之前有AI编程课的同学提问,如果临时接手一个中型或大型的代码仓库,该从哪入手?今天这篇文章推荐给有类似问题的同学。我们可以构建代码图(code graph)来帮助我们厘清复杂代码中的实体关系。
来源:Roi Lipman
编译:活水智能
代码(code graph)是现代软件的基础,但随着代码库复杂度的增加,理解和导航代码变得越来越具有挑战性。代码图(Code Graph)是代码库的可视化表示,它利用知识图谱和大语言模型(LLMs)来映射代码实体之间的关系,例如函数、变量和类。
在本文中,我们将探讨代码图的核心概念,深入了解它们是如何创建的,并解释它如何增强代码分析。我们还将展示 FalkorDB 的代码图工具 (https://github.com/FalkorDB/code-graph) ,该工具可以从任何 GitHub 存储库中创建一个可部署的代码图浏览器和查询接口。让我们开始吧!
什么是代码图及其如何增强代码分析
代码图是将代码库可视化为知识图谱的一种表示形式,它可以帮助人们探索代码中的实体(函数、变量、类)及其之间的关系。通过绘制这些连接,理解代码的结构和流程变得更容易,发现潜在问题,提高代码的整体质量。
将代码表示为图数据结构的概念可以追溯到软件工程的早期,当时研究人员探索如何使用基于图的技术来建模和分析程序的结构和行为。现代代码图结合了知识图谱和大语言模型(LLMs),是最近的发展。
现代知识图谱数据库,使得存储、查询和可视化大规模代码图变得更加高效。这种能力增强了对代码的理解,它在代码导航中可以提供多种编程语言无关的优势:
-
• 提高理解力: 帮助跟踪数据在函数中的流动,并识别互相关联的组件。
-
• 影响分析: 评估代码更改的连锁反应,预测潜在问题。
-
• 自动补全: 根据当前上下文建议相关函数、变量和类型。
-
• 代码搜索: 不仅通过关键字搜索功能,还通过理解代码元素之间的关系来搜索功能。
代码图能够清晰地展示复杂代码结构的图形视图,使得跟踪代码执行路径和调用图、定位高复杂度区域以及促进更好的调试和重构变得更加简单。
我们已经在FalkorDB(https://code-graph.falkordb.com/)创建了几个示例代码图及其相应的可视化。

FalkorDB代码图浏览器上的代码图示例
用于代码图创建的 RAG(检索增强生成)
知识图谱的出现不仅使得可视化成为可能,还可以遍历和推理代码图中的关系。例如,使用适当的 Cypher 图查询,你可以:
-
• 发现代码库中的递归函数;
-
• 探索完全未使用的方法;
-
• 查找最常用的方法;
-
• 发现一个函数如何影响另一个函数。
然而,如果你想用自然语言查询来完成相同的任务呢?这就是现代 LLMs 和检索增强生成(RAG)架构的作用所在。
通过利用 LLMs,开发人员可以用自然语言向其代码库提出问题,而 RAG 管道则可以帮助将这些查询转换为图查询,同时解释检索到的结果。开发人员可以提出类似于以下的问题:
-
• “哪些函数在该模块中被调用最频繁?”
-
• “项目中是否存在未使用的方法?”
他们可以在不需要掌握复杂查询语言的情况下获得见解,从而以更便捷的方式与代码库进行交互。
这可以解锁几种功能:
-
• 改进代码导航
-
• 理解不同模块、函数、类、方法
-
• 从代码中创建文档
-
• 发现代码中的依赖关系
RAG 架构通过将检索模型与生成模型(由 LLMs 驱动)集成在一起,首先根据输入查询从数据存储中获取相关文档或数据。然后,生成模型使用检索到的信息作为上下文,生成更准确且上下文相关的输出,有效地将搜索和生成能力结合起来。
在构建代码图的 RAG 架构时,开发人员通常使用向量数据库通过相似性搜索来检索文档。然而,当涉及到代码图时,这种方法会遇到困难,如下所示。
使用知识图谱构建 RAG 驱动的代码图的优势
为了构建代码图的 RAG 架构,开发人员可以使用向量数据库或知识图谱为 LLMs 提供上下文。
向量数据库将数据存储为高维向量嵌入,这些是无结构数据的数值表示,捕捉了其语义含义。在代码探索的情况下,将代码库及其元素转换为向量嵌入可以在向量空间中搜索,以根据查询找到相似或不同的函数。
例如,函数 A的向量嵌入可能看起来像[0.12, 0.31, 0.56, 0.88, …, 0.92],而函数 B的向量嵌入可能看起来像[0.83, 0.66, 0.91, 0.89, …, 0.91]。使用向量数据库,每个数据点被转换为数值表示,允许通过相似性搜索来确定哪些元素(函数、参数)更近或更远。这也允许使用自然语言查询来精确定位代码库的正确部分。
然而,当你试图对代码库进行推理或探索函数、模块、类等元素之间的关系时,这种方法会失败。为此,你需要一种以结构化方式捕捉代码元素之间关系的方法。知识图谱在这方面具有显著优势:
-
1. 结构化关系: 知识图谱捕捉了不同代码元素之间的直接关系,例如继承、依赖和使用模式。
-
2. 图查询: 使用知识图谱,你可以使用类似 Cypher 的图查询语言来遍历和分析图谱。这允许你识别递归函数、未使用的方法或高度使用的函数,并理解代码库的不同部分如何相互作用。
-
3. 推理: 知识图谱支持推理和推断,使你能够从现有关系中得出新的见解。这对于影响分析等任务至关重要,在这些任务中,你需要了解代码库更改的潜在后果。
-
4. 与 RAG 的集成: 当与 RAG 架构集成时,知识图谱可以为 LLMs 提供丰富的上下文信息,从而生成更准确和上下文相关的输出。这种组合利用了结构化和非结构化数据表示的优势。
-
5. 可扩展性: 知识图谱可以随着代码库的发展而演变,使项目增长时的维护和扩展更加容易。它们可以无缝集成到各种开发工具中,提供始终最新的代码库统一视图。
换句话说,虽然向量数据库在相似性搜索方面提供了强大的功能,但知识图谱提供了一种结构化的解决方案来对代码库进行推理并探索代码元素之间的复杂关系。
这使得知识图谱成为构建有效的 RAG 驱动的代码图的正确技术,这种架构被称为 KG-RAG 或GraphRAG(https://www.falkordb.com/blog/what-is-graphrag/)。
可视化你的代码与代码图
当使用知识图谱构建代码图时,代码的可视化探索变得可能。例如,使用 FalkorDB,你可以构建代码图并可视化类、方法、参数和模块之间的相互关系。你还可以对代码库提出“问题”,例如“列出参数最多的函数”。
此外,这种方法还提供了几个关键好处:
-
• 依赖关系映射: 发现各个模块、类和函数之间的依赖关系。
-
• 简化调试: 跟踪执行路径并定位错误或性能瓶颈的来源。
-
• 增强文档: 作为一个动态且始终更新的文档工具,帮助团队成员理解项目的结构和流程。
-
• 影响分析: 进行有效的影响分析,以查看代码库的一个部分的更改如何影响其他部分。
-
• 协作: 确保每个人对项目架构和依赖关系有一致的理解。
-
• 交互式探索: 使开发人员能够深入特定代码部分,进行详细分析并运行查询。
本质上,使用代码图可视化你的代码可以将复杂的代码库转换为直观的交互式图表。
使用 FalkorDB 代码图浏览器,你可以尝试 Python requests 库的代码图。你可以放大、以自然语言查询图表,并详细了解该库的工作原理。
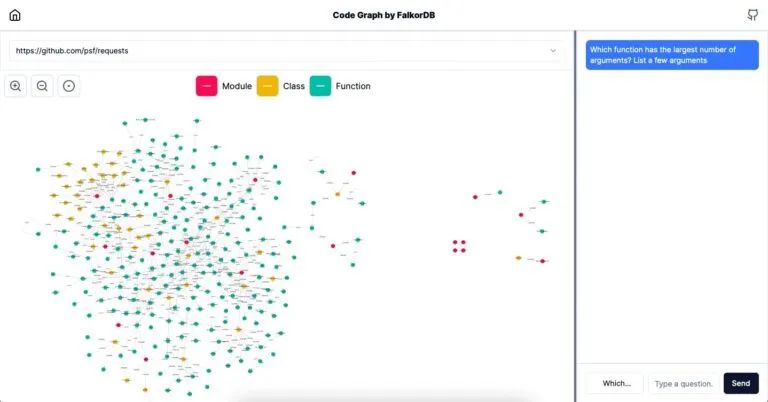
FalkorDB代码图自然语言查询功能
你可能想知道如何为自己的项目创建类似的代码图。接下来,我们将描述其基础架构,然后解释如何使用 FalkorDB 实现这一点。
理解代码图构建的工作流程
创建代码图涉及多个步骤,可以将你的代码库转换为可视化和交互式的图形:
1. 静态代码分析
第一步是对你的代码库进行彻底的分析。目标是解析各种实体,例如类、方法、函数及其相互关系——类似于编译器的工作方式。在此过程中,使用抽象语法树(AST)解析器,可以精确提取代码的结构和行为属性。
2. 图构建
接下来是构建代码图并将其存储在知识图谱中。这包括系统地为每个识别出的实体(例如类、方法)创建节点,并创建边来表示继承、方法调用、程序依赖性和数据流等关系。这可以通过使用 Cypher 查询来实现。
3. 数据增强
可选地,你还可以包括元数据,如函数签名、文档注释、代码度量(例如圈复杂度、代码行数)以及版本控制历史记录。通过数据增强,这个图谱会转变为一个全面的知识库。
4. 可视化
接下来,你可以使用图形渲染库来可视化代码图,这有助于构建清晰且交互的图表,以展示代码库内复杂的关系。可视化引擎支持放大、平移和节点高亮功能,使开发人员能够直观地探索复杂的代码结构。
5. 查询与分析
一旦代码图在知识图谱中构建完成,你就可以开发一个应用程序,利用RAG架构对其进行查询和分析。使用像OpenAI的GPT模型或开源的LLM如Llama 3,你可以将自然语言查询转换为Cypher查询,然后使用知识图谱来探索和推理这些图表。例如,可以通过查询识别参数最多的函数,发现代码中的有向图结构,检测循环依赖,或跟踪数据流路径。
遵循这一工作流程,开发人员可以将其代码库转变为强大的可视化工具,显著提高分析、理解和维护复杂软件项目的能力。
与OpenAI互动以转换查询
像GPT-4或GPT-4o这样的OpenAI模型能够将自然语言查询转换为Cypher语言,然后可以用于探索代码图。
例如,LLM可以将“查找参数最多的前10个函数”这样的自然语言查询转换为以下Cypher查询:
MATCH (f:Function)-[:HAS_ARGUMENT]->(a:Argument)
RETURN f.name AS FunctionName, COUNT(a) AS ArgumentCount
ORDER BY ArgumentCountDESC LIMIT 10
同样,“列出未被任何其他函数调用的所有函数”这样的查询可以被翻译为如下Cypher查询:
MATCH (f:Function)
WHERE NOT (f)<-[:CALLS]-(:Function)RETURN f.name AS UnusedFunction
一个更复杂的例子是“查找所有通过任何数量的中间函数间接由‘main’函数调用的函数”,这需要进行图遍历:
MATCH path = (start:Function {name: "main"})-[:CALLS*2..]->(end:Function)
RETURN DISTINCT end.name AS IndirectlyCalledFunction, length(path) AS HopsORDER BY Hops
Cypher的一个显著优势是它的可读性极强,这使得理解应用程序如何利用图表变得更容易。如果你试图使用向量数据库构建类似的应用程序,不仅无法实现代码图的探索,查询还会采用难以解释的向量嵌入。
代码图的详细知识图谱架构
如上所述,知识图谱提供了一个强大的方式来创建代码图。那么,典型的代码图的知识图谱架构是什么样的呢?
以下是一个典型Python代码库基本元素的详细架构。
实体
- 1. 模块
- • name (字符串):
模块的名称。
- • path (字符串):
模块的文件路径。
-
• 表示一组相关的代码组件。
-
• 属性:
-
2. 类
- • name (字符串):
类的名称。
- • access_modifier (字符串):
访问级别(如公共、私有)。
- • is_abstract (布尔值):
是否为抽象类。
- • documentation (字符串):
文档或注释。
-
• 表示代码中的一个类。
-
• 属性:
-
3. 函数
- • name (字符串):
函数的名称。
- • return_type (字符串):
函数的返回类型。
- • access_modifier (字符串):
访问级别(如公共、私有)。
- • documentation (字符串):
文档或注释。
- • complexity (整数):
函数的圈复杂度。
- • lines_of_code (整数):
代码行数。
-
• 表示一个函数或方法。
-
• 属性:
-
4. 参数
- • name (字符串):
参数的名称。
- • type (字符串):
参数的数据类型。
- • default_value (字符串):
默认值(如果有)。
-
• 表示函数的一个参数。
-
• 属性:
-
5. 变量
- • name (字符串):
变量的名称。
- • type (字符串):
变量的数据类型。
- • initial_value (字符串):
初始值(如果有)。
-
• 表示函数或类中的一个变量。
-
• 属性:
-
6. 文件
- • name (字符串):
文件的名称。
- • path (字符串):
文件路径。
- • size (整数):
文件大小,以字节为单位。
- • modification_date (日期):
最后修改日期。
-
• 表示代码库中的一个文件。
-
• 属性:
关系
- 1. 包含
-
• 表示包含关系。
-
• 起点:
模块、文件
- • 终点:
类、函数
- • 示例:
(:Module)-[:CONTAINS]->(:Class), (:File)-[:CONTAINS]->(:Function)
-
2. 继承自
-
• 表示类之间的继承关系。
-
• 起点:
-
类
- • 终点:
类
- • 示例:
(:Class)-[:INHERITS_FROM]->(:Class)
-
3. 实现
-
• 表示类实现接口。
-
• 起点:
-
类
- • 终点:
类 (接口)
- • 示例:
(:Class)-[:IMPLEMENTS]->(:Class {is_interface: true})
-
4. 调用
-
• 表示函数调用关系。
-
• 起点:
-
函数
- • 终点:
函数
- • 示例:
(:Function)-[:CALLS]->(:Function)
-
5. 有参数
-
• 表示函数和参数之间的关系。
-
• 起点:
-
函数
- • 终点:
参数
- • 示例:
(:Function)-[:HAS_ARGUMENT]->(:Argument)
-
6. 声明
-
• 表示函数或类中声明的变量。
-
• 起点:
-
函数、类
- • 终点:
变量
- • 示例:
(:Function)-[:DECLARES]->(:Variable)
-
7. 编写于
-
• 表示代码使用的编程语言。
-
• 起点:
-
文件
- • 终点:
语言
- • 示例:
(:File)-[:WRITTEN_IN]->(:Language)
-
8. 依赖于
-
• 表示模块、文件或类之间的依赖关系。
-
• 起点:
-
模块、文件、类
- • 终点:
模块、文件、类
- • 示例:
(:Module)-[:DEPENDS_ON]->(:Module)
-
9. 定义于
-
• 表示类或函数的定义位置。
-
• 起点:
-
类、函数
- • 终点:
文件
- • 示例:
(:Class)-[:DEFINED_IN]->(:File)
构建代码图
如前所述,构建代码图可能是一项复杂的任务。然而,FalkorDB提供了一个简单易用的解决方案,可以帮助你轻松创建代码图。
它提供了一个Python模块,用于从公共Git存储库中创建代码图,并允许你将其托管在一个端点上,使任何开发人员都可以使用浏览器来可视化和探索存储库的代码库。
操作步骤如下:
首先,克隆FalkorDB代码图仓库。
git clone https://github.com/FalkorDB/code-graph.git
然后,安装npm库。
接着,通过Docker运行FalkorDB。
docker run -p 6379:6379 -it --rm falkordb/falkordb
现在,将你的OpenAI API密钥设置为环境变量,因为它将被用于生成Cypher查询以探索知识图谱,以及回答与代码图相关的RAG问题。
export OPENAI_API_KEY=YOUR_OPENAI_API_KEY
你现在可以从上面克隆的代码图目录启动FalkorDB代码图工具。
这将在端口3000上启动一个服务器。你现在可以导航到http://localhost:3000/,输入项目存储库的GitHub URL来生成代码图。
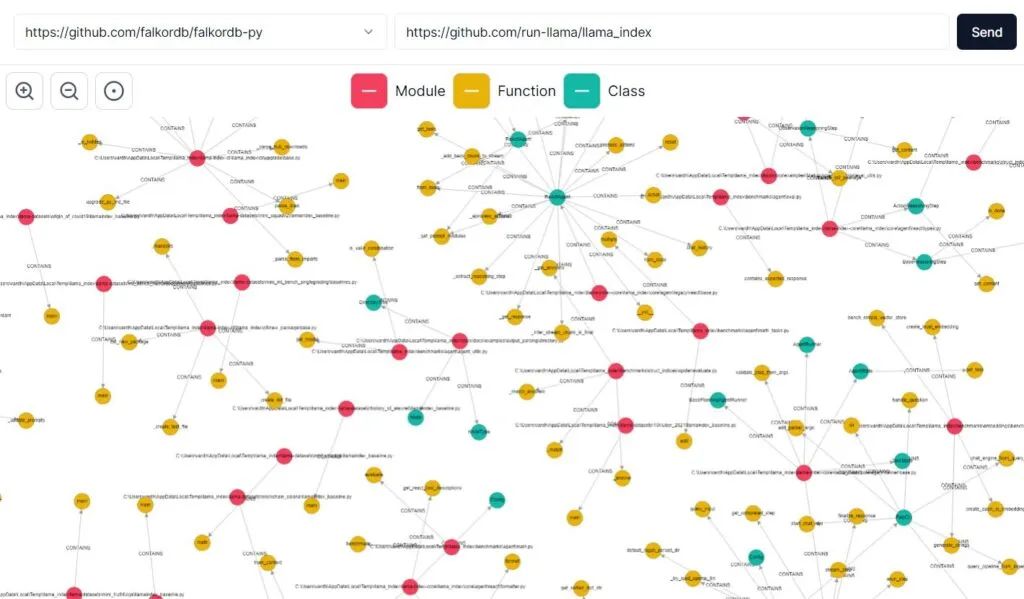
从项目存储库的GitHub URL生成的代码图
下面是LlamaIndex中ReactAgentWorker类的代码图。
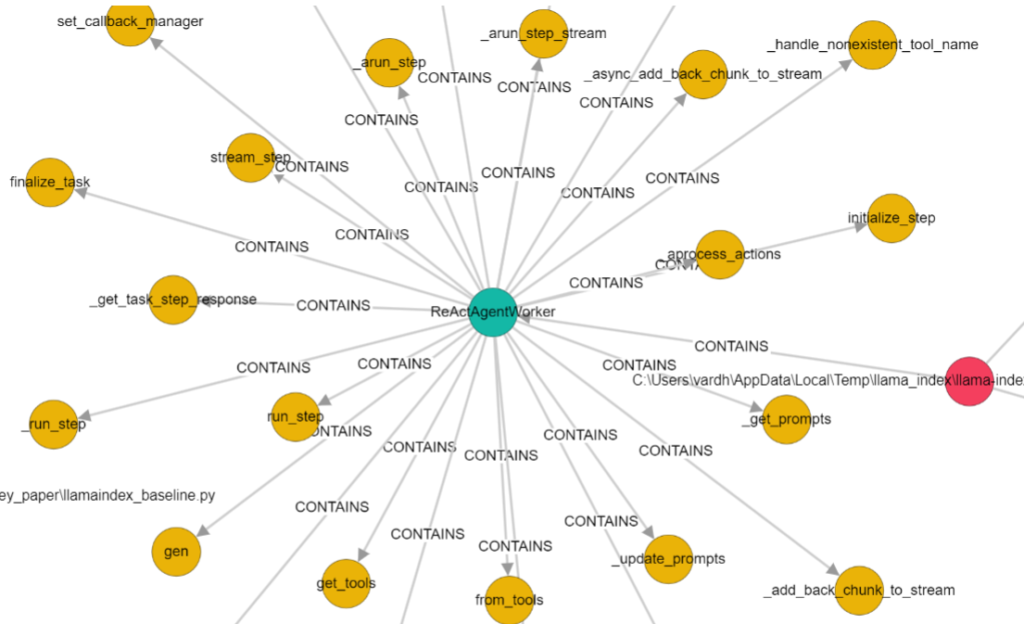
FalkorDB中的ReactAgentWorker类代码图
你还可以在侧边栏对代码图提问,它会以自然语言作出回应。这一功能在导航复杂而庞大的编程框架
代码库时非常有用。
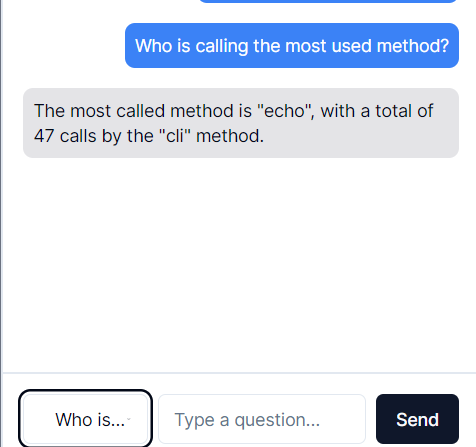
FalkorDB的自然语言查询功能
使用FalkorDB代码图浏览器,你可以探索复杂的代码库、提出问题,并以自然语言获得见解,使对大型代码库的导航和理解变得更加可控且有效。
未来展望
将LLMs与FalkorDB这样的知识图谱集成,有望彻底改变代码库的可视化和理解方式。通过结合LLMs和知识图谱的能力,开发人员将能够常规地使用自然语言查询与其代码图进行交互,从而使复杂的代码结构更加易于访问和理解。
这种技术的发展可能显著提高生产力,通过自动化和简化代码关系与依赖分析,最终有潜力改变软件开发流程并提升效率。
要开始使用,请访问代码图的GitHub仓库(https://github.com/FalkorDB/code- graph),浏览文档(https://docs.falkordb.com/)以了解更多关于FalkorDB知识图谱的信息。
学习资源
若要了解更多关于使用知识图谱构建智能LLM应用程序的信息,请查看我们工作公众号的其他文章: