
Awesome-Chinese-LLM 整理了开源的中文大模型相关资源,包括开源底座模型、垂直领域微调模型应用、数据集及教程等。
目前,收录的资源已超过100个,涵盖了从小型到大型的多种模型,如ChatGLM、LLaMA、Baichuan、Qwen等。以规模较小、可私有化部署、训练成本较低的模型为主。
项目作者@HqWu-HITCS。

项目价值
项目提供了最全中文大模型资源,你可以在这里找到垂直领域微调大模型,以及详细的使用指南,包括如何下载模型、进行本地推理、快速部署以及如何通过量化来优化模型的推理速度和显存占用。
此外,项目还提供了基于不同平台和框架的部署教程,例如使用llama.cpp、Transformers、text-generation- webui、LlamaChat、LangChain等。

部分内容简介
1. 典型底座大模型
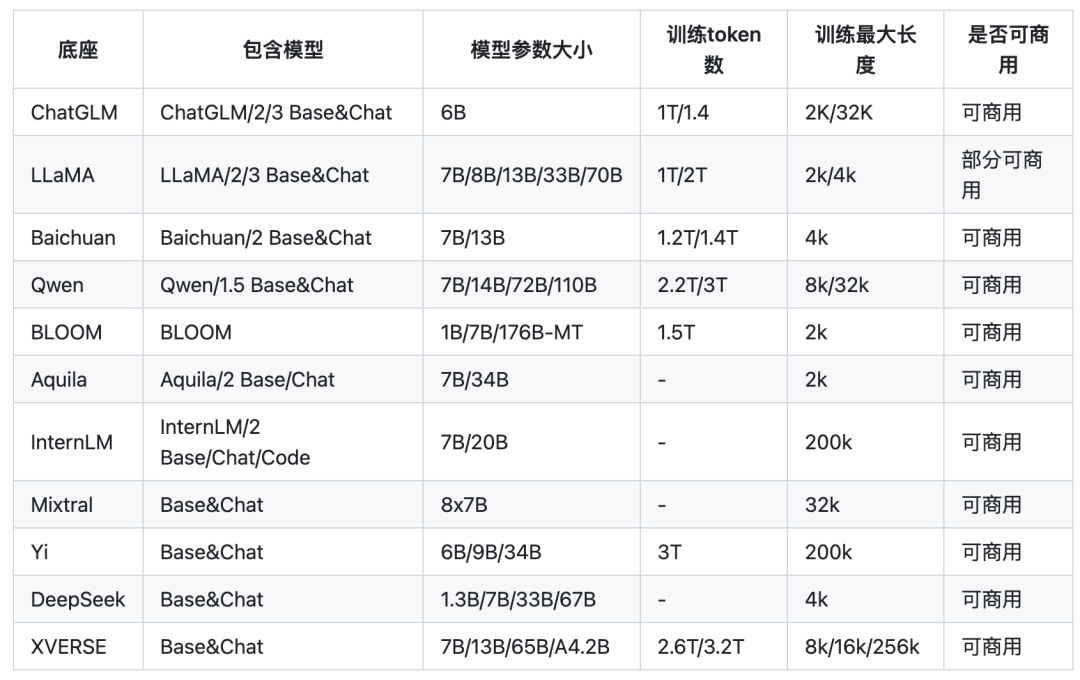
表 作者@HqWu-HITCS
ChatGLM
地址:https://github.com/THUDM/ChatGLM-6B
简介:中文领域效果最好的开源底座模型之一,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持。
垂直领域微调模型
涵盖医疗、法律、金融、教育、科技、电商、网络安全、农业等。
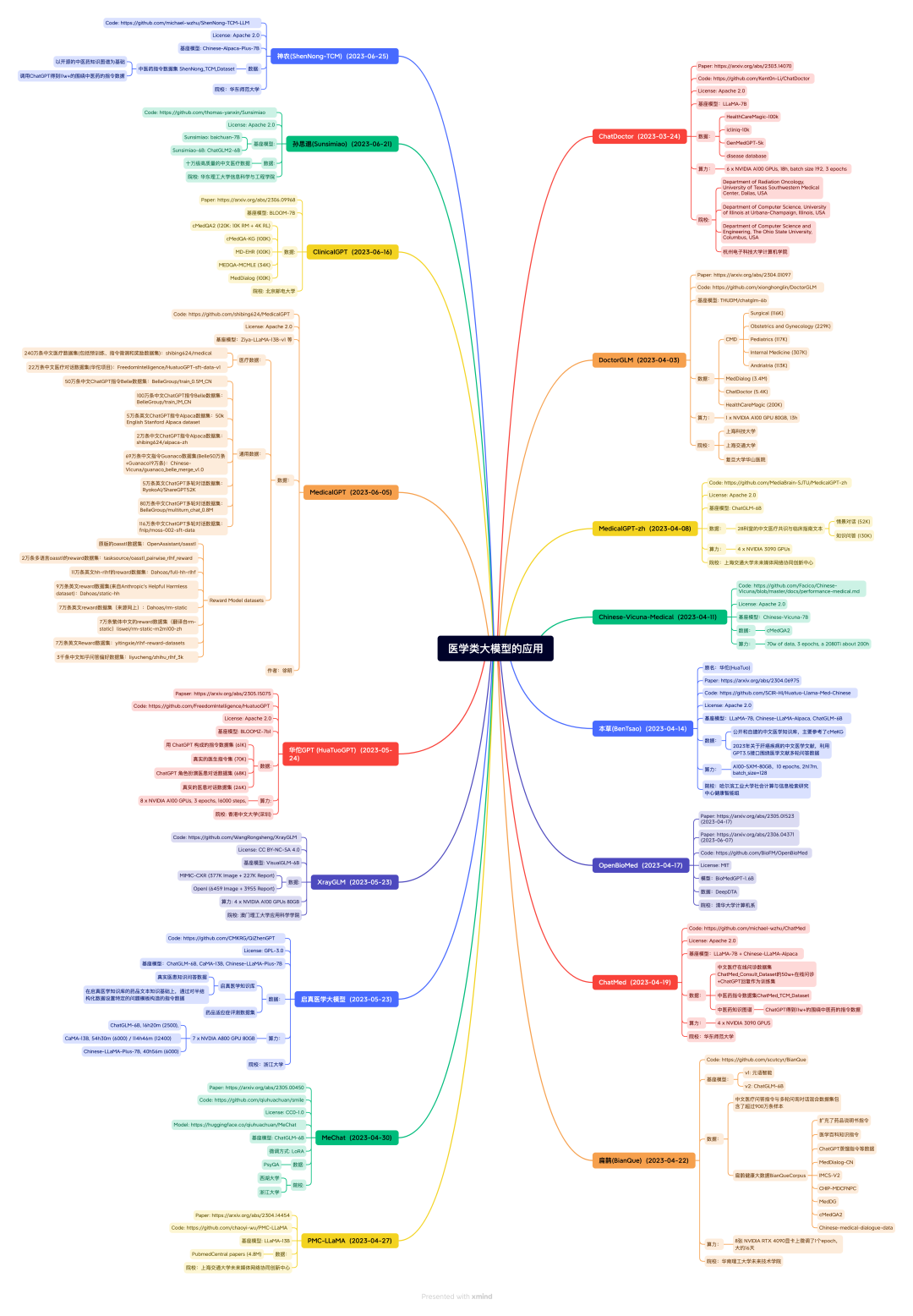
图作者@HqWu-HITCS
医疗:DoctorGLM
地址:https://github.com/xionghonglin/DoctorGLM
简介:基于 ChatGLM-6B的中文问诊模型,通过中文医疗对话数据集进行微调,实现了包括lora、p-tuningv2等微调及部署。
法律:獬豸(LawGPT_zh)中文法律对话语言模型
地址:https://github.com/LiuHC0428/LAW-GPT
简介: 由ChatGLM-6B LoRA 16-bit指令微调而得。数据集包括现有的法律问答数据集和基于法条和真实案例指导的self- Instruct构建的高质量法律文本问答,提高了通用语言大模型在法律领域的表现,提高了模型回答的可靠性和专业程度。
金融:FinGPT
地址:https://github.com/AI4Finance-Foundation/FinGPT
简介:该项目开源了多个金融大模型,包括ChatGLM-6B/ChatGLM2-6B+LoRA和LLaMA-7B+LoRA的金融大模型,收集了包括金融新闻、社交媒体、财报等中英文训练数据。
网络安全:SecGPT
地址:https://github.com/Clouditera/secgpt
简介:开项目开源了网络安全大模型,该模型基于Baichuan-13B采用Lora做预训练和SFT训练,此外该项目还开源了相关预训练和指令微调数据集等资源。
LLM教程
LLMsPracticalGuide
地址:https://github.com/Mooler0410/LLMsPracticalGuide
简介:该项目提供了关于LLM的一系列指南与资源精选列表,包括LLM发展历程、原理、示例、论文等。
OpenAI Cookbook
地址:https://github.com/openai/openai-cookbook
简介:该项目是OpenAI提供的使用OpenAI API的示例和指导,其中包括如何构建一个问答机器人等教程,能够为从业人员开发类似应用时带来指导。
llm-action
地址:https://github.com/liguodongiot/llm-action
简介:该项目提供了一系列LLM实战的教程和代码,包括LLM的训练、推理、微调以及LLM生态相关的一些技术文章等。