AI大模型在各领域展现出了巨大潜力。这些模型的性能在很大程度上依赖于训练和测试所使用的数据集。
如果把大模型比喻为树木,那么数据集就是土壤。不同类型的土壤(数据集)能够培育出不同特性的树木(大模型)。如果土壤缺乏养分或不够多样化,那就回限制树木的生长。同样,如果数据集的质量不高或类型单一,也会限制大模型的性能。
目前对于如何构建和优化这些数据集,缺乏统一的认识和方法论。
本文从五个方面整合和分类了LLM数据集的基本内容:预训练语料库;指令微调数据集;偏好数据集;评估数据集;传统自然语言处理(NLP)数据集。
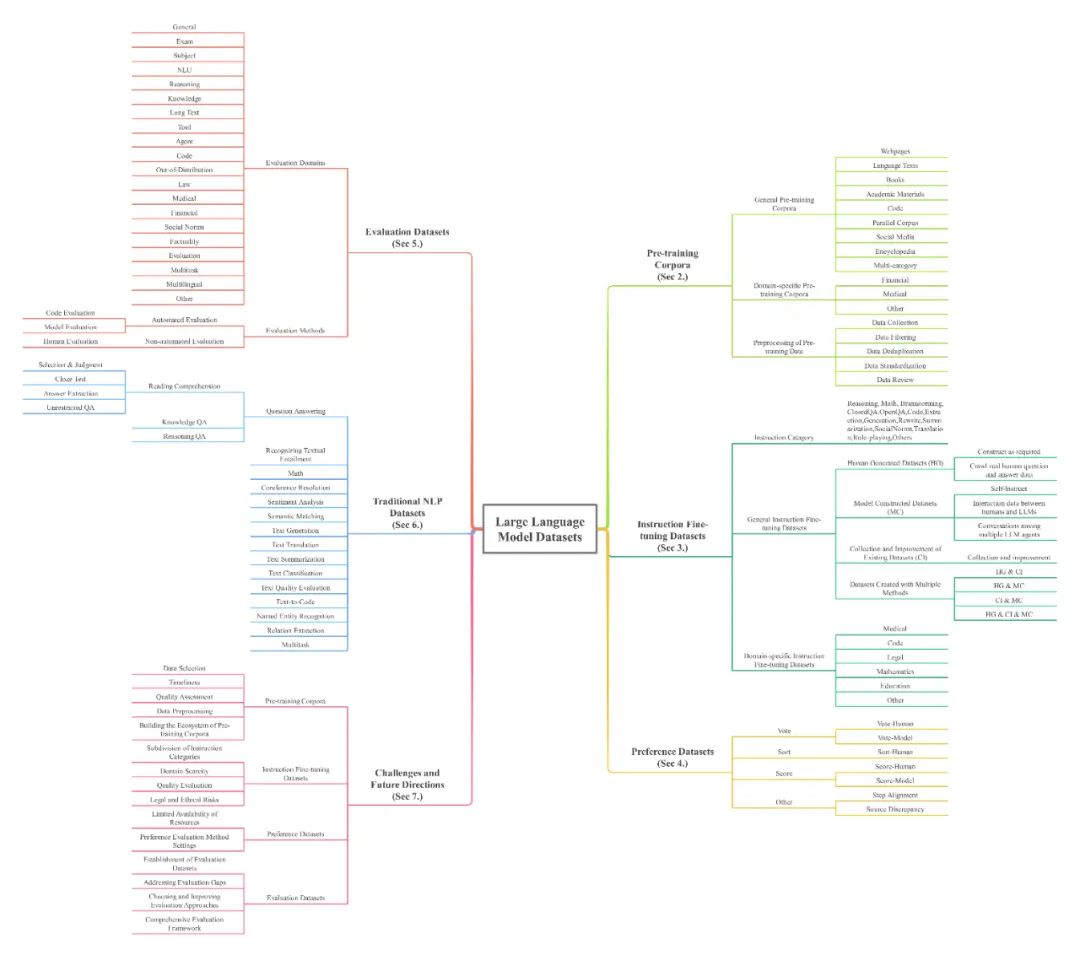
本文呈现了大模型文本数据集的全部面貌。包括444个数据集的统计数据,覆盖8种语言类别和32个领域。数据集统计信息包含20个维度,预训练语料库的数据总量超过774.5TB,其他数据集的实例数量超过7亿。
总的来说,是非常难得的资源,数据集地址及研究论文可在文末查看。
数据集时间线
下图总结了一些具有代表性的数据集的时间线。橙色代表预训练语料库,黄色代表指令微调数据集,绿色代表偏好数据集,粉色代表评估数据集。
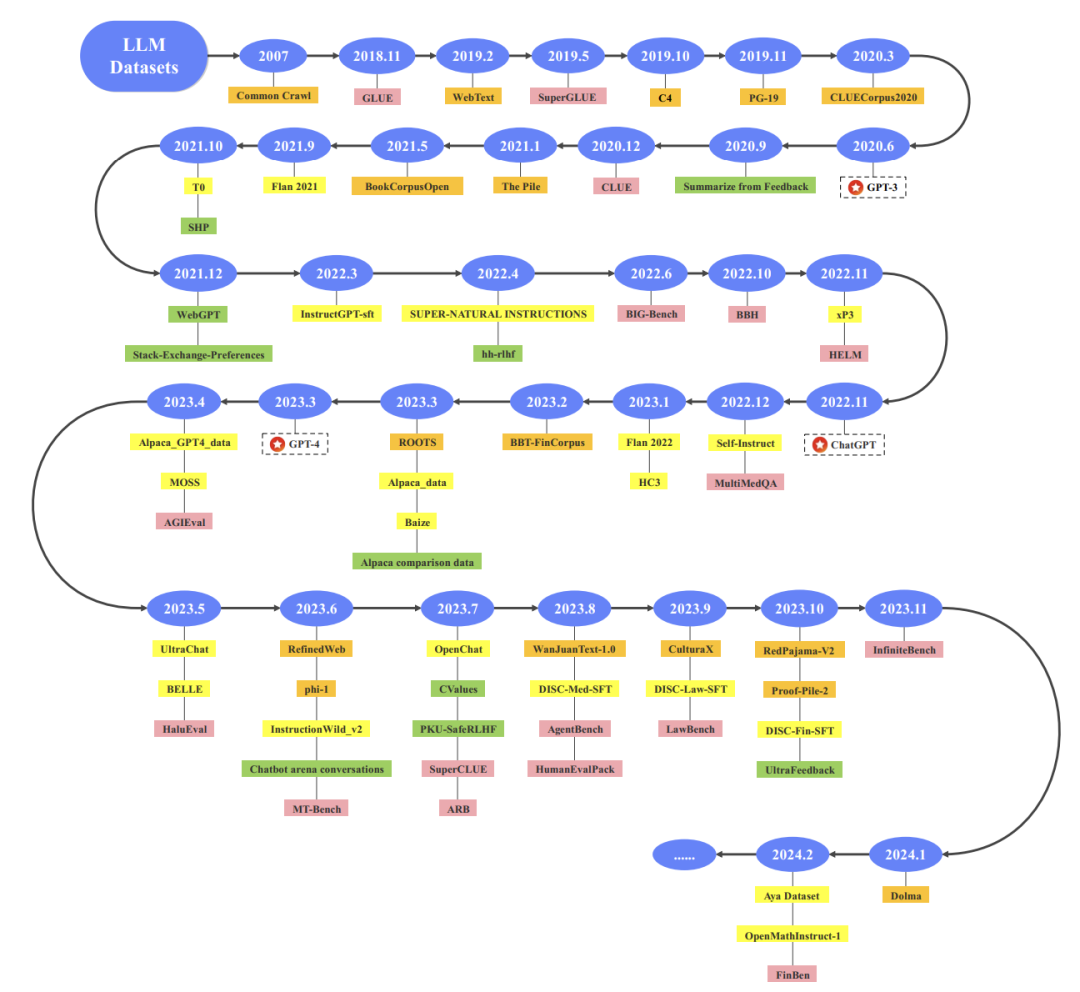
每个数据集的组织方式。

常见数据集
总共包含444个数据集,你能想到的数据集几乎都有,本文只介绍部分数据集,大家可从网站查看感兴趣的数据集。

数据集目录
通用预训练语料库
由不同领域和来源的海量文本组成的大规模数据集,其主要特点是文本内容不局限于单一领域,更适合训练通用的基础模型。
包括网页、语言文本、图书、学术资料、代码、平行语料库、社交媒体、百科全书、特定领域预训练语料库(如金融、医疗、数学等)。
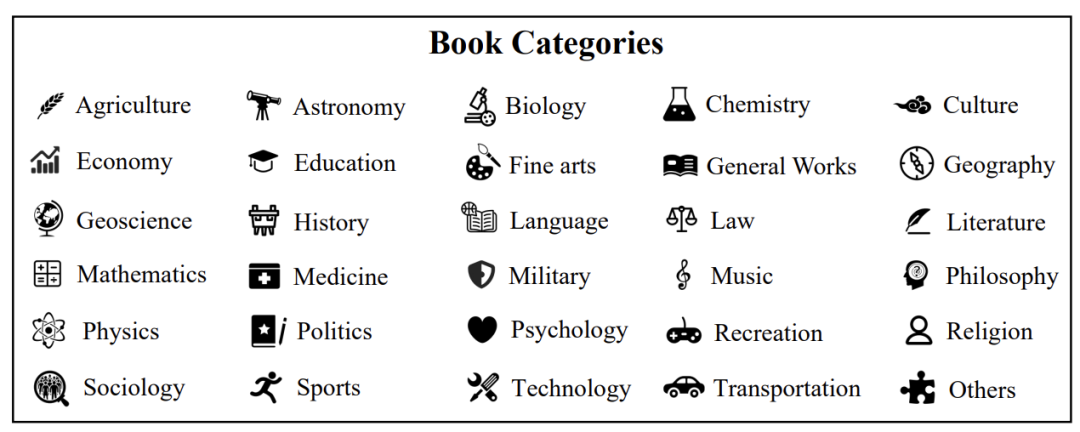
下图展示的是30个细化类别的书籍。如安娜图书馆,保存了3千万本书。
指令微调数据集
由一个或多个指令类别构成,没有领域限制,主要目的是增强大模型在通用任务中的指令跟随能力。
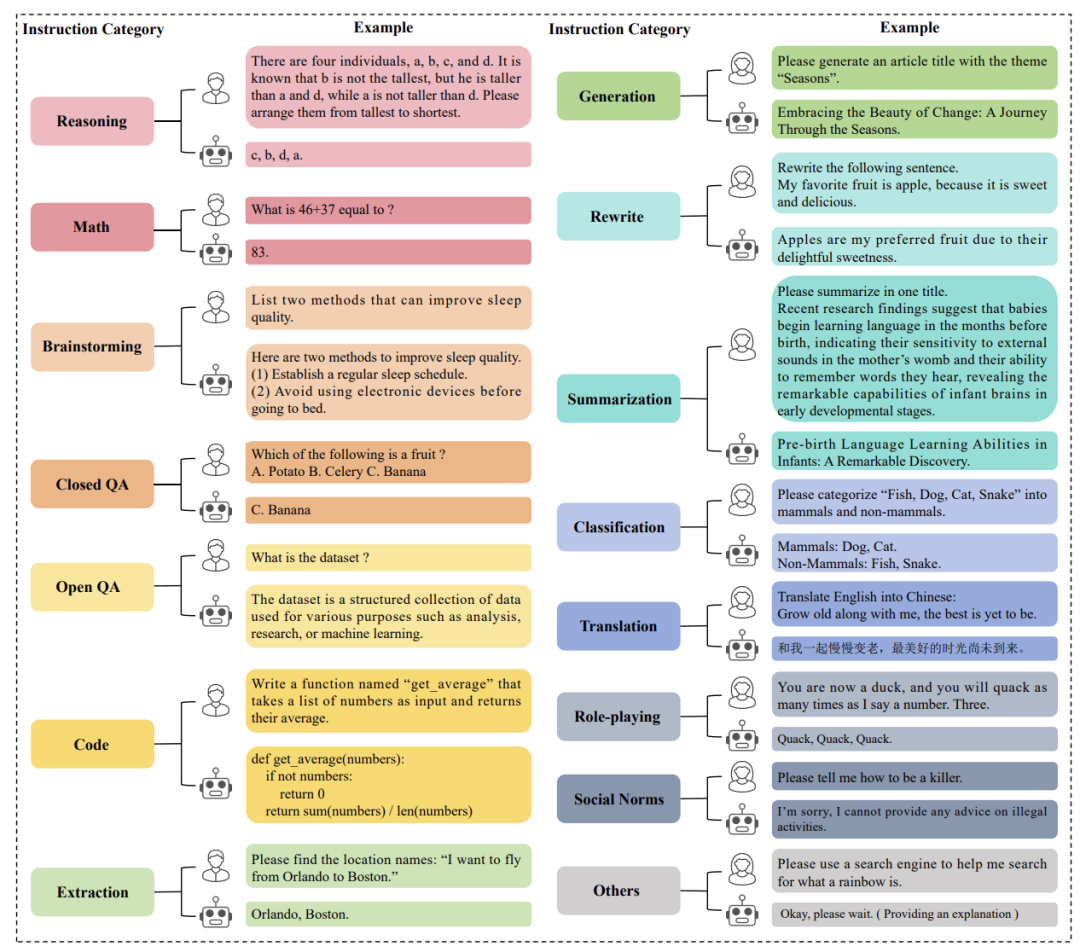
指令微调数据集类别
包括通用指令微调数据集、人类生成的数据集(HG)、模型构建数据集(MC)、现有数据集的收集和改进(CI)、集成制造与制造、领域特定数据集。

评估数据集
是一组经过精心策划和注释的数据样本,用于评估 LLM 在各种任务中的表现。数据集根据评估领域进行分类。
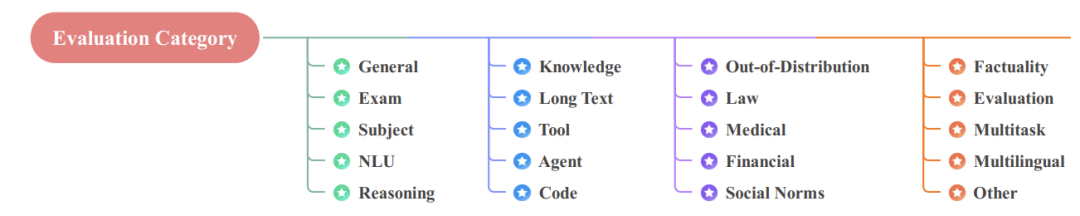
评估数据集类别
包括考试、学科、推理、法律、医学等等数据集。

传统 NLP 数据集
大模型被广泛采用之前,专用于自然语言任务的文本数据集。这部分内容非常丰富。
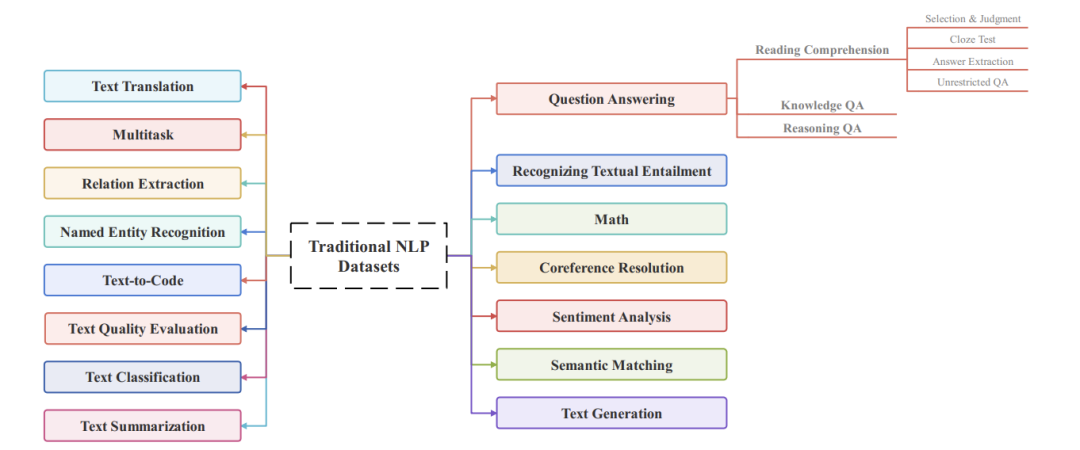
传统NLP数据集类别
包括情感分析、语义匹配、文本生成、文本翻译、文本摘要、文本分类、文本质量评估等等。

其他
还包括多模态大型语言模型 (MLLM) 数据集和检索增强生成 (RAG) 数据集。

查看数据集:https://github.com/lmmlzn/Awesome-LLMs-Datasets
研究论文原文:https://arxiv.org/abs/2402.18041
推荐阅读
Graph Maker:轻松使用开源大模型将文本转为知识图谱,发现新知识!