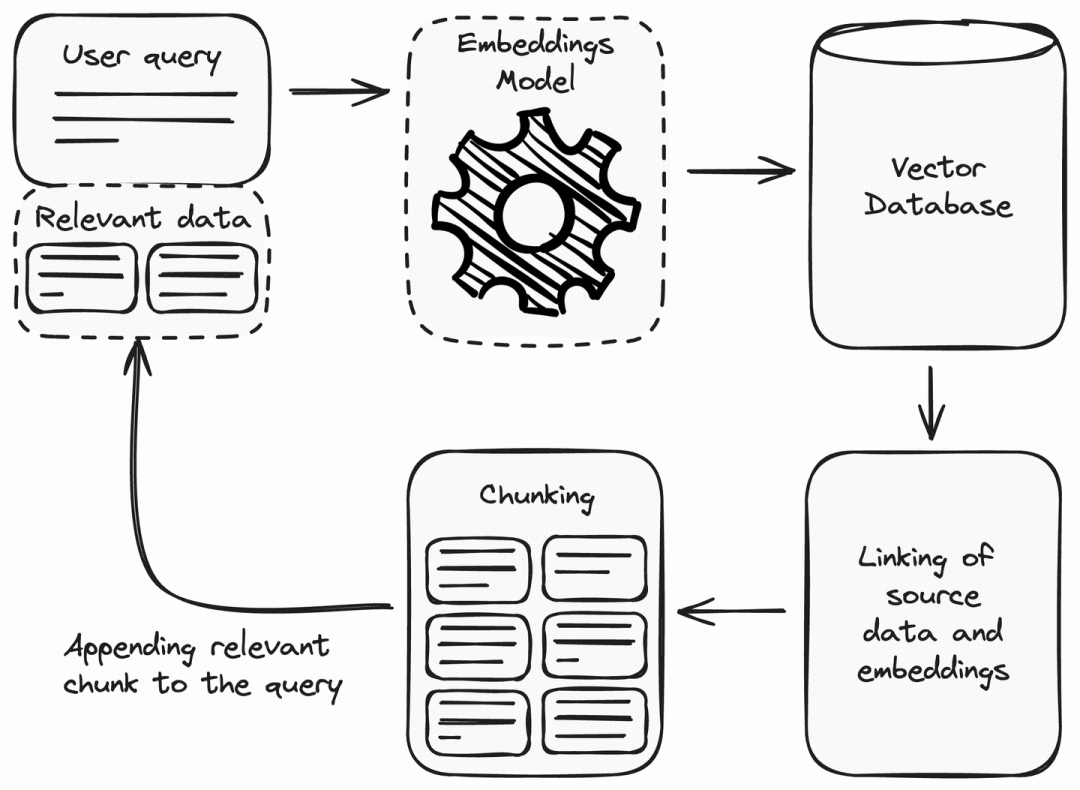
向查询添加相关信息
收到用户查询后,首先要将其转换为嵌入或向量表示。使用设置检索组件时,将数据源转换为嵌入的同一嵌入模型 。将用户查询用向量表示后,使用欧几里得距离或余弦相似度等度量方法,从向量数据库中查找相似的向量。利用这些向量检索相关数据块,并将其附加到用户查询中。
用大模型生成响应
现在我们有了查询和相关的信息块。接下来将用户查询连同从检索组件获得的数据,一起提供给大模型(生成组件)。大模型能够理解用户查询并处理提供的数据,根据从检索组件收到的信息,生成对用户查询的响应。
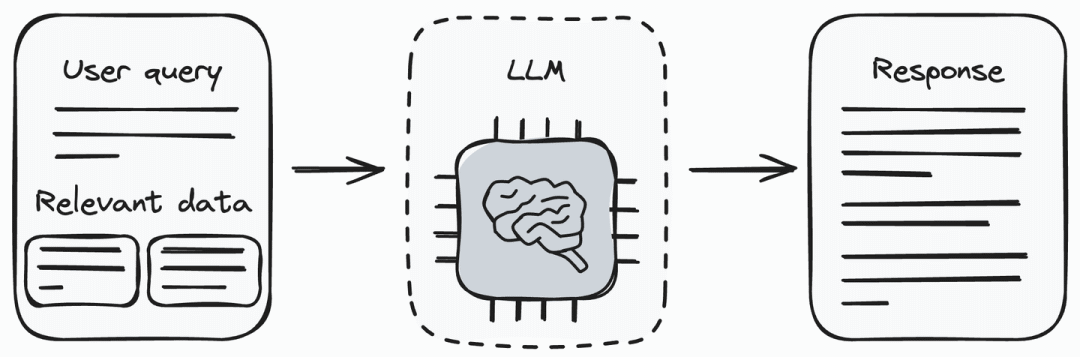
将相关信息与用户查询一起传递给大模型,是消除大模型幻觉问题的一种方法。现在,大模型可以利用我们与用户查询一起传递的信息来生成响应。
注意 :请记住定期使用最新信息更新数据库,以确保模型的准确性。
RAG的一些应用场景
RAG系统可用于需要精确和检索上下文相关信息的各种应用。作用是提高生成响应的准确性、及时性和可靠性。以下是RAG系统的一些应用:
在特定领域的提问。当RAG系统面对特定领域的问题时,它利用检索组件动态访问外部知识源、数据库或特定领域的文档。这使RAG系统能够生成上下文相关的响应,反映指定领域内最新最准确的信息。这在医疗保健、法律解释、历史研究、技术故障排除等领域都很有帮助。
事实准确性。要求生成的内容和经过验证的数据保持一致,如新闻报道、教育以及任何要求信息可靠性和可信度的场景中,非常有帮助。在可能出现错误信息的情况下,RAG会优先考虑事实,提供与主题相符的信息。
研究查询。RAG系统通过动态检索其知识库中的最新相关信息,在处理研究性查询时很有价值。例如,当研究人员要获取特定科学领域最新进展时,RAG系统可以利用其检索组件访问最新的研究论文、出版物和相关数据,确保研究人员获得最新见解。
构建RAG系统的挑战
尽管RAG系统有很多优势,但也有局限。让我们列举如下:
在集成上,将检索组件与基于大模型的生成组件集成可能很困难。处理不同格式的多个数据源时,复杂性会增加。在将检索组件与生成组件集成之前,请确保使用单独的模块在所有数据源上保持一致性。
在数据质量方面,RAG系统依赖于外部知识库。低质量内容、在多个知识库中使用不同嵌入方式或数据格式不一致等,都可能导致RAG系统质量下降。请务必确保数据质量。
在可扩展性方面,随着外部数据量的增加,RAG系统的性能会受到影响。例如,将数据转换成嵌入表示、比较不同数据块之间的相似性,以及执行实时检索等任务,对计算资源的要求很高。这可能会导致RAG系统的处理速度变慢。
为解决这个问题,您可以使用MyScale,它在LAION 5M数据集上提供390 QPS(每秒查询数)、95%的召回率和17ms的平均查询延迟,有效地提高了系统的扩展性和响应速度。
结 论
RAG是通过将知识库附加到大模型,以提升大模型能力的技术。你可以将其理解为具有语言生成能力的搜索引擎。这些系统无需任何重新训练或微调成本,就能缓解大模型的幻觉问题。
在响应用户查询时使用外部数据源,尤其是在处理客观事实、最新或定期更新的数据时,可以提供更准确和及时的响应。尽管RAG系统有很多优点,但也有自身的局限性。
MyScale等向量数据库公司,为大规模、复杂的RAG应用提供了解决方案。这些数据库专为AI应用设计,考虑了成本、可扩展性在内的所有因素。此外,还可以与LangChain和LlamaIndex等AI框架集成。