
通过检索增强生成(RAG)技术,从而让大模型调用外部知识源(比如个人和公司保存的大量文档)回答问题。
但是当回答针对整个文本语料库的全局性问题,如“数据集中的主要主题是什么?”,RAG却无能为力。
因为这类问题本质上是查询聚焦摘要(QFS)任务,而非一个明确的检索任务。
怎么办呢?
微软提出的知识图谱RAG(以下使用:Graph RAG)技术,能够将复杂的、大规模文本数据集转化为易于理解和操作的知识结构,以便更好地理解实体(如人物、地点、机构等)之间的相互关系。
你可以把该技术理解为通过两个步骤简化文本索引:
首先,利用大型语言模型从文档中提取关键信息,构建出反映实体间关系的知识图谱;
然后,为这些实体的集合生成精炼的摘要。当用户提问时,系统会根据这些摘要生成初步答案,并将它们综合起来,提供一个全面的回答。
例如,当你想了解一个百万条信息的数据集包含哪些主题或者实体时,Graph RAG就能给出更丰富、更全面的答案。
总结起来,优势在于跨文档处理!检索更快,更准确!利于发现实体之间联系!
在AI大模型时代,这项技术提升了个人和组织,从大规模文本中提取深层次信息的能力,帮助你从众多文档中发现新信息。
以下是实现细节解读,更详细的可查看:https://arxiv.org/pdf/2404.16130v1
运用场景
Graph RAG的应用场景众多,比如用于深度信息提取,提取出隐藏在数据表层之下的关键信息和联系;为决策者提供快速、准确的信息摘要,提高决策效率。
我们看几个具体运用的例子:
假如你是科研人员,你可以通过Graph RAG快速梳理大量文献,从跨学科的资料中提取核心观点和最新研究进展,更便于撰写文献综述。
其次,还可以借助Graph RAG快速梳理某一领域的文献,识别关键主题、理论发展和研究空白,从而加速科学发现。
假如你是政策研究者,你可以借助Graph RAG从大量的政策文件、社会反馈和经济数据中提取关键信息,评估政策效果,指导政策制定,优化政策设计。
在法律行业,律师可以使用Graph RAG来梳理案件文档、法律条文和相关判例,快速定位到案件的关键点和相关法律依据,提高案件处理的效率。
新闻机构和内容创作者,可以利用Graph RAG从繁杂的资料中提炼核心信息,生成深度报道和评论,提高内容的质量。
那么Graph RAG是如何实现呢?
实现步骤
Graph RAG的关键步骤如下:
-
• 源文档分割:将文档合理切分成文本块,为大模型处理优化输入。
-
• 提取实例:从文本块中精准提取实体和关系的实例。
-
• 实例摘要化:将实体和关系的实例转换为精炼的摘要。
-
• 构建图社区:利用元素摘要通过社区检测算法构建图社区。
-
• 生成社区摘要:为每个图社区创建全面摘要,捕捉核心内容。
-
• 生成全局答案:通过整合社区摘要,高效生成针对用户查询的全面答案。
源文档分割
将原始文档被精心切分为易于处理的文本块。这一过程对于确定大模型的调用频率和信息抽取的准确性至关重要。
虽然文本块越多越好,但是你需要评估准确率和召回率,以最大化大模型的上下文窗口召回率,同时避免因文本过长而导致信息遗漏。
提取实例
将每个文本块被送入大模型,以识别和提取图中的节点和边的实例。
这一步骤通过多部分大模型提示词实现,首先识别文本中的所有实体及其属性,然后识别实体间的关系。
这些信息以一组分隔的元组形式输出,为构建图索引做好准备。
实例摘要化
利用大模型对实体、关系和声明的描述进行抽象总结,形成对概念的独立有意义的摘要。
这一过程依赖于大模型对文本本身未明确表述的概念(如隐含关系)的理解能力。
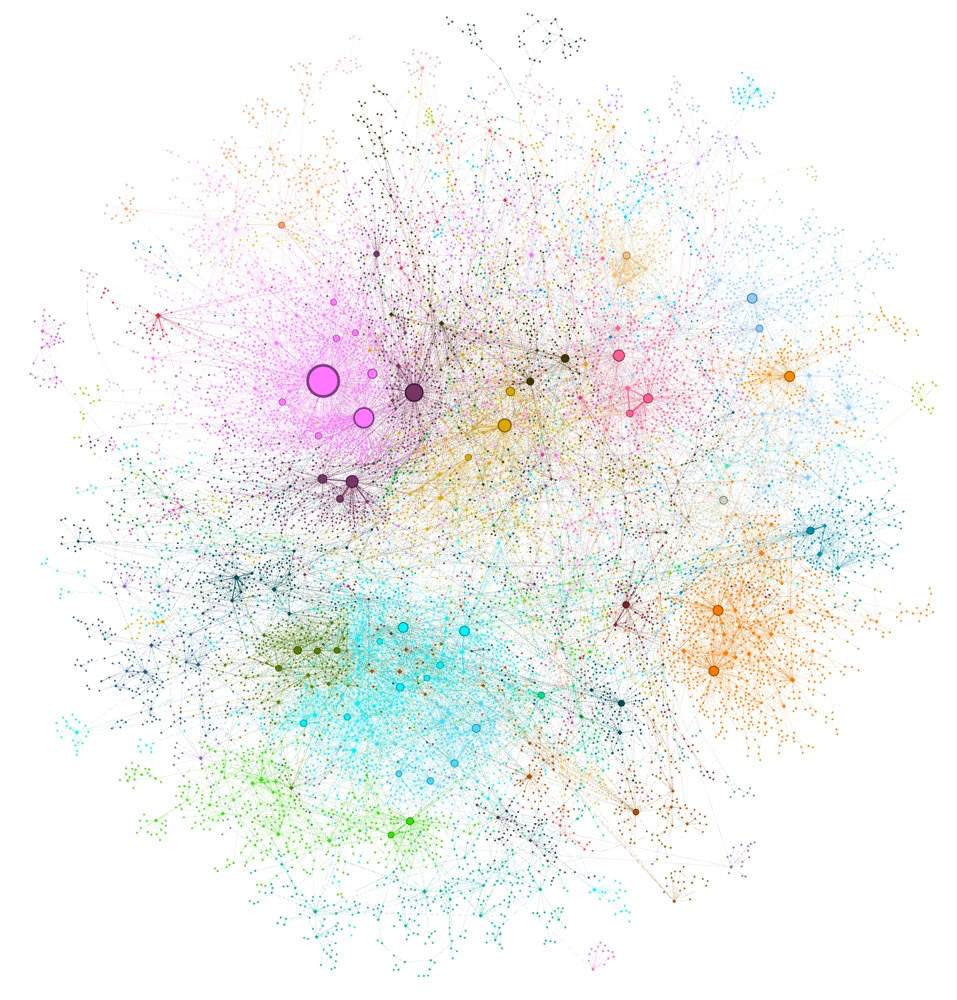
图 基础层级的社区
构建图社区
将上一步生成的摘要进一步整合,形成图社区。
这一步骤中,使用如Leiden算法等社区检测技术,将图划分为多个社区,每个社区内的节点彼此间联系更为紧密,代表了数据集中的相关主题或概念集合。
生成社区摘要
为每个社区生成摘要,这些摘要不仅有助于理解数据集的全局结构和语义,而且在没有具体查询的情况下,也可用于对整个文档集合的理解。
社区摘要的生成考虑了节点的重要性和连接度,以确保社区内的关键信息被有效捕捉。
生成全局答案
利用社区摘要生成对用户查询的全局答案。
首先,社区摘要被随机分配并分块,以适应LLM的上下文窗口大小。然后,对每个块并行生成中间答案,并由LLM评估答案的相关性。
最后根据答案的相关性分数进行排序,逐步汇总形成最终答案。
效果评估
作者使用了两个大规模数据集来验证Graph RAG方法的有效性:一个包含1669个文本块的播客转录数据集(约100万个token)和一个包含3197个文本块的新闻文章数据集(约170万个token)。相当于10本小说。
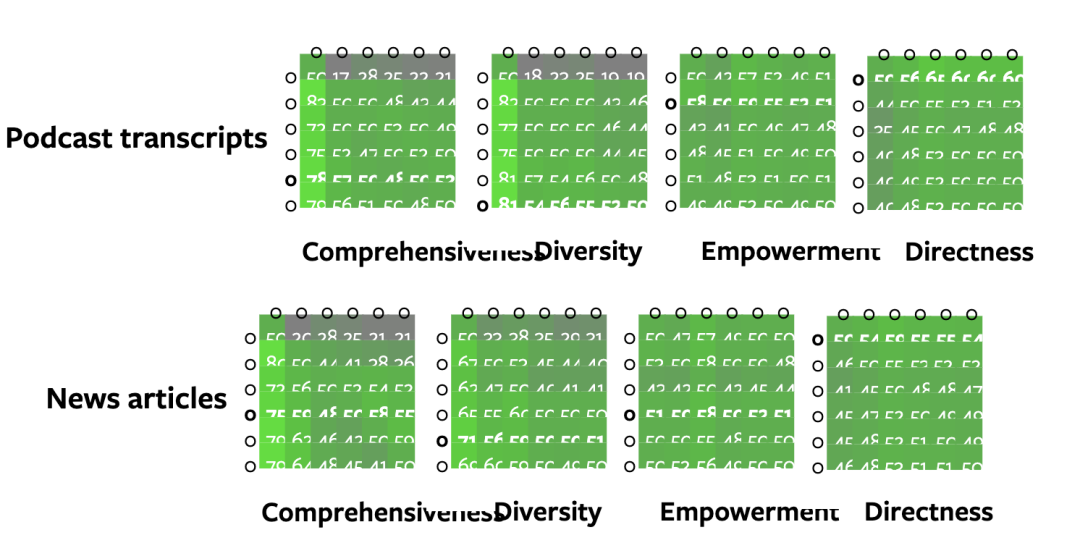
通过与naive RAG和全局文本摘要方法(TS)的比较,Graph RAG在全面性和多样性上优势明显,尤其是在使用8k tokens上下文窗口时,全面性胜率为58.1%,多样性胜率为52.4%。
此外,Graph RAG在根级别社区摘要上的性能优于naive RAG,同时在token成本上更具优势。
微软打算推出一个开源的、基于Python的Graph RAG方法的实现,它既支持全局也支持局部的查询处理。可以在 https://aka.ms/graphrag 查到。
遗憾的是,现在还没有推出。可以先使用我们之前写的工具,见推荐阅读。
有人评价:公司越来越多地将知识图谱视为他们的长期优势,因为它可以作为可扩展的结构化领域专业知识的表达方式,可以用作RAG的基础构建模块,甚至可以使用已经完成的图谱在未来对特定模型进行微调。
换句话说,在第三方技术以惊人的速度发展的时代,专注于清理和准备特定领域的专有数据以供接入这些系统,代表着一个始终保持优势的基础构建模块。
推荐阅读
Graph Maker:轻松使用开源大模型将文本转为知识图谱,发现新知识
最具代表性的文本数据集:覆盖32个领域,444个数据集,774.5TB数据量