来源:Educating Silicon
编译:活水智能
大型语言模型,如Llama 3和GPT-4,都是基于庞大的文本数据集进行训练的。下一代模型需要的数据量将是现有的10倍。这是否可能实现呢?
为了尝试回答这个问题,这里提供了一个对世界上所有文本数据的估计。
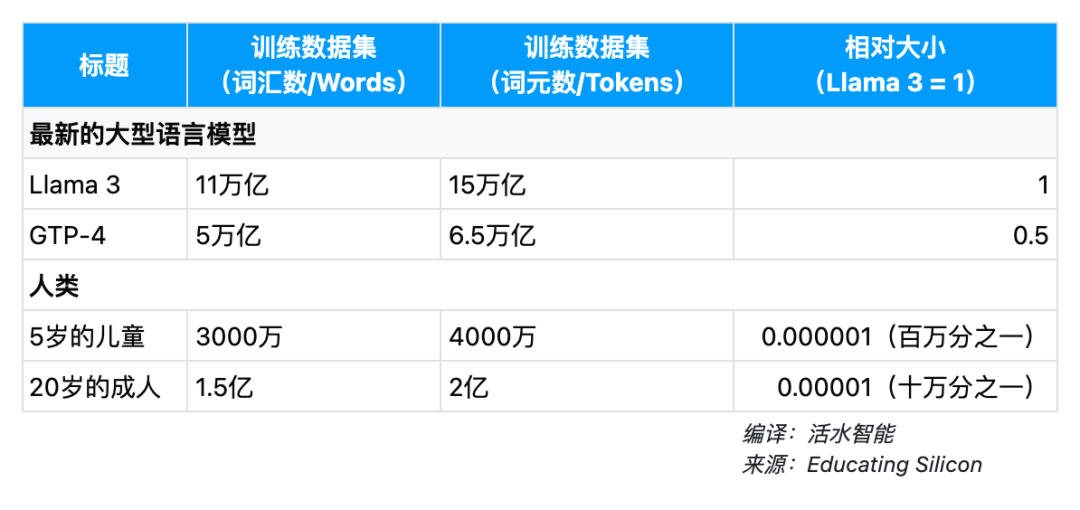
首先,让我们来看看一些最新的大型语言模型训练集的规模,以及与人类接触的词汇数对比:
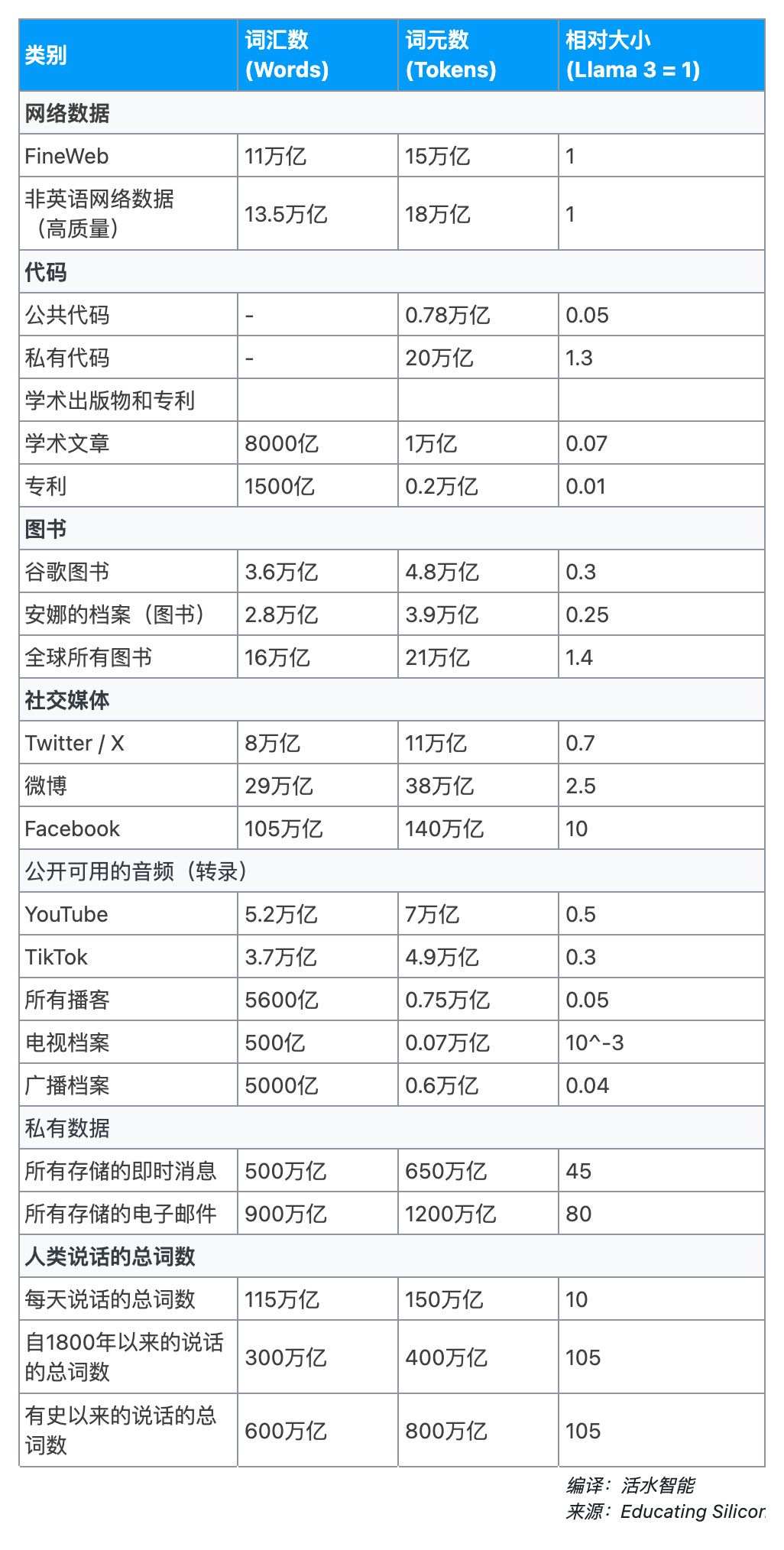
接下来是我对世界上存在的有用的文本数据的估计:
那么,训练数据是否即将耗尽?
在15万亿个词元(tokens)的情况下,当前的大型语言模型训练集似乎已经接近使用了所有可用的高质量英文文本。
或许你可以通过使用不太容易获取的资源(例如更多的书籍、转录音频、Twitter等)达到25至30万亿词元。加上非英文数据,你可能接近60万亿词元。这似乎是上限。
私有数据的规模要大得多。仅Facebook帖子的数据量就可能达到140万亿词元,谷歌在Gmail中大约有400万亿个词元,而所有文本数据加起来可能达到2000万亿个词元。
这些数据对注重个人隐私的人和机构来说是禁区[1],尽管如此,还是值得记住它们的存在。对情报机构或不法行为者来说,这是一个可选项[2]。
假设(A)商业模型制造商不会用私有数据上进行训练,以及(B)需要更多数据来提高性能,那么未来的模型会严重依赖合成数据。
对于那些一直关注大模型训练的人,这个结论并不令人震惊,但我仍然发现具体分析当前数据获取方法的极限是有用的。
表格数据说明
词元 (token)与单词(word)的比例取决于分词器和语言。我假设每个词元约为0.75个单词,这对于使用OpenAI tiktoken的英文文本来说大约是正确的。
这意味着表格中的计数对于非英文来源和像Llama这样使用其他分词器的模型会有所偏差。不过,我们在这里关注的是数量级,所以这些差异并不重要。
最近的大型语言模型训练集
Llama 3
数据来自官方博客文章。无论是8B还是70B模型,都使用了15T的词元训练集。对于转换成单词的数量,我假设了0.75,这可能会有所偏差,因为他们使用的分词器与OpenAI不同。
GPT-4
估计来自EpochAI。引用他们的话:“_推测性的。通过在线资源如Semianalysis间接报告,但未经OpenAI验证。
如果看到的总词元数是13T,文本重复了2个时代,且文本是词元的主体,那么数据集的大小大约是13T*0.75/2 = 4.9T单词。我四舍五入到了5T。
n-gram模型(2007年)
出于历史兴趣,我注意到谷歌在将近二十年前就在2万亿个词元的普通网络数据上训练了一个n-gram模型。
他们至少一直使用这个模型到2013年,训练集的大小保持不变[3]。因此,现代大型语言模型的训练集并不是前所未有的大。
人类接触的词汇数
5岁的儿童
早期儿童听到的单词总数在文献中已经被充分研究。良好的估计显示,到5岁时,孩子们将听到2500万~5000万个单词。
20岁的成人
我的估计。假设上述儿童时期的数据在以后的年份仍然有效,人们每年大约会听到500万个单词。
此外,一个每周读完一本书的热心读者可能每年会阅读大约500万个单词。因此,到20岁时,他们将听到或读到大约1亿至2亿个单词。
网络文本
Common Crawl
Common Crawl 数据集常被用作训练大模型的基础数据集。有时候,人们误以为它包含了互联网上的所有信息,将其誉为“涵盖整个网络数据集”。实际上,Common Crawl 并没有那么全面,但它确实覆盖了大量的公开HTML网页内容。
它遗漏了动态渲染的网站、PDF内容、任何需要登录的内容等。谷歌肯定内部拥有更全面的数据。尽管如此,它仍是一个非常大且方便的大规模网络数据来源。
就词元数量而言,原始的Common Crawl 至少有100万亿个词元。我没有计算出更精确的数字,因为对我们的目的来说这个数字相当无意义。
原始数据充满了垃圾和重复内容,因此任何用于大型语言模型(LLM)训练的实际用途都将从重度过滤开始。
FineWeb
包含15万亿个词元。它是自2013年以来Common Crawl转储的过滤后的英文子集。我将其视为Common Crawl所有有用英文网络文本的合理代表,因为它是最近的并且过滤得相当好。
有更大的数据集(例如 RedPajama-Data-v2 是30万亿词元),但额外的词元质量较低,因此价值有限。
非英语网络文本
FineWeb 完全是英语的,Common Crawl 只有45%是英语。因此,应该有18万亿词元的其他语言文本具有可比的质量。
代 码
公开可访问的代码
Stack v2 是一个涵盖大多数公开可访问代码的数据集。它在最大的变体中包含7750亿个词元,尽管如果你想要常见语言和更严格的近乎重复移除,那么大约是一半。
它基于软件遗产档案,该档案包括所有主要代码托管平台的所有公开可访问代码,不论许可证。
所有代码
对有史以来编写的所有代码总量的估计通常在1万亿到约3万亿行之间。一个快速的估计[4]表明大约每行10个词元,因此总共大约有10万亿到30万亿个代码词元。
乍一看这个数字似乎难以置信的大,考虑到FineWeb的大小差不多。我们几乎有0.8万亿个公开代码词元,所以总体上大约是这个数字的20倍似乎是合理的。
大部分代码是私有的,而且很大一部分可能已经永远丢失,因此对于大多数大模型的目的来说它的相关性有限。不过,作为一个上限数字,了解这个数字还是有用的。
学术出版物和专利
学术文章
根据2014年的一项估计,网络上有大约1.14亿篇英文学术论文。在大多数学术领域,英文论文占据了绝大多数,据推测,这一比例在75%到90%之间。因此,2014年的总出版量可能约为1.4亿篇。
过去十年,出版速度有了大幅增长,每年的出版量在400万到500万篇之间。这意味着截至2024年,总出版物数量约为1.8亿篇,其中75%为英文。一篇出版物的平均长度大约是4500个词。
因此,总计约有8000亿个词或1万亿个词元。由于几乎所有的论文都是PDF格式,因此相当一部分需要进行OCR(光学字符识别)才能提取。许多论文还设置了付费墙,尽管通过像Anna’s Archive这样的影子图书馆可以访问大约1亿篇。
专利
谷歌专利包含了1300万项授权专利(可追溯至1790年)和770万项申请(自2001年以来)。现代专利申请的平均长度大约是12000个词。
申请和授权之间存在一些重叠,而且随着时间的推移,专利的规模也在增长。总体来看,这可能相当于1500亿个词或2000亿个词元。
书 籍
谷歌图书
在2019年的官方博客文章中表示,他们拥有4000万册扫描图书。他们现在几乎不再扫描图书了,所以这个数字可能仍然是当前的。我基于此处的假设,每本书平均有90000个词,这意味着总共有3.6万亿个词或4.8万亿个词元5。
国会图书馆
我把它作为一个规模参考。它的大部分内容都包含在谷歌图书中,所以它不是一个独立的来源。图书馆拥有3900万印刷图书和1.67亿件藏品。使用与上面相同的单词计数假设,我们得到3.5万亿个词或4.7万亿个词元。
影子图书馆
最大的影子图书馆,如Anna’s Archive,包含3100万本图书,相当于2.8万亿个词或3.9万亿个词元。我不知道这在多大程度上与谷歌图书重叠,但肯定远远少于100%。
谷歌对历史印刷图书的扫描工作是独一无二的,据我所知,从未被抓取过,而Anna’s Archive主要包含较新的电子书。
全世界所有书籍
我使用了谷歌在2010年的估计,当时全世界大约有1.3亿种不同的书名,以及这里的估计,主流出版每年增加约50万到100万种书名,但如果包括自我出版的作品,则高达400万种。
我已经包括了后者,这意味着截至2024年,大约有1.8亿本图书。假设每本书有90000个词,那么总共约有16万亿个词,或21万亿个词元。
社交媒体
推特 / X
推特在2014年报告称,平均每天有5亿条推文。据我所知,没有更新的数据,因此我们就以这个数据作为当前的速率6。据估计,大约25%的推文来自机器人,剔除这些后,每天大约有3.75亿条推文。
推特在2018年发布的数据显示,一条推文的平均长度是33个字符,大约相当于6个词7。这意味着每年有0.8万亿个单词。推特已经有20年历史,并且至少在过去10年里每天的推文量相似。因此,我们保守估计仅计算过去10年:总共有8万亿个单词或11万亿个词元。
推特(和大多数其他动态渲染的网站)不包含在Common Crawl中,所以这些数据是FineWeb中所找不到的。当然,推特上的文本是“奇怪的文本”,只有一部分对于LLM训练目的来说是高质量的。
作为一个用户,我发现一旦你习惯了它,信噪比是很高的,所以这些词元中有相当一部分原则上是有用的。
微博
微博的指标与推特非常相似。这两个平台的年龄差不多,日活跃用户数也相似。这项研究发现微博用户平均每天发表1.2次帖子,或者排除转发后是0.85次,与我们发现的推特的1.5次相似。
一个区别是,平均帖子长度是55个字符,考虑到中文每个字符的信息密度更高,这大约相当于每帖38个词,几乎是推特的6倍。按此比例计算,我得到微博有29万亿个词或38万亿个词元。相当可观!
Meta(Facebook和Instagram)
Facebook在2015年的一篇官方博客文章中表示,截至那时,有2万亿可搜索的帖子。那时,Facebook刚过10岁,有15亿用户。
2004-2014年期间的平均用户数约为6亿,这意味着每用户每天大约有0.9次帖子。这个数字对我来说似乎很高,但Facebook在这一时期正处于其高峰。
在撰写本文时,Facebook大约有30亿用户,2015-2024年期间的平均用户数约为15亿。如果我们假设每用户每年的帖子数量保持不变,那么我们得到的帖子总数略高于6万亿。
根据传闻,近年来Facebook上的公开发帖活动大大减少,因此这可能是一个高估。不过,总数肯定在2万亿到6万亿之间,对我们的目的来说这是一个相当狭窄的范围。我不确定这个数字是否包括回复,或者仅仅是主要帖子。
考虑到最初的数据来自搜索索引,我猜测回复没有被索引。Instagram也没有计算在内,尽管它的文本较少。这两个因素都会推高总数,可能会大大提高。然而,让我们还是以6万亿作为一个基于现有数据的合理估计。
Facebook的平均帖子有大约17.5个词。所以这意味着有105万亿个词,或140万亿个词元。质量和隐私考虑意味着这些数据可能对LLM训练不是那么有用。
对于Meta最近的Llama 3模型,据报道,“尽管扎克伯格吹嘘它的语料库比Common Crawl的全部还要大,但没有使用Meta用户数据”。这与我们估计的相符。
最后,如果Instagram Reels在规模上与TikTok相似(见下文),转录的音频可能会增加另外5万亿个词元。
公开可用的音频资源
YouTube
最近一个学术项目进行了仔细估算,截至2024年,YouTube上的公开视频数量达到了147亿(研究论文在此处,一些彩色插图在此处)。
接下来我们需要知道这些视频中有多少包含了语音。
根据论文内容:“96.81%的视频含有一些音频。在这些视频中,40.56%被认为完全或几乎完全是音乐。53.87%的视频在第一分钟内含有口语。有18.32%的视频中出现了对着摄像机说话的人,9.13%的视频包含了公共或半公共事件的镜头。”
因此,54%的视频含有一些口语,而18%的视频主要集中于某人的讲话。我们可以假设大约25%的YouTube视频能为大型语言模型(LLM)训练提供有用的数据。
视频的平均时长为615秒(尽管中位数为60秒,因此少数非常长的视频对此有很大影响)。假设每分钟140个单词,这就产生了5.2万亿个单词。
TikTok
TikTok在其透明度报告中披露了数据。如果我理解正确的话,从2020年7月到2023年12月,TikTok上发布了惊人的1630亿个视频,目前每年的发布速率为700亿。TikTok有10亿用户,其中排名前25%的用户发布了98%的内容。
因此,这部分用户平均每天发布0.76个帖子。这个数字比我预想的要高,但似乎是合理的。如果我们稍作推断,自TikTok成立以来发布的视频总数可能约为2500亿。
TikTok视频都很短,平均时长大约在35-40秒之间。我不知道有多少百分比的视频包含语音,但我们可以假设为18%,这是YouTube的较低估计。
以每分钟140个单词计算,这就产生了3.7万亿个单词或4.9万亿个词元,与YouTube相似。从大型语言模型训练的角度来看,其中有多少是“高质量”的内容很难说,但TikTok包含了各种内容,因此至少可以假设其中有一部分是有价值的。
播客
基于这个播客统计追踪器,我估计存在1亿集播客节目,该追踪器显示Apple上有9400万集节目。(其他网站列出的集数高达1.5亿,但来源似乎不太可靠)。
我假设的平均长度为40分钟,基于这个估计。以每分钟140个单词计算,这就产生了5600亿个单词。
电视
要找到关于现存独特电视内容总量的确切数据出奇地难。然而,显而易见的是,作为文字来源,电视内容的量是相对较少的。考虑到电视每小时的制作成本相对于YouTube来说要高得多,这一点并不令人意外。
尼尔森列出了截至2023年10月,美国观众在所有平台上可获得的1.1百万个独特视频标题。这包括流媒体服务上的大量旧目录。这相当于大约40亿至50亿个单词,与我们考虑过的其他来源相比,这几乎可以忽略不计。
由于政府监管,英国有很好的统计数据,他们列出了每年生产的27000小时的国内内容,这相当于1.5亿至2亿个单词。
即使我们允许存档50年(这似乎不太可能,可以假设50年前生产的小时数要低得多),这也只相当于英国电视历史上总共100亿个单词。
全球档案的总量似乎最多可能是几千亿个单词。你能用于大型语言模型(LLM)训练的数量可能只有数百亿。我猜测是500亿,但这个数字带有很高的不确定性,不过由于源头如此之小,这里的精确度并不重要。
广播
全球广播电台的总数估计在44000到66000之间。当然,很多内容是音乐,大约只有15%是有声内容。如果说话电台每天产生10小时的独特内容,那么全球每年大约有1600亿个单词。
如果有10年的档案记录存在,那就是1.6万亿个单词。如果你能访问50年的档案,并且过去的电台数量和现在一样多(这两者都有些可疑),那么这里可能有多达8万亿个单词。遗憾的是,我怀疑没有这样的档案存在。
我能找到的最大档案是BBC/英国图书馆档案,它有几百万项,以及互联网档案馆的广播部分,大约有五十万项。这代表的单词数量不会超过几十亿。如果像TuneIn这样的互联网广播服务保留了档案,它可能会相当大,但他们似乎并没有这样做。
总的来说,我猜测通过一系列小档案能够访问的单词可能只有几百亿。我会估计是5000亿。
私人数据
所有即时消息
Meta在2023年报告称,它每天通过所有应用程序(WhatsApp、FB Messenger、Instagram)处理超过1400亿条即时消息。WeChat的估计不太可靠,但每天大约有450亿条,考虑到用户基础的相对规模,这个数字似乎合理。
苹果iMessage的数字更难找到,但还算可以的估计是每天大约80亿条。Snapchat似乎是每天40亿至50亿条。我没有尝试找到Telegram、QQ等的数字,因为它们不太可能在数量级上有太大变化。
全球SMS的估计量建议每天有230亿条消息,尽管我找不到可靠的来源,如果以我的个人经验为准,它主要是自动消息或营销,所以我不会将其包括在内。
总的来说,这大约是每天2000亿条消息。这些来源没有指定这是发送的消息还是接收的消息。接收的消息会因为群聊中的一对多发送而被夸大。Meta大约有35亿用户,所以1400亿条每日消息意味着每人每天发送40条消息。
这对我来说似乎太高了,所以我假设这是接收的消息。发送可能是这个数字的50%,这意味着每天有1000亿条消息被发送。
根据这项研究,平均每条WhatsApp消息有5.85个单词。所以总的来说,我们每天大约有0.6万亿个单词,或者0.8万亿个Tokens。
存储消息的总量更难估计。有些是短暂的,没有备份,但这不是最受欢迎平台的默认设置。WhatsApp消息默认由中央备份(直到最近才未加密)。Meta的其他应用程序在账户级别中央存储消息历史。我假设WeChat也是如此。
所以我们可以说,每天大约75%的消息量以备份或日志的形式存储在某处。
消息应用程序在用户数量上已经相当成熟了,大约有3年的存储历史存在于一些公司服务器上。所以所有存储的聊天记录包含将近500万亿个单词或650万亿个Tokens。
所有电子邮件
电子邮件的数量非常庞大。确切的数字很难得到,但全球电子邮件量的估计通常在每天3500亿条左右。其中50%至85%是垃圾邮件。如果我们采用更高的垃圾邮件估计,那么每天就剩下450亿条非垃圾邮件。
我相信这个数字计算了多次发送给多个收件人的电子邮件。所以让我们再减去75%,以此来计算,留下每天110亿条独特的电子邮件。这意味着平均每个互联网用户每天写2封电子邮件,这似乎是合理的。
如果我们假设每封电子邮件平均有50个单词,我们每天在电子邮件中得到0.5万亿个单词。
每天半万亿个单词大致相当于即时消息和电话通话的总量(见下文)。然而,电子邮件的特点是人们倾向于保留更长时间的历史。
用户拥有数年甚至数十年的电子邮件是相当普遍的,而且存储大多是集中的和未加密的。像Gmail这样的流行服务已经有20年的历史了,我个人有一些超过二十年历史的电子邮件。
让我们猜测平均用户有5年的电子邮件。这相当于900万亿个单词。谷歌和微软在一个地方存储了相当一部分数据,尽管出于隐私原因,他们可能永远无法利用这些数据。
所有电话通话
估计每天有135亿个电话通话,平均时长约为1.8分钟。我找到的关于这个的来源不是很好(这里),但它们似乎与其他关于总通话时间的指标大致相符,所以对我们的目的来说足够接近了。
如果我们考虑到一些等待时间和垃圾通话,让我们假设每个通话1分钟的说话时间,以每分钟140个单词计算。这样算来,所有电话通话每天大约有1.9万亿个单词。
据我所知,电话通话内容不会在任何地方大规模保留,除了国家行为者,如美国国家安全局(NSA)。NSA的Mystic项目从2011年开始保留了整个国家(特别是巴哈马和阿富汗)30天的通话内容。
这些项目是否仍在运行是未知的。由于自2011年以来存储和语音识别技术的进步,他们现在可能能够更广泛地保留通话内容。如果他们保留了全球通话内容的10%,并且保留了一年,那将是大约70万亿个单词。
我认为即使没有这样的录音存在,了解这个数量级也是有用的。就我们的目的而言,让我们假设电话通话是短暂的,不计入我们的计数。
其他私人文本
私人文件、公司备忘录等与电子邮件相比是小量的(想想你写电子邮件的频率与写文档的频率)。无论如何,它也不会对我们的计数产生太大影响,而且很难获得任何数据,所以我不会估计这个。
人类说话的总词数
每天说话的总词数
撰写本文时,世界人口约为81亿,其中大约90%的人已经到了会说话的年龄。一些可靠的研究显示,每人每天平均说话词数大约为16,000词。
因此,全球每天的总说话词数约为115万亿。其中大约1%被记录下来,主要是以电子邮件和即时消息的形式。其余的则随时间消逝,就像雨中的泪水。
自1800年以来说话的总词数
自1800年以来,每年出生人数有相当准确的估计。总数接近180亿。调整了寿命年数后,我估计自1800年以来说话的总词数约为3千万亿。
有史以来说话的总词数
最后,自从语言首次进化以来,人类总共说了多少词?深远时代的人口估计颇具挑战性,但一个合理的估计得出的数字是1170亿人。
然而,在早期时期,婴儿死亡率极高,所以这些人中有许多可能没有活到会说话的年龄。考虑到预期寿命,我估计有史以来说话的总词数约为6千万亿。其中近一半的词是自1800年以来说出的。