
本文将介绍如何使用R2R平台和Triplex模型,从文档中自动生成知识图谱。这些知识图谱不仅能够揭示数据之间的联系,还可以与AI大模型结合,在本地运行,保护数据隐私。
R2R 是一个功能强大的检索增强型生成(RAG)应用开发平台,支持多模态文件处理、混合搜索、知识图谱构建,并提供用户管理、性能监控和可扩展的API接口。
准备工作
安装 R2R
要开始使用R2R,请首先在命令行中安装R2R:
pip install r2r
安装完成后,建议通过Docker启动R2R以获得更好的性能和隔离环境:
# export OPENAI_API_KEY=sk-...
r2r --config-name=default serve --docker
启动 R2R 服务
使用以下命令启动R2R服务,并确保其在Docker环境中运行:
r2r --config-name=local_llm_neo4j_kg serve --docker
安装 Triplex 模型(可选)
Triplex模型是一个用于本地构建知识图谱的开源模型,其运行成本远低于GPT-4o。你可以选择安装它以增强图谱构建的能力。
# 检查Ollama容器的名称,并根据实际情况修改命令
docker exec -it r2r-ollama-1 ollama pull sciphi/triplex
docker exec -it r2r-ollama-1 ollama pull llama3.1
docker exec -it r2r-ollama-1 ollama pull mxbai-embed-large
有关Triplex模型的更多信息及安装方法,请参考这篇文章:Triplex:用于创建知识图谱的开源模型,成本比GPT-4o低10倍!
基本操作
数据获取与可视化
首先,我们在本地创建了一个文件 test.txt,内容如下:
John is a person that works at Google. Paul is a person that works at Microsoft that collaborates with John.
然后使用R2R将 test.txt 转换为知识图谱:
r2r ingest-files --file-paths r2r/examples/data/test.txt
转换完成后,生成的知识图谱如下图所示,展示了文件 test.txt 中各个实体之间的关系:
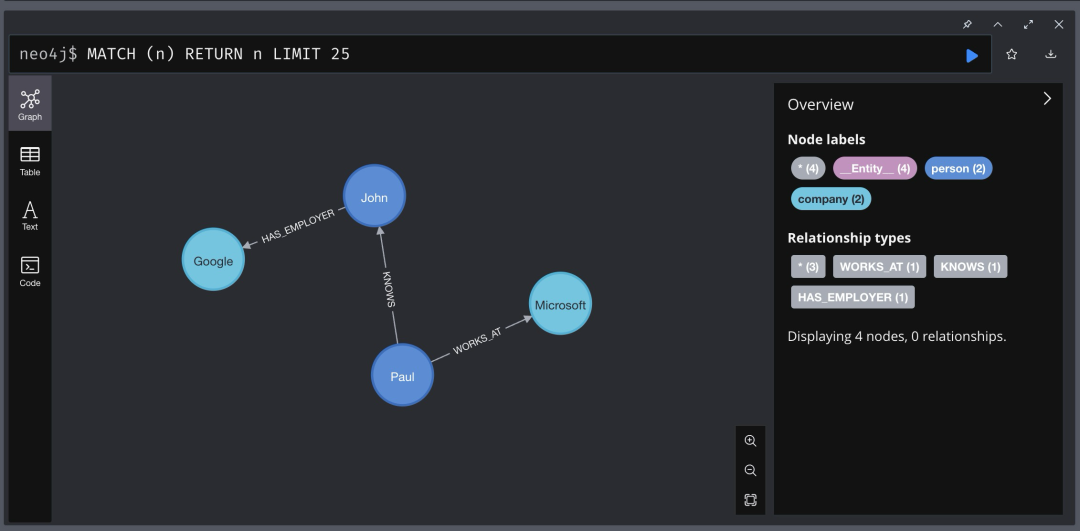
语义搜索
R2R 还对文本进行了分块和嵌入,以实现语义搜索。以下是验证步骤:
r2r search --query="Who is John?"
终端将输出与查询相关的内容:
{
"id": "5c7731be-81d6-5ab1-ae88-458fee8c462b",
"score": 0.5679587721418247,
"metadata": {
"text": "John is a person that works at Google.\n\nPaul is a person that works at Microsoft that knows John.",
"title": "test.txt",
"version": "v0",
"chunk_order": 0,
"document_id": "56f1fdc0-df48-5245-9910-75a0cfb5c641",
"extraction_id": "e7db5809-c9e0-529d-85bb-5a78c5d21a94",
"associatedQuery": "Who is John?"
}
}
高级操作
自定义实体和关系
假设我们需要获取硅谷著名风投公司YC有关的几千家创业公司信息。首先,我们可以指定构建知识图谱的实体类型和关系,以提高图谱的构建质量:
from r2r import EntityType, Relation
entity_types = [
EntityType("ORGANIZATION"),
EntityType("COMPANY"),
EntityType("SCHOOL"),
# 更多实体类型...
]
relations = [
Relation("EDUCATED_AT"),
Relation("WORKED_AT"),
Relation("FOUNDED"),
# 更多关系类型...
]
接下来,向R2R服务器提交请求,更新知识图谱,并使用你指定的实体类型:
client = R2RClient(base_url=base_url)
r2r_prompts = R2RPromptProvider()
# 使用少样本示例提高云提供商性能
prompt_base = ("zero_shot_ner_kg_extraction" if local_mode else "few_shot_ner_kg_extraction")
update_kg_prompt(client, r2r_prompts, prompt_base, entity_types, relations)
你可以使用以下命令来查看这些实体和关系之间的联系:
# 当使用云提供商时,添加 --local_mode=False
python -m r2r.examples.scripts.advanced_kg_cookbook --max_entries=1
通过Neo4j浏览器可以可视化生成的基础图谱。下图显示了与Airbnb公司相关的信息:
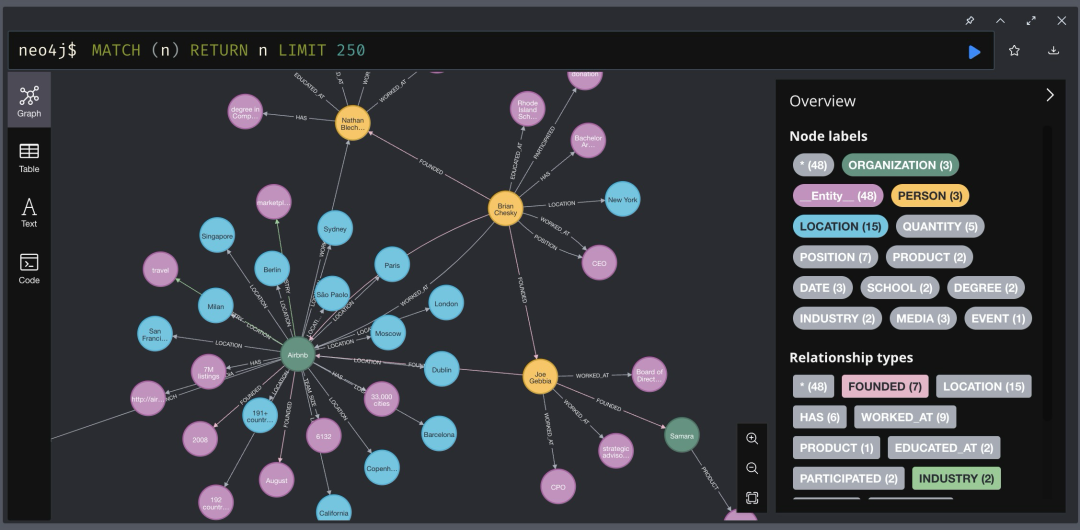
扩展数据集
现在,我们可以使用更大规模的数据集来构建知识图谱:
python -m r2r.examples.scripts.advanced_kg_cookbook --max_entries=100
加载完所有数据后,你会发现图谱更加丰富。当专注于旧金山并限制节点数为250时,我们可以看到更多数据之间的联系:
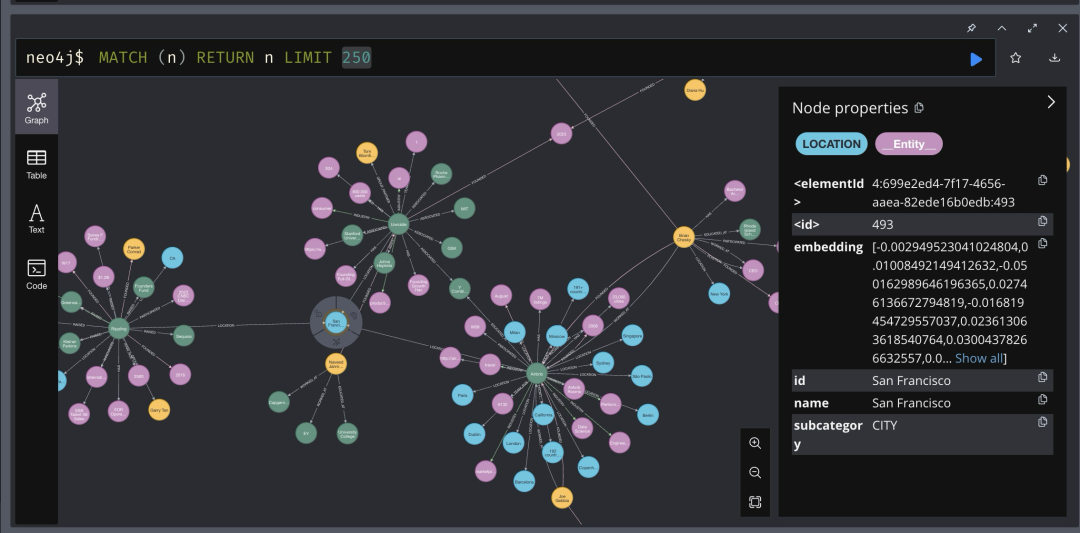
你可以使用以下查询命令来便捷地获取各种信息:
# 查找所有创始人
query = """
MATCH (p:PERSON)-[:FOUNDED]->(c)
RETURN p.id AS Founder, c.id AS Company
ORDER BY c.id
LIMIT 10;
"""
# 输出示例:
# [{'Founder': 'Nathan Blecharczyk', 'Company': 'Airbnb'}, {'Founder': 'Brian Chesky', 'Company': 'Airbnb'}, ...]
# 查找创办过两家以上公司的创始人
query = """
MATCH (p:PERSON)-[:FOUNDED]->(c:ORGANIZATION)
WITH p.id AS Person, COUNT(c) AS CompaniesCount
RETURN Person, CompaniesCount
ORDER BY CompaniesCount DESC
LIMIT 10;
"""
# 输出示例:
# [{'Person': 'Ilana Nasser', 'CompaniesCount': 3}, {'Person': 'Eric', 'CompaniesCount': 2}, ...]
# 查找具有AI产品的公司
query = """
MATCH (c:ORGANIZATION)-[r:PRODUCT]->(t)
WHERE t.id CONTAINS 'AI'
RETURN DISTINCT c.id AS Company, t.id AS Product
ORDER BY c.id
LIMIT 10;
"""
# 输出示例:
# [{'Company': 'AgentsForce', 'Product': 'AI support agents'}, {'Company': 'Airfront', 'Product': 'AI-first email platform'}, ...]
更多功能
R2R还可以使用知识图谱代理(Agents)完成更灵活和复杂的查询,详情请参考官方文档(见文末链接)。
总结
通过R2R创建的知识图谱,你可以轻松地结构化和查询从文档中提取的信息。结合向量搜索、语义搜索和结构化查询,你可以使用非结构化和结构化数据构建复杂的检索系统。
微软在7月发布的GraphRAG技术,通过整合文本抽取、网络分析和大型语言模型的提示与总结功能,形成了一个全面的系统,能够提供对文本数据的深度理解。
想要了解更多关于R2R的信息,请参考官方文档:R2R官方文档