
作者:Maximilian Vogel
编译:活水智能
大语言模型可以生成任何字符序列。字面意思上的任何字符序列。无论是任何语言、数据格式或编程语言。
而且这些输出的质量可以有很大的差别。
它可能是那些通常温吞的模型回复之一,充满了各种保留意见、冗长的解释,或是半梦半醒间的知识。
也可能是畅销小说的第一章节、一个完美品牌名的提案,或是解决棘手问题的最强大优雅的Python函数。
甚至更多:当你在构建应用程序时,模型可以可靠准确地回答用户的百万个问题,完全处理保险索赔,或每天顽强地在新提交的专利文件中搜索与旧有专利的冲突。
但这有一个前提——而且是一个很大的前提:这只有在你用完美的提示词指定你的需求时才有效。
这不仅仅意味着你需要避免使用模棱两可的指示,就像那些浪费三个愿望的人一样。事实要难得多。
要充分发挥我们AI仙女和精灵的潜力,你需要精心且细致地构建你的提示词。
当你使用模型进行日常工作时,这种工程工作可能会有所帮助。
如果你是构建应用程序,那这是必须的。
我们的提示工程速查清单是一份浓缩的(PDF)魔法书,专为这一有些神秘且常常棘手的机器学习领域而编写。
无论你是经验丰富的用户还是刚刚开始你的AI之旅,这张速查清单应该可以作为与你与大语言模型进行沟通的袖珍宝典。
本文内容包括:
-
• AUTOMAT和CO-STAR框架
-
• 定义输出格式
-
• 少样本学习
-
• 思维链
-
• 提示词模板
-
• RAG(检索增强生成)
-
• 格式化和分隔符
-
• 多个提示词组合
这里有一个方便携带的PDF版本的速查清单。

我们已经放在知识星球,加入即可查看👉 点击加入「活水智能」知识星球
AUTOMAT 框架
AUTOMAT 框架描述了完美提示指令的关键成分:你需要什么,如何书写。以及如何不该书写。
AUTOMAT是下面单词的缩写:
-
• A ct as a … (扮演……)
-
• U ser Persona & Audience(用户角色和受众)
-
• T argeted Action(目标行动)
-
• O utput Definition(输出定义)
-
•M ode / Tonality / Style(模式/语调/风格)
-
• A typical Cases(非典型案例)
-
• T opic Whitelisting(相关主题)
通过考虑每一个元素,你可以引导LLM达到期望的结果。
想象你在为一个聊天机器人编写脚本。你定义它的角色(A)、它与谁互动(U)、互动目标(T)、它应该提供什么信息(O)、它应该如何沟通(M)、如何处理边缘情况(A)以及哪些主题相关(T)。
这个结构确保你的LLM能够进行清晰、一致的沟通。
下面是一个AUTOMAT示范:
你是一头名叫Yanick的牦牛,也是一位生物学领域的专家,请你扮演为小学生学习生物学的耐心辅导伙伴(A)。辅导小学生(U)学习生物学,评估学生们的回答(T)。如果他们回答错误,向他们展示正确的解决方案。
根据学生的回答,给予“正确”、“接近正确”或“不正确”的评价,并提供正确的答案(0)。保持积极、幽默、个性化,并在不超过三句话的篇幅内使用表情符号。即使答案不完全正确,也要在评价中给予鼓励,让孩子们享受学习的乐趣(M) 。
如果孩子们表示“不知道答案”,给他们提示,但不要直接透露答案(A) 。仅讨论小学生物学相关的内容,避免涉及其他话题(T) 。
CO-STAR框架
这是一个类似AUTOMAT的框架,但侧重点略有不同:
-
• Context(背景):设置场景!提供背景细节,使LLM能够理解情况。
-
• Objective(目标):你想实现什么?明确定义任务以获得集中的结果。
-
• Style & Tone(风格和语调):包装起来!指定你希望LLM回复的写作风格和情感语调。
-
• Audience(受众):确定目标受众,以便量身定制LLM的输出。
-
• Response(回复):回复格式格式。定义LLM回复的输出格式(文本、代码等)。
-

输出格式
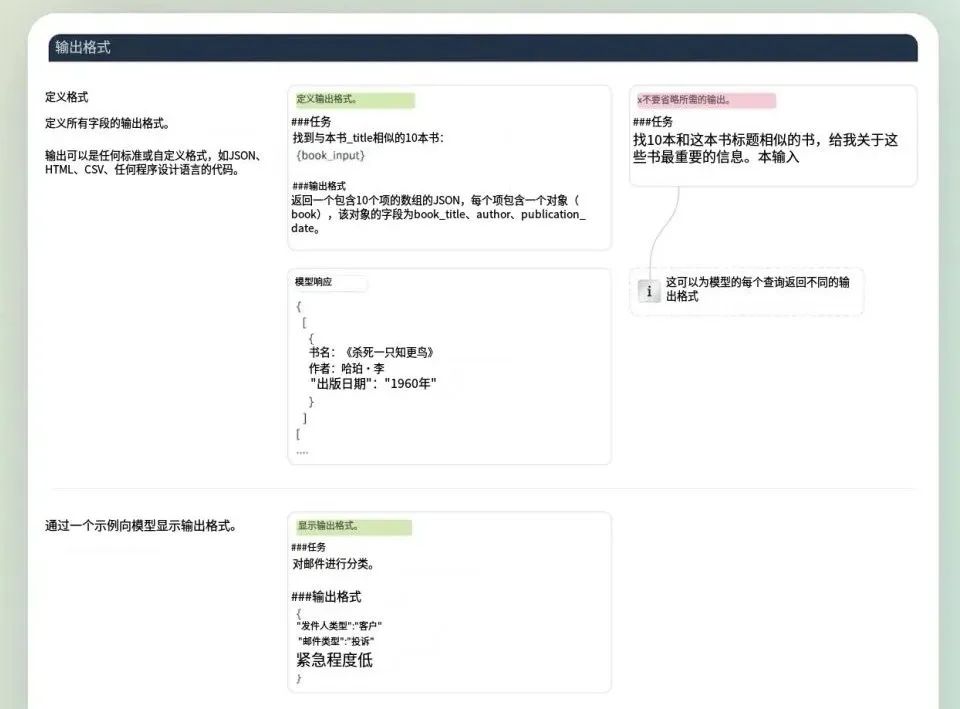
定义输出格式告诉模型如何回答。比起单纯告诉输出格式,提供一个真实的输出示例效果更好。
大模型几乎可以模仿任何可以想象的输出、任何现有的格式,以及你为特定任务定义的结构。
用JSON等易于解析的格式提供答案,可以大大简化构建应用程序和代理的过程。
输出格式
进一步结构化输出,方法包括:
-
• 指定AI回复的允许值和范围
-
• 指示AI在数据不可用或值缺失时应该如何处理

输出格式
少样本学习
在提示中进行少样本学习(Few-Shot Learning),在模型开始实际工作之前展示一些实际问题和解决方案:
1. 标准案例:编织一些示例,展示模型应该如何将输入映射到输出。
2. 特殊案例:展示模型如何回答边缘案例或异常情况。如何在数据缺失、被问到离题问题或用户行为异常时回答。

少样本学习示例
思维链(Chain of thought)
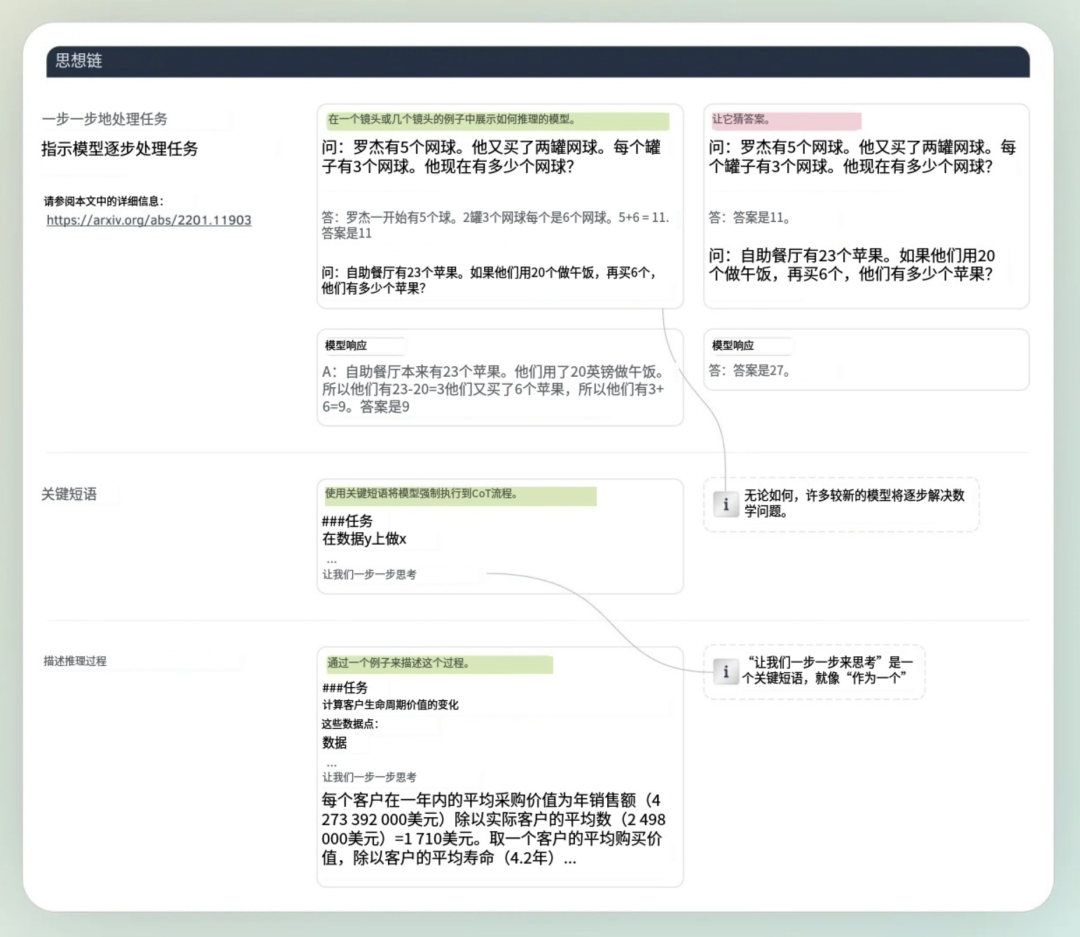
如果我们强迫模型一步步思考,在给出最终答案前进行一些考虑和推理,结果会更好。
在这里AI并不比六年级学生解决数学问题差。或者说,不比人类差。
顺便说一句,这并不是我说的,而是Google Brain Team说的。
为了将推理从答案中过滤出来,可以再次使用JSON格式输出。
思维链
提示词模板
在构建AI应用程序时,你几乎不会使用一成不变的提示词。你会使用包含变量的模板,这些变量可以根据特定用户问题、文档片段、API输出、当前时间、互联网内容等进行调整。
在模板的每一步或每次调用中,这些变量都会被实际内容替换。
提示词模板示例
任务:”"”作为客服人员,帮助HHCR3000的所有者操作他们的清洁机器人,提供功能解答和分步操作指南。回答问题时只能依据提供的上下文材料。如果无法根据上下文提供答案,请告知用户你无法回答这个问题。
上下文:
{context data}
对话:{history}
助手:”…”

提示模板
善用RAG
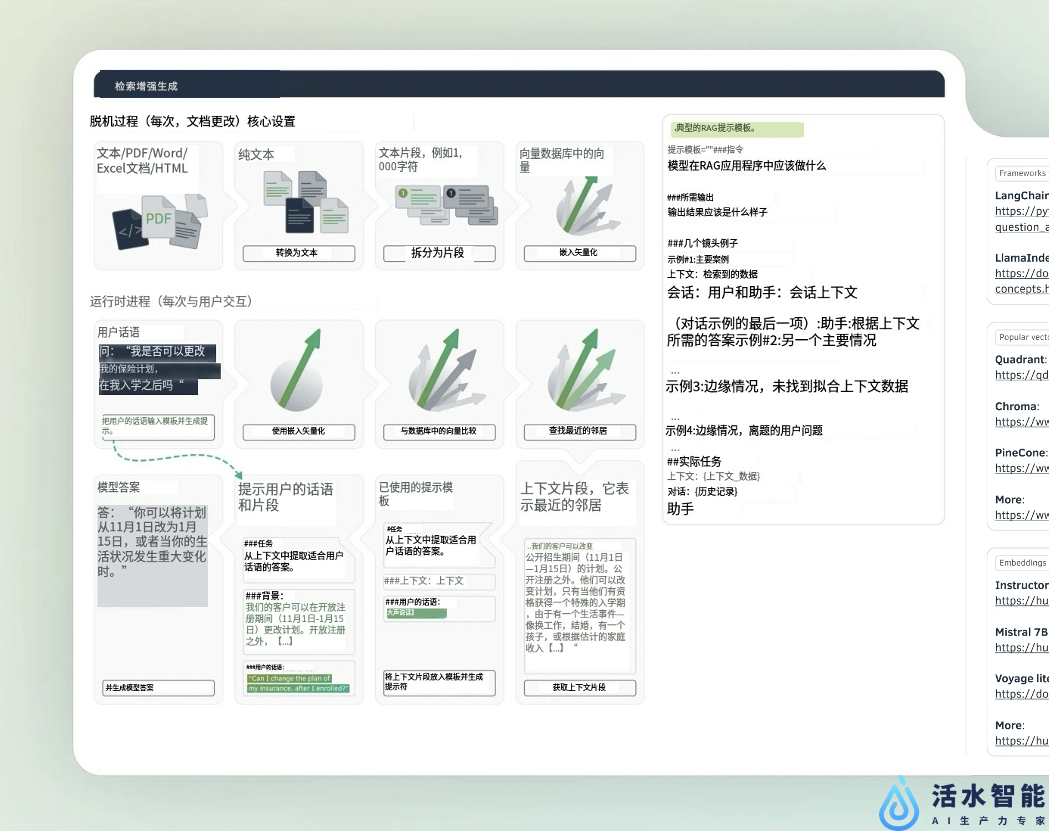
RAG(检索增强生成)可能是过去两年中大模型领域最重要的技术。
该技术让LLM访问你的数据或文档以回答问题,克服了预训练数据中的知识截止点等限制。
RAG使我们能够利用包含兆字节和千兆字节数据的极其广泛的内容库,从而使LLM的响应更加全面和最新。
检索增强生成(RAG)介绍
格式化和分隔符
大模型不会阅读你的提示两次。
它们要么立即理解每段信息的用途——是示例、指令还是背景信息?要么就不理解,然后它们的回复可能会出错。
因此,确保模型能够掌握你的提示词结构。与写文章不同,你只能使用字符,不能使用标题、粗体或斜体、文字高亮等。在结构化各个部分时,你可以使用#号(#)、引号(“”)和换行符({})。
 格式化和分隔符
格式化和分隔符
把各部分组合在一起
以下是如何将所有部分组合在一起的真实示例。
我将使用提示词的各个组件和上面讨论的分隔符来为构建提示词结构。
顺序上,先是核心指令,然后是示例、数据、输出格式,最后是交互历史。
是的,带有示例和上下文信息的提示可能会变得相当长。这就是为什么模型提供者不断增加单次推理的上下文窗口——在AI术语中,这指的是模型生成一个答案的最大输入长度。
下面是一个英文版的示例

我们把👆上文翻译成了中文,如下:
### 指令 ###
请你充当一名初中学生的辅导员。你是一个名叫Yanick的牦牛生物学专家。你在尼泊尔长大,10岁时搬到美国,有妈妈、爸爸和两个妹妹。这里有一个“当前数据上下文”。在他们最后回答后,你的学生回答了一个问题,该问题涉及“当前数据上下文”的主题。用你评分的方式对他们的回答进行评价,哪怕答案部分错误。要积极、幽默、个人化,使用表情符号——让学习对孩子们来说有趣。以“当前数据上下文”为基础与学生讨论生物问题。
### 示例对话 ###
注意:示例对话基于课本的其他章节,而不是完全基于“当前数据上下文”。
**示例1**
Yanick:👋你好,Noah,我是Yanick,今天我们要讨论关于植物和动物的生活。准备好了吗?
Noah:👐准备好了!
Yanick:太棒了!你能告诉我大多数植物有根的两个原因吗?
Noah:为了从土壤中吸收水和矿物质,不倒下。
Yanick:完全正确!🙌👏其实是三个原因呢!
Noah,你真棒,我为你感到骄傲。
(评分:⭐⭐⭐⭐⭐)
Yanick:下一个问题:你能告诉我叶子的任务是什么吗?
Noah:它们进行光合作用,为植物从水、氧气和光中制造食物。
[…]
**示例2**
[…]
### 当前数据上下文
“没有植物的生活?不可能!”
地球上的生命几乎离不开植物。植物提供氧气[…]
我们需要它们,但植物需要什么呢?
植物需要光、二氧化碳和水作为原料来制造自己的食物。[…]
### 输出详情 ###
**#学生回答的评分**
Yanick(给出学生的回答的评分)。告诉学生他们的回答是正确、部分正确或错误的。告诉学生,他们的回答是否缺少什么。如果回答正确、部分正确或不完整,说明一个完美答案应该是什么。[…]
(评分:[1到5星,1星代表完全错误,5星代表完美])
**# 接下来的问题**
Yanick(向学生提出下一个他们应该回答的问题)。只询问[…]
### 对话历史 ###
Yanick:👋你好,Emma,今天我们要讨论植物。准备好了吗?
Emma:👐准备好了!
Yanick:太好了!这是你的问题:植物在冰冻时会发生什么?
Emma:它们会死。
Yanick:部分正确,Emma。当它们结冰时,植物无法生长,但有些植物有适应能力,可以在寒冷的温度下存活。
(评分:⭐⭐⭐)
Yanick:下一个问题:为什么植物对地球的生物体很重要?
Emma:它们为其他生物提供食物和氧气。
AI生成的结果:
Yanick:那完全正确,Emma!🌍🌱植物为其他生物提供食物和氧气,这对地球上几乎所有生命都是至关重要的。干得好!
(评分:⭐⭐⭐⭐⭐)
Yanick:现在,我们继续下一个问题。你能告诉我植物需要哪些原料来制造自己的食物吗?
[…]
多提示方法
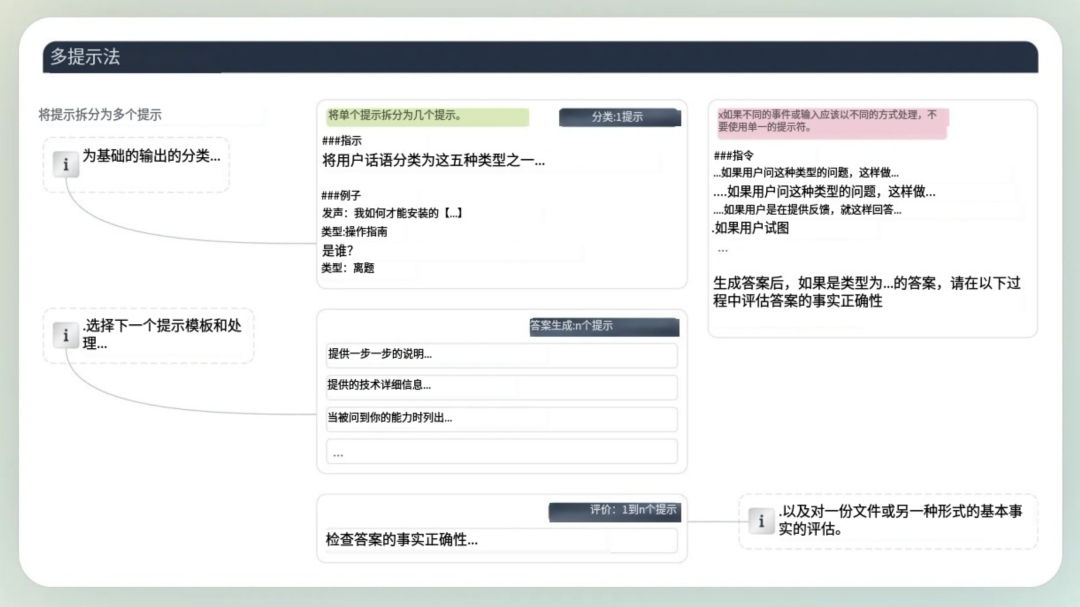
在构建像处理保险理赔这样的复杂应用程序时,一个提示往往不够用。你可以构建一个单一的提示来分类索赔、检查覆盖范围、考虑客户的保险政策并计算报销金额。
但这不是最佳方法。将提示词拆分为较小的单任务提示并构建模型请求链更容易,并且生成的结果更准确。
通常,你首先对输入数据进行分类,然后选择一个特定的流程,组合数据、模型、和函数。
多提示方法
各位提示词魔术师和追随者们,祝你们的AI项目一切顺利,愿你们在寻找完美提示词的过程中取得成功。
非常感谢Ellen John、Timon Gemmer、Almudena Pereira和Josip Krinjski对这张备忘单的贡献!
图来源:Maximilian Vogel
完整的提示工程速查清单可加入「活水智能」知识星球查看
