作者:Hugo Lu
来源:https://medium.com/towards-data-science/how-i-use-gen-ai-as-a-data- engineer-6a686a921c7b
生成式AI(Generative AI,GenAI)目前成为了业界的热门话题。本文我们将深入探讨一些数据工程师可以实际应用的具体案例。
引言
将生成式AI整合到数据工程的工作流程和数据管道中,效果是非常直接和令人满意的。
数据团队是软件与用户之间的纽带,拥有独特的优势——能够快速迭代生成式AI的应用案例,从而对业务产生显著的影响。
具体而言,生成式AI能够对大量的结构化和非结构化数据进行总结,这不仅扩大了数据团队的数据量,同时也加深了对数据的理解。
然而,人们很容易陷入对生成式AI的迷恋,觉得它“很酷”或者“很时髦”,忽略了其实际应用价值,没有将其用于推动组织业绩增长。
这也是为什么数据团队拥有一个集中的数据和AI产品的可视化平台至关重要。
本文将讨论几种在现有数据管道中利用生成式AI的方法,并探讨如何量化这些方法的成效。
特征工程
数据团队现在可以通过调用API,获取大量非结构化数据,如通话记录或支付票据,并清洗数据。
这一过程可以在数据获取或数据处理阶段进行。例如,如果你正在使用开源连接器 从Salesforce中获取数据,你可以遍历“备注”列,并调用Open AI总结这些备注。
以下是代码示例,展示了如何使用生成式AI进行特征工程:
1. def fetch_data():
2. return pd.DataFrame({'notes': ['some_data']})
3.
4. def make_call_to_open_ai(data):
5. data['completed_notes'] = open_ai.make_request(data['notes'])
6. return data
7.
8. data = fetch_data()
9. feature_engineered_data = make_call_to_open_ai(data)
数据转换过程中,可以通过Python脚本临时处理并提交一系列数值。
这通常需要协调Python作业和数据转换任务(如使用dbt或Coalesce进行查询),这可能相当复杂。
幸运的是,许多云数据仓库平台已经集成了生成式AI。例如,Snowflake的SQL支持SUMMARIZE()等函数,这些函数可以在后台自动完成上述工作。
新数据源——非结构化数据
如果你能将PDF、文档和电子邮件等非结构化数据存储到对象存储层(如Amazon S3),你可以实时利用这些数据。
例如,可以使用数据获取工具将电子邮件同步到S3(类似于使用Fivetran将Salesforce的数据导入Snowflake)。然后,使用Snowflake提炼PDF摘要,帮你更好地理解获取到的数据。
假设你有一个客户合同列表,存储在一个特定的文件路径下,你可以通过Document AI自动提取这些合同的关键信息。
这对于分析客户合同和订单表格将非常有用。你可以轻松推断出一个模式,如下所示:
1. {
2. "contract_type": "annual",
3. "products": ["Platform", "Dashboard"],
4. "platform_fees": ["$10,000", "$20,000"]
5. }
这简化了操作工具(例如Docusign和Salesforce)之间复杂集成的过程。
理想情况下,它可以节省财务团队数百小时的手动工作——这是一个立即可见、可量化的成果(“每周节省了10小时 = 每周$500 = 每年$25,000”)。
新的数据源与其他数据流程的逻辑分离,让监控变得更加简单。这在使用单体方法时可能非常具有挑战性。
数据抓取
团队可以使用Orchestra和Nimble等平台,将互联网作为数据源。生成式AI非常擅长从网页文件中提取重要信息。
记住,像Selenium和Beautiful Soup这样的工具分别在2006年和2004年就已经存在了。
有些公共网站的数据源是开放的,例如Google。想象一下,如果你能实时监控不同搜索词的频率,而不必支付高昂的费用。
其他应用包括从供应商网站获取定价数据、天气数据或企业名录。只要在服务条款内使用这些工具(这一点非常重要),你获取互联网数据的能力将会变得很强大。
Nimble的登录页面——当我了解到这个时非常兴奋。作为一个数据工程师,谁不想使用互联网数据源呢?
值得注意的是,网络抓取数据消耗的计算机资源有限但耗时很长。因此在昂贵的计算机集群上运行这些程序,是不明智的。
一个好的解决方案是使用编排层,并将网络抓取脚本放入一个集群中,你可以预先配置节点,如EC2。
这些新的数据源监控成本更低和使用更简单。因为这些数据产品可以轻松地集成到单一的数据流程中。
优化业务流程
有效总结注释以及结构化数据源的能力,为优化业务流程打开了广阔的空间。
例如,你可以将最近的活动列表作为AI代理的总体提示。然后,你可以通过迭代账户执行官、业务发展代表或其他职能角色,并使用AI来总结他们应该做的事情(附带到相关资源的规范链接)。
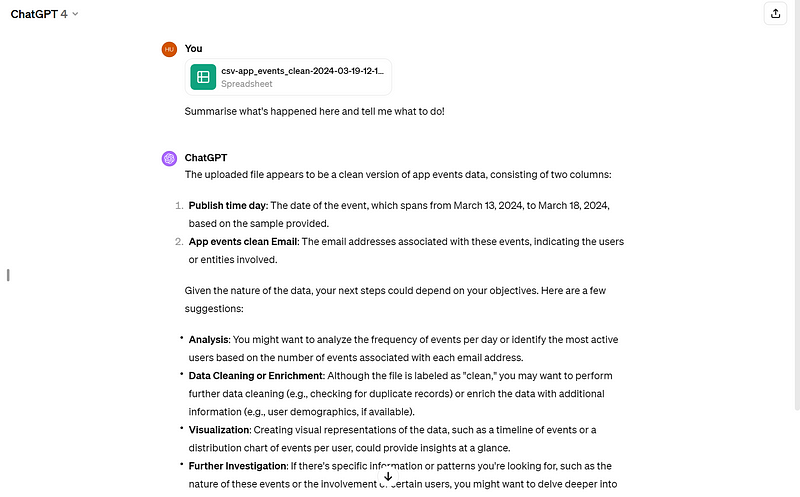
GPT-4告诉我如何处理Orchestra上的用户注册——显然可以以更好的方式进行提示
生成式AI在分析数据,并提炼销售工作优先级方面表现出色。大模型擅长分析非结构化数据,并提供有洞察力的见解。数据团队在这方面处于有利位置。
此外,这相对容易监控。通过使用一系列值触发LLM,数据团队可以实现批量化,并监控服务随着时间变化的使用情况。
生成式AI的分析经常受到怀疑,因此能够展示“数据产品”的使用情况至关重要。收集元数据并将其呈现给业务部门很重要。
总结
在这篇简短的文章中,我们讨论了数据团队可以快速测试公司里面数据和AI产品的四种方式:
- 特征工程 2. 非结构化数据 3. 数据抓取 4. 优化业务流程
这些方法的效果,很大程度上取决于组织中现有的流程。
如果业务部门与数据团队之间没有紧密沟通,那么在组织中释放生成式AI能力,是不太可能奏效的。
数据团队需要成为倡导者,并像初创公司一样,向业务的其他成员推销自己。
其他例子,如特征工程,可能影响很小。在表格中有一列是总结,不太可能在任何方面“移动指针”。
当与利益相关者需求相关联时,用例(2)和(3)可能非常有影响力。如果财务团队乐于将合同输入ERP系统,那么他们不太可能接受对这项工作自动化。CFO或财务总监可能会有不同的看法。
所有这些的基础都是数据团队与C级管理层之间的沟通。
数据团队应确保他们使用一个平台。该平台汇总了他们的数据和AI产品(如成本、使用情况和性能),以便与C级高管进行沟通——展示他们的数据和AI产品带来的商业价值。
关于作者
我是Hugo Lu。我开始在伦敦从事并购,后来转到JUUL,并进入数据工程领域。在短暂回到金融行业后,我领导了位于伦敦的金融科技公司Codat的数据部门。现在我是Orchestra的CEO,Orchestra是一个数据发布工具,帮助数据团队可靠、高效地将数据发布到生产环境中。
本文由活水智能编译,转载请注明出处
广受好评的活水AI线下工作坊正在进行中🔥
课程围绕在 AI 时代,知识工作者面临的十大难题设计,我们通过系列课程,给出关于这些难题的独特见解,以及解决之道。
二期围绕如何微调、训练与分发大模型展开。 在这一期,我们将深入探讨向量数据库与RAG的应用,教你如何在AI时代重组数据,整合内外知识库,提升工作效率和准确性。