作者:SEBASTIAN RASCHKA, PHD
编译:活水智能
来源: https://magazine.sebastianraschka.com/p/understanding-large-language- models
大语言模型以一种近乎风暴的方式占据了公众的视野——这里没有双关语。仅仅五年时间,这些模型——尤其是Transformer——已经彻底颠覆了自然语言处理领域。不仅如此,它们还在计算机视觉和计算生物学等领域引发了革命。
鉴于Transformer对研究方向的深远影响,我整理了一份入门阅读清单,帮助机器学习的新手研究人员和从业者快速上手。
主要架构和任务的理解
如果你是Transformer或大语言模型的新手,从基础开始学习是最合理的。
(1) 通过联合学习对齐和翻译的神经机器翻译 (2014),由Bahdanau, Cho和Bengio撰写,https://arxiv.org/abs/1409.0473
我建议从上述论文开始阅读,如果你能抽出几分钟的时间。它为循环神经网络(RNN)引入了一种注意力机制,以增强其长序列建模能力。这种机制使RNN能够更准确地翻译较长的句子,这也是后来开发原始Transformer架构的初衷。
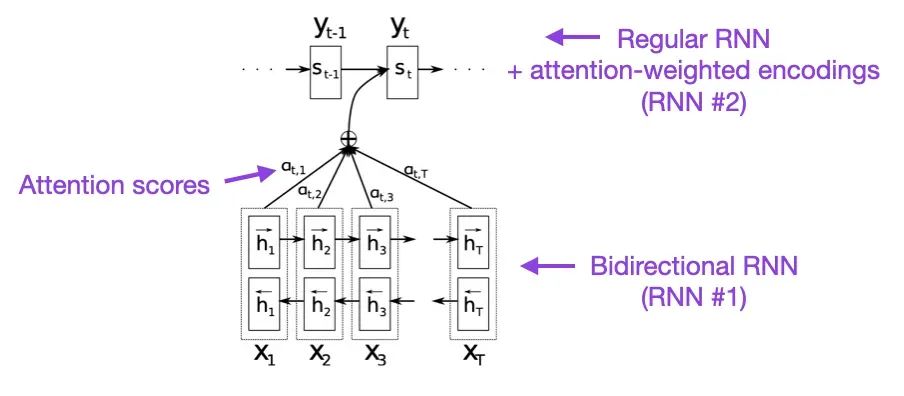
来源:https://arxiv.org/abs/1409.0473**
(2) 只需注意力 (2017),由Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser和Polosukhin撰写,https://arxiv.org/abs/1706.03762
上述论文首次提出了包含编码器和解码器的原始Transformer架构,这在后续将作为独立的模块出现。此外,这篇论文还引入了缩放点积注意力机制、多头注意力块和位置输入编码等核心概念,这些至今仍是现代Transformer的基石。
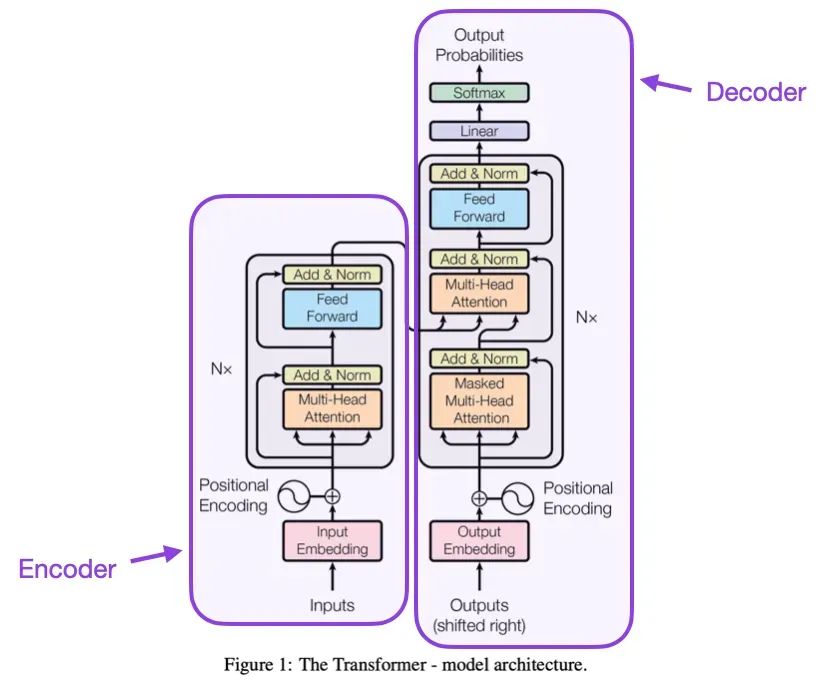
来源:https://arxiv.org/abs/1706.03762
(3) Transformer架构中的层规范化 (2020),由Xiong, Yang, He, K Zheng, S Zheng, Xing, Zhang, Lan, Wang和Liu撰写,https://arxiv.org/abs/2002.04745
尽管原始的Transformer示意图(来自《只需注意力》,https://arxiv.org/abs/1706.03762)很好地总结了原始的编解码器架构,但图中的LayerNorm位置仍有争议。
例如,《只需注意力》中的Transformer图将层规范化放在残差块之间,这与原始论文附带的官方(更新后的)代码实现不符。图中所示的变体被称为Post-LN Transformer,而更新的代码默认使用Pre-LN变体。
Transformer架构中的层规范化论文认为Pre-LN表现更佳,解决了梯度问题,如下所示。许多实际应用的架构采用了这种方式,但它可能导致表示能力下降。
因此,尽管关于使用Post-LN或Pre-LN的讨论仍在进行,也有一篇新论文提出了兼顾两者优点的方法:具有双重残差连接的Transformer (https://arxiv.org/abs/2304.14802);其实用性还有待观察。
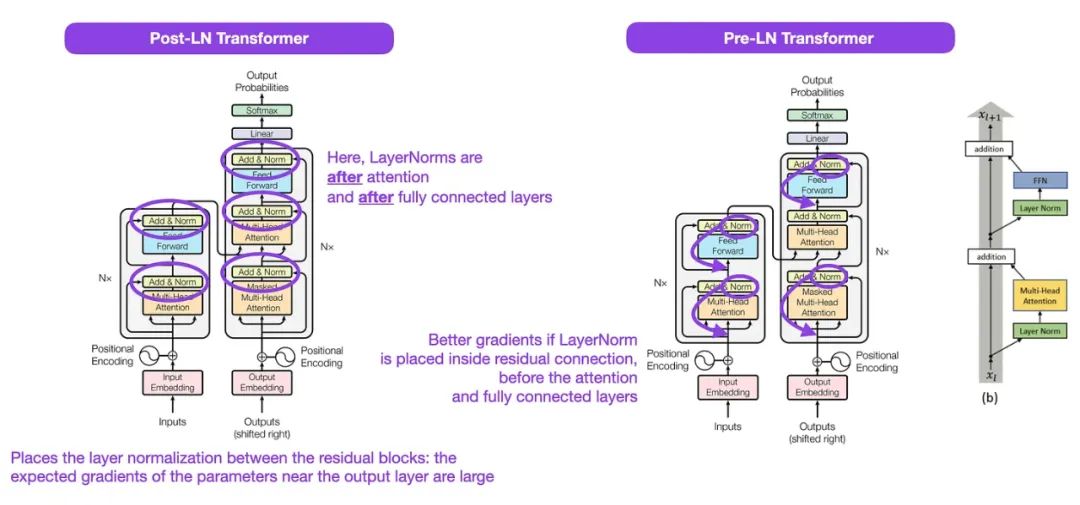
资料来源:https://arxiv.org/abs/1706.03762(左和中)和 https://arxiv.org/abs/2002.04745(右)
(4) 学习控制快速权重存储器:动态循环神经网络的替代方案 (1991),由Schmidhuber撰写,https://doi.org/10.1162/neco.1992.4.1.131
这篇论文推荐给那些对历史小知识和早期方法(与现代Transformer基本相似)感兴趣的人。
例如,在1991年,也就是在《只需注意力》原始Transformer论文发表前约二十五年半,Juergen Schmidhuber提出了一种循环神经网络的替代方案,称为快速权重编程器(FWP)。
这种方法涉及一个前馈神经网络,通过梯度下降慢慢学习来编程另一个神经网络的快速权重变化。
在这篇博客文章中解释了与现代Transformer的类比如下:
在今天的Transformer术语中,FROM和TO被称为键和值。应用于快速网络的输入被称为查询。本质上,查询通过快速权重矩阵处理,该矩阵是键和值的外积之和(忽略了规范化和投影)。由于两个网络的所有操作都是可微的,我们通过加法外积或二阶张量积实现了端到端可微的快速权重变化的主动控制。[FWP0-3a] 因此,慢网可以通过梯度下降学习在序列处理期间迅速修改快速网。这在数学上等价(除了规范化)于后来所称的带线性化自注意力的Transformer(或线性Transformer)。
正如上述博客文章所述,这种方法现在被称为“线性Transformer”或“带线性化自注意力的Transformer”,通过2020年在arXiv上出现的更多近期论文Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention 和 Rethinking Attention with Performers进行说明。
2021年,线性Transformer实际上是快速权重编程器论文则明确展示了线性化自注意力和1990年代的快速权重编程器之间的等价性。
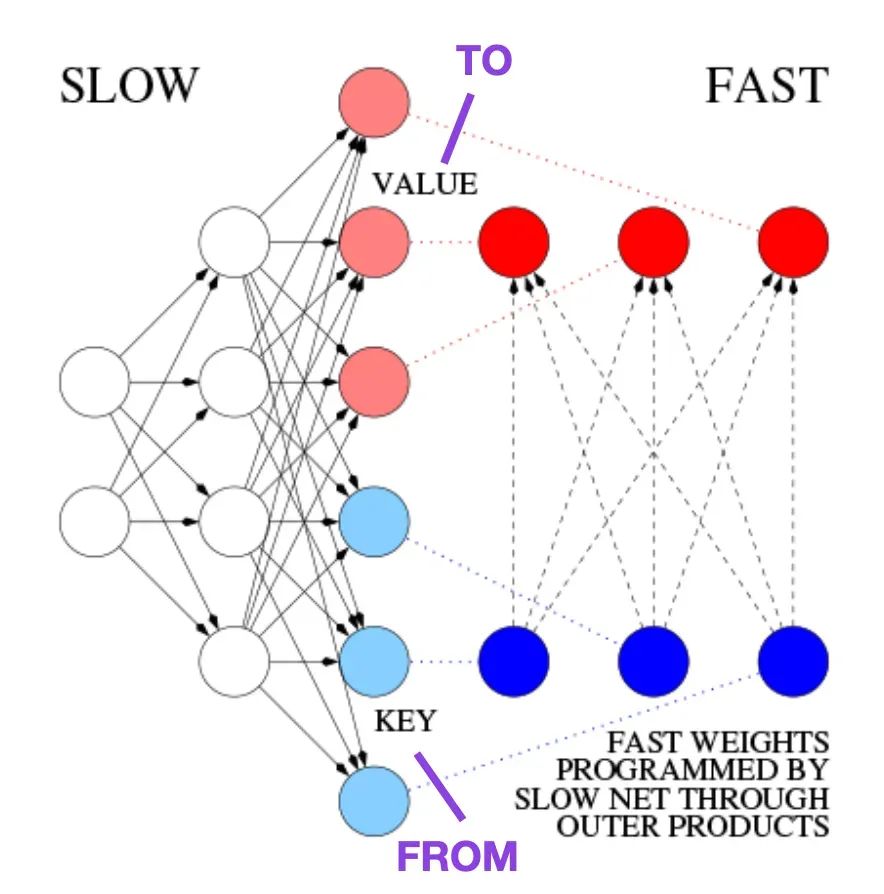
资料来源:基于 https://people.idsia.ch//~juergen/fast-weight- programmer-1991-transformer.html#sec2 的注释图
(5) 通用语言模型微调用于文本分类 (2018),由Howard和Ruder撰写,https://arxiv.org/abs/1801.06146
这还是一篇从历史角度非常有趣的论文。虽然它是在原始的《只需注意力》Transformer发布一年后撰写的,但它并不涉及Transformer,而是关注循环神经网络。然而,它仍然值得注意,因为它有效地提出了预训练语言模型和迁移学习的概念,用于下游任务。
尽管迁移学习已经在计算机视觉领域确立,但在自然语言处理(NLP)领域还不普遍。ULMFit是最早的一些论文之一,展示了预训练语言模型并在特定任务上进行微调,可以在许多NLP任务中获得最先进的结果。
ULMFit建议的语言模型微调三阶段过程如下:
-
• 在大量文本语料库上训练语言模型。
-
• 在任务特定数据上微调这个预训练的语言模型,使其适应文本的特定风格和词汇。
-
• 在任务特定数据上微调分类器,并逐渐解冻层以避免灾难性遗忘。
这种配方——在大型语料库上训练语言模型,然后在下游任务上进行微调——是基于Transformer的模型和基础模型,如BERT、GPT-2/3/4、RoBERTa等的核心方法。
然而,ULMFiT中的逐渐解冻,通常不在使用Transformer架构时常规进行,其中所有层通常同时进行微调。
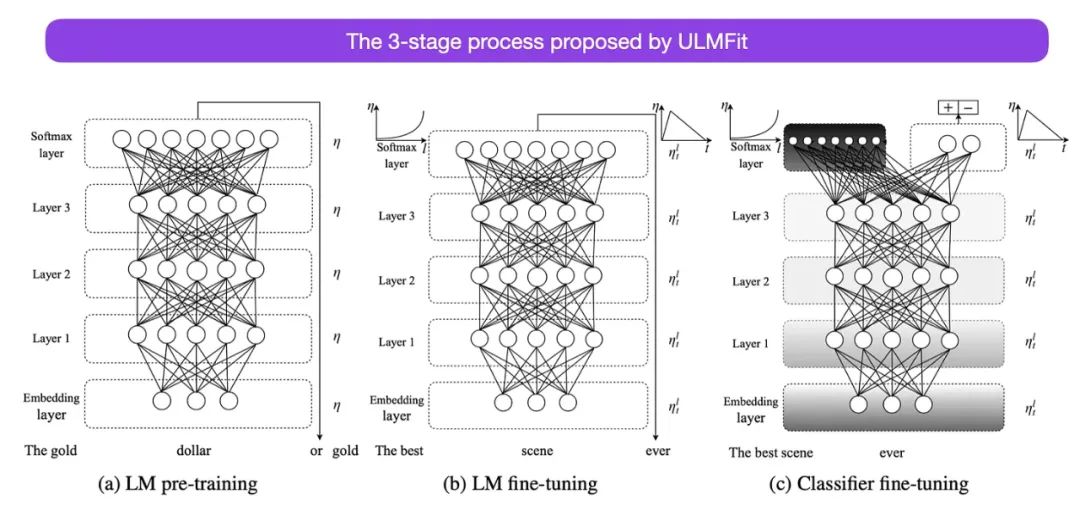
来源:https://arxiv.org/abs/1801.06146
(6) BERT: 双向Transformer的语言理解预训练 (2018),由Devlin, Chang, Lee和Toutanova撰写,https://arxiv.org/abs/1810.04805
在原始Transformer架构之后,大语言模型研究开始向两个方向分化:用于预测建模任务(如文本分类)的编码器风格Transformer和用于生成建模任务(如翻译、摘要和其他形式的文本创作)的解码器风格Transformer。
上述BERT论文介绍了原始的遮蔽语言模型和下一句预测的概念。它仍然是最有影响力的编码器风格架构。如果你对这个研究分支感兴趣,我建议你继续关注RoBERTa,它通过删除下一句预测任务简化了预训练目标。
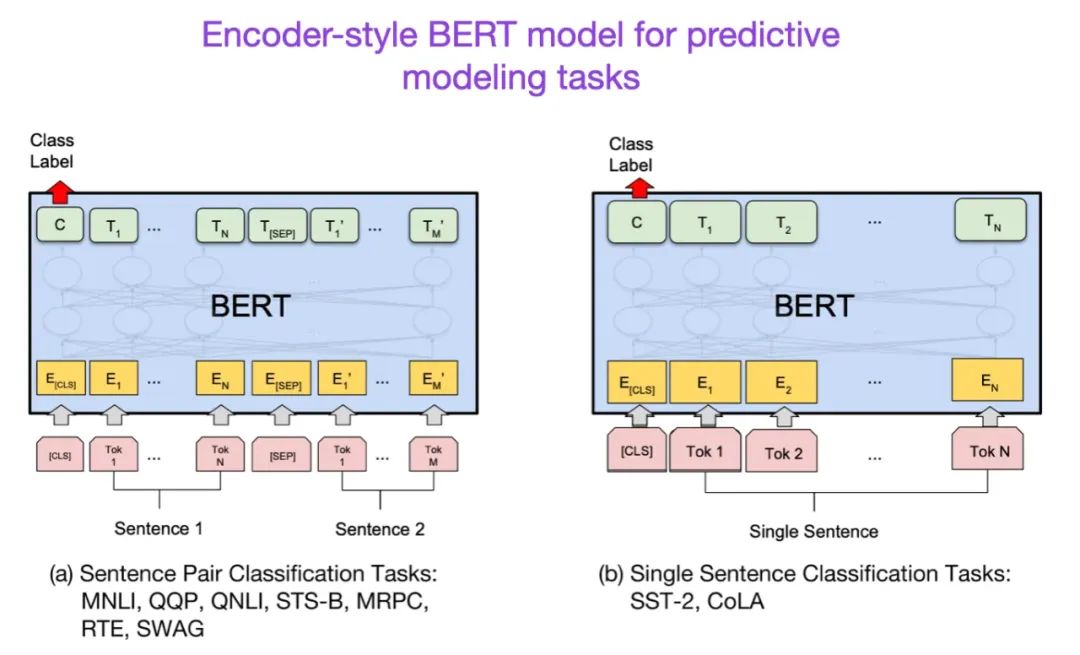
来源:https://arxiv.org/abs/1810.04805
(7) 通过生成预训练提高语言理解 (2018),由Radford和Narasimhan撰写,https://openai.com/research/language- unsupervised.
原始GPT论文介绍了流行的解码器风格架构和通过下一个词预测进行预训练的方法。由于其遮蔽语言模型预训练目标,BERT可以被视为双向Transformer,而GPT是一个单向的、自回归模型。虽然GPT嵌入也可以用于分类,但GPT方法是当今最有影响力的LLM(如chatGPT)的核心。
如果你对这个研究分支感兴趣,我建议你继续关注GPT-2和GPT-3论文。这两篇论文说明了LLM能够进行零样本和少样本学习,并突出了LLM的紧急能力。GPT-3还是目前流行的基线和当前一代LLM(如ChatGPT)训练的基础模型——稍后我们将单独介绍导致ChatGPT的InstructGPT方法。
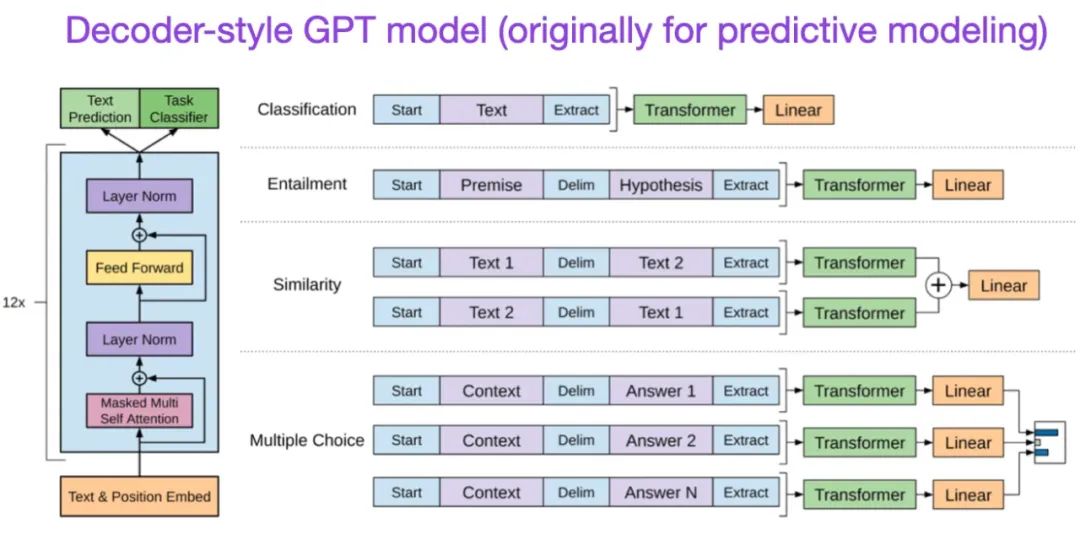
来源:https://www.semanticscholar.org/paper/Improving-Language-Understanding-by- Generative-Radford-Narasimhan/cd18800a0fe0b668a1cc19f2ec95b5003d0a5035
(8) BART: 用于自然语言生成、翻译和理解的去噪序列到序列预训练 (2019),由Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov和Zettlemoyer撰写,https://arxiv.org/abs/1910.13461.
如前所述,BERT类型的编码器风格LLM通常更适用于预测建模任务,而GPT类型的解码器风格LLM更擅长生成文本。为了融合两者的优势,上述BART论文结合了编码器和解码器部分(不像原始的Transformer——本列表的第二篇论文)。
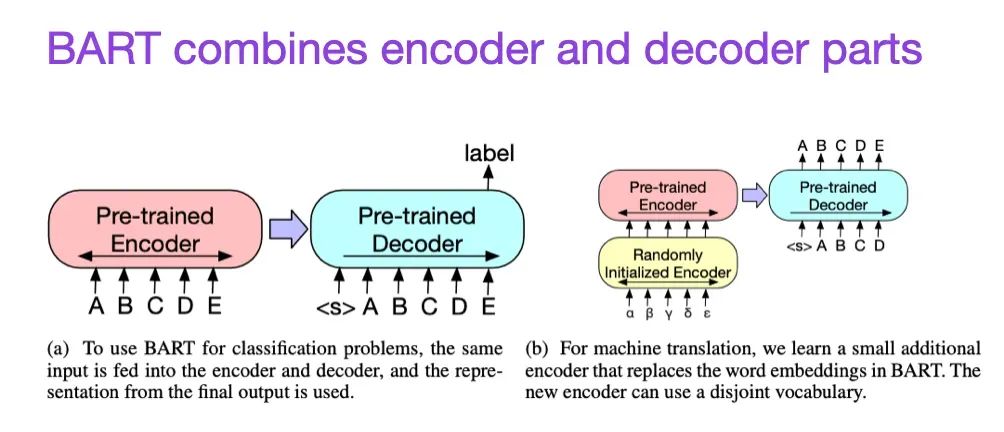
来源:https://arxiv.org/abs/1910.13461
(9) 在实践中利用LLM的力量:关于ChatGPT及其它的调查 (2023),由Yang, Jin, Tang, Han, Feng, Jiang, Yin和Hu撰写,https://arxiv.org/abs/2304.13712
这不是一篇研究论文,但可能是迄今为止最好的总体架构调查,展示了不同架构的演变。然而,除了讨论BERT风格的遮蔽语言模型(编码器)和GPT风格的自回归语言模型(解码器)之外,它还提供了有关预训练和微调数据的有用讨论和指导。
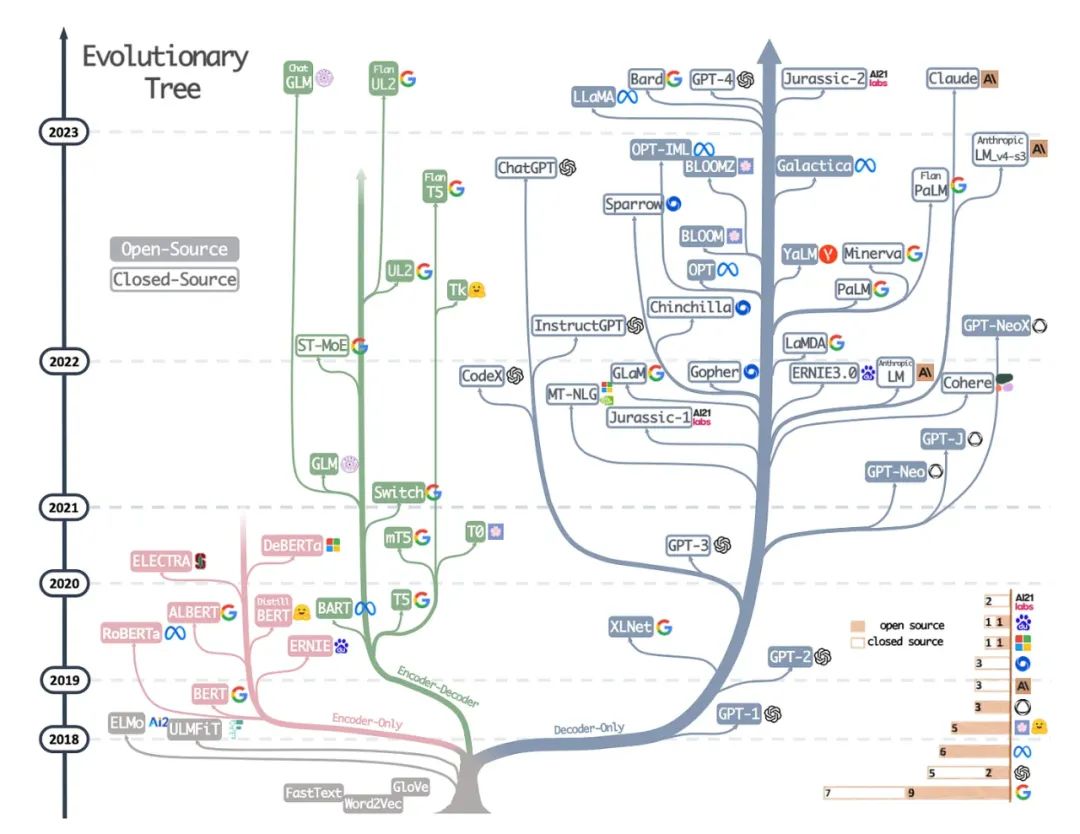
现代LLMs的进化树 via https://arxiv.org/abs/2304.13712.
提高效率的比例定律
如果你想了解更多关于提高Transformer效率的各种技术,请查阅2020年的高效Transformer:一项调查论文(https://arxiv.org/abs/2009.06732),然后是2023年的Transformer高效训练的调查论文(https://arxiv.org/abs/2302.01107)。
此外,下面是我发现特别有趣且值得一读的论文。
(10) FlashAttention: 具有IO感知的快速和内存高效的精确注意力 (2022), 由Dao, Fu, Ermon, Rudra和Ré撰写, https://arxiv.org/abs/2205.14135.
虽然大多数Transformer论文不考虑替换原始的缩放点积机制来实现自注意力,但FlashAttention是我最近经常看到的一种机制。
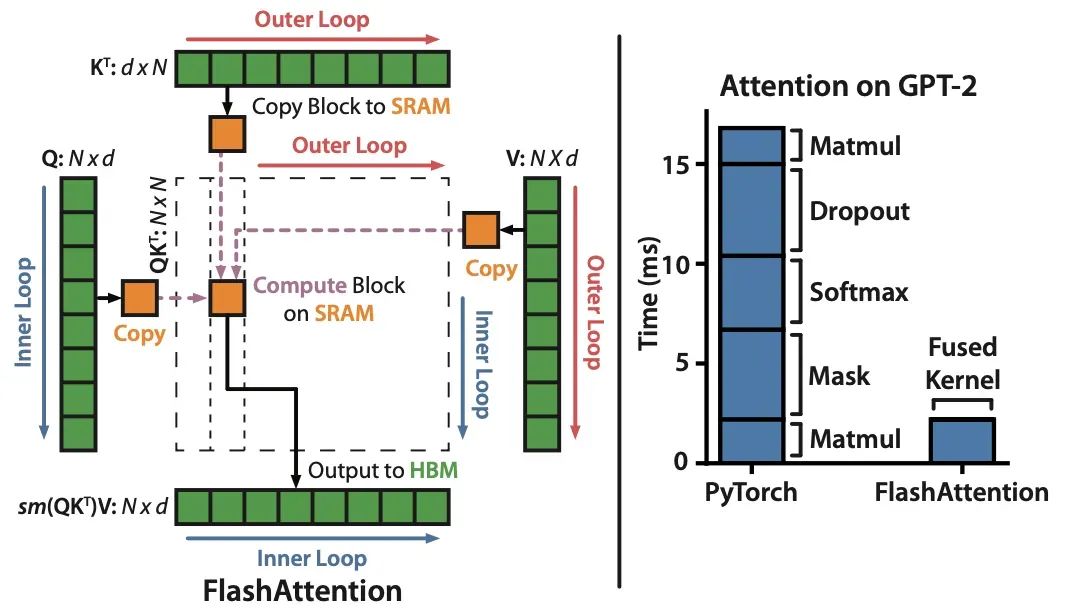
来源:https://arxiv.org/abs/2205.14135
(11) Cramming: 在一天内在单个GPU上训练语言模型 (2022) 由Geiping和Goldstein撰写, https://arxiv.org/abs/2212.14034.
在这篇论文中,研究人员在单个GPU上训练了一个遮蔽语言模型/编码器风格的LLM(这里是BERT)24小时。相比之下,原始的2018年BERT论文在16个TPU上训练了四天。一个有趣的见解是,虽然较小的模型有更高的吞吐量,但较小的模型也学习得不那么高效。因此,较大的模型不需要更多的训练时间就可以达到特定的预测性能阈值。
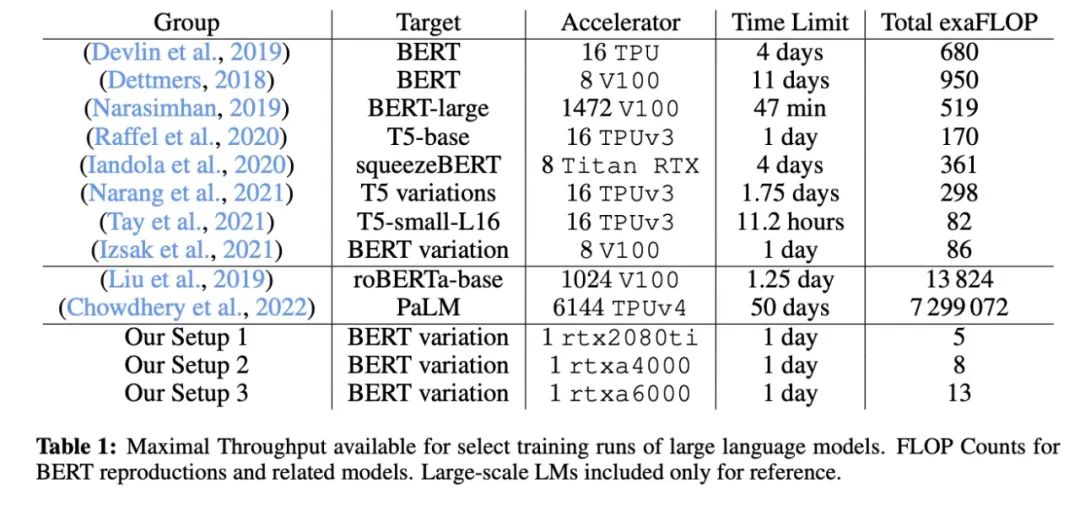
来源:https://arxiv.org/abs/2212.14034
(12) LoRA:大型语言模型的低秩调整 (2021) 由Hu, Shen, Wallis, Allen-Zhu, Li, L Wang, S Wang和Chen撰写, https://arxiv.org/abs/2106.09685.
现代大型语言模型在大型数据集上进行预训练,在各种任务上表现出色,包括语言翻译、摘要、编码和问答。然而,如果我们想提高Transformer在特定领域数据和专业任务上的能力,微调Transformer是值得的。
低秩调整(LoRA)是微调大型语言模型中最有影响力的方法之一。虽然存在其他参数高效的微调方法(见下面的调查),但LoRA特别值得一提,因为它既优雅又通用,可以应用于其他类型的模型。
虽然预训练模型在预训练任务上的权重具有完全秩,但LoRA作者指出,当它们适应新任务时,预训练的大型语言模型具有低“内在维度”。因此,LoRA的主要思想是将权重变化ΔW分解为更参数高效的低秩表示。
LoRA 及其性能的插图 https://arxiv.org/abs/2106.09685.
(13) 通过缩小规模来提升规模:参数高效微调的指南 (2022) 由Lialin, Deshpande和Rumshisky撰写, https://arxiv.org/abs/2303.15647.
现代大型语言模型在大型数据集上进行预训练,在各种任务上表现出色,包括语言翻译、摘要、编码和问答。然而,如果我们想提高Transformer在特定领域数据和专业任务上的能力,微调Transformer是值得的。这项调查回顾了40多篇关于参数高效微调方法的论文(包括流行的技术,如前缀调整、适配器和低秩调整),使微调(非常)计算高效。
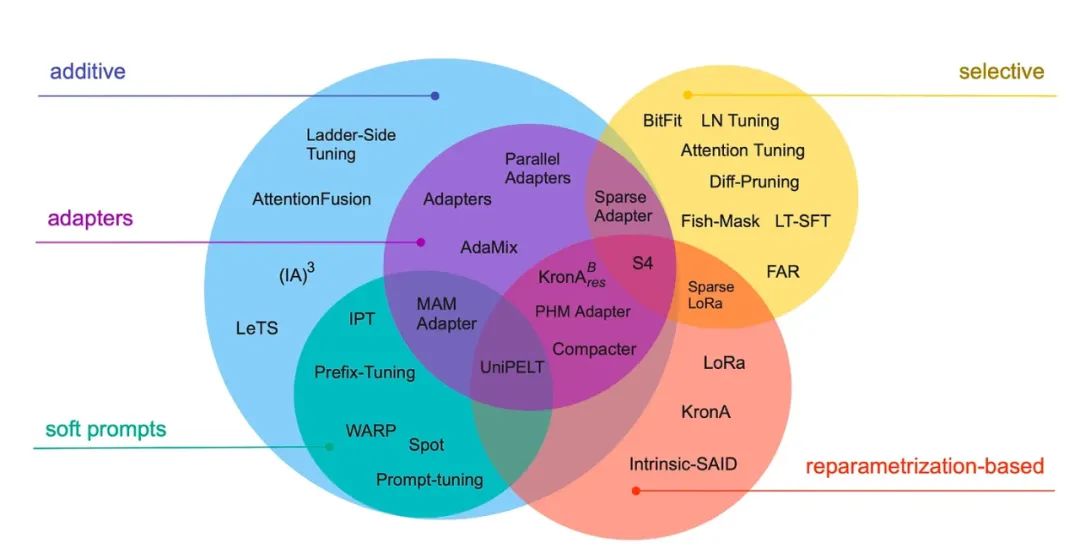
来源:https://arxiv.org/abs/2303.15647
(14) 规模化语言模型:方法、分析及Gopher训练的见解 (2022) 由Rae和同事(78名合著者!)撰写, https://arxiv.org/abs/2112.11446.
Gopher是一篇特别好的论文,包括大量分析,以了解LLM训练。在这里,研究人员训练了一个拥有2800亿参数和80层的模型,在3000亿token上进行训练。这包括一些有趣的架构修改,例如使用RMSNorm(均方根标准化)而不是LayerNorm(层正则化)。由于它们不依赖于批量大小,并且不需要同步,所以LayerNorm和RMSNorm优于BatchNorm,这在分布式设置中使用较小批量时是一个优势。然而,通常认为RMSNorm可以在更深的架构中稳定训练。
除了上述有趣的细节之外,这篇论文的主要焦点是对不同规模的任务性能的分析。在152个不同任务的评估中,增加模型大小最有益于理解、事实核查和识别有害语言的任务。然而,与逻辑和数学推理相关的任务从架构扩展中受益较少。
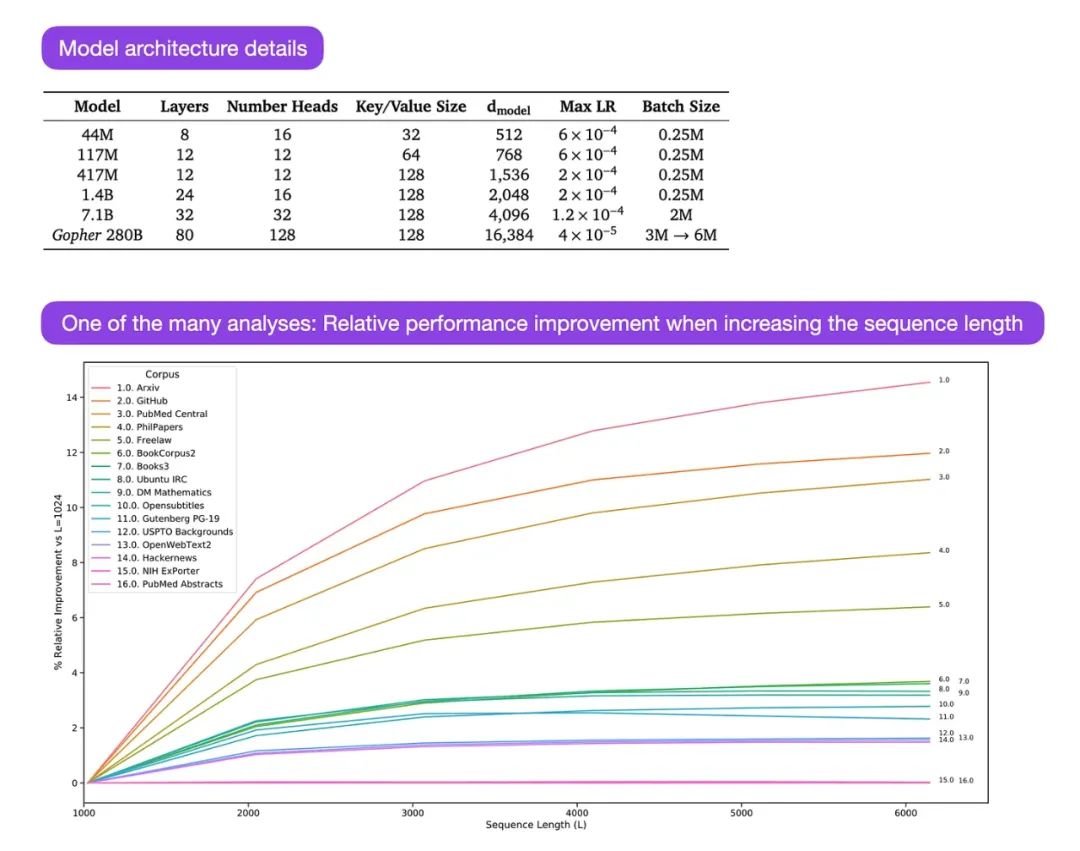
资料来源:图来自 https://arxiv.org/abs/2112.11446
(15) 训练计算最优的大型语言模型 (2022) 由Hoffmann, Borgeaud, Mensch, Buchatskaya, Cai, Rutherford, de Las Casas, Hendricks, Welbl, Clark, Hennigan, Noland, Millican, van den Driessche, Damoc, Guy, Osindero, Simonyan, Elsen, Rae, Vinyals和Sifre撰写, https://arxiv.org/abs/2203.15556.
这篇论文介绍了70亿参数的Chinchilla模型,它在生成建模任务上超越了流行的1750亿参数的GPT-3模型。然而,它的主要亮点是,当代大型语言模型“显著低训练”。
这篇论文定义了大型语言模型训练的线性比例定律。例如,虽然Chinchilla只有GPT-3的一半大小,但它超越了GPT-3,因为它在1.4万亿(而不是仅3000亿)token上进行了训练。换句话说,训练token的数量与模型大小一样重要。
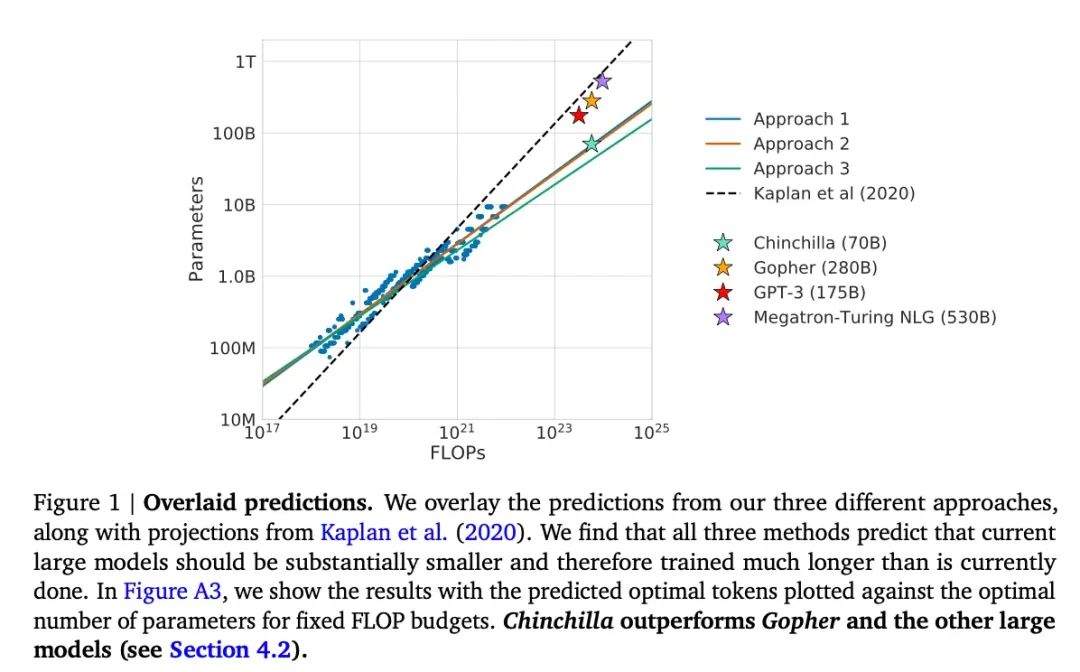
来源:https://arxiv.org/abs/2203.15556
(16) Pythia: 分析大型语言模型在训练和规模化过程中的套件 (2023) 由Biderman, Schoelkopf, Anthony, Bradley, O’Brien, Hallahan, Khan, Purohit, Prashanth, Raff, Skowron, Sutawika和van der Wal撰写, https://arxiv.org/abs/2304.01373.
Pythia是一套开放源码的LLM(从7000万到120亿参数),用于研究LLM在训练过程中的演变。
该架构类似于GPT-3,但包括一些改进,例如Flash Attention(如LLaMA)和旋转位置嵌入(如PaLM)。Pythia在The Pile数据集(825 Gb)上训练了3000亿token(1个epoch在常规PILE上,1.5个epoch在去重的PILE上)。
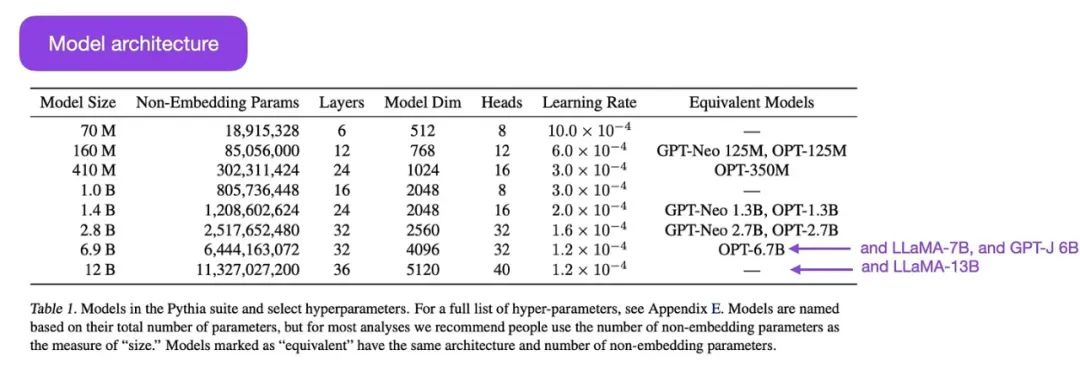
通过 https://arxiv.org/abs/2304.01373 的Pythia模型套件.
Pythia研究的主要见解如下:
-
1. 在重复数据上训练(由于LLM的训练方式,这意味着训练超过一个epoch)既不利于也不损害性能。
-
2. 训练顺序不影响记忆。这很不幸,因为如果情况相反,我们可以通过重新排序训练数据来减轻不希望的逐字记忆问题。
-
3. 预训练术语频率影响任务性能。例如,对于更常见的术语,少样本准确性往往更高。
-
4. 加倍批量大小可以将训练时间减半,但不会影响收敛。
对齐——引导大型语言模型实现预期目标和兴趣
近年来,我们看到了许多相对有能力的大型语言模型,它们可以生成现实的文本(例如,GPT-3和Chinchilla等)。看来我们已经达到了常用预训练范式所能达到的上限。
为了使语言模型更有帮助并减少错误信息和有害语言,研究人员设计了额外的训练范式来微调预训练的基础模型。
(17) 训练语言模型遵循人类反馈的指令 (2022) 由Ouyang, Wu, Jiang, Almeida, Wainwright, Mishkin, Zhang, Agarwal, Slama, Ray, Schulman, Hilton, Kelton, Miller, Simens, Askell, Welinder, Christiano, Leike和Lowe撰写, https://arxiv.org/abs/2203.02155.
在所谓的InstructGPT论文中,研究人员使用了一种带有人类回路的强化学习机制(RLHF)。他们从预训练的GPT-3基础模型开始,然后使用人类生成的提示- 响应对进行监督学习(第一步)。接下来,他们要求人类对模型输出进行排序,以训练奖励模型(第二步)。最后,他们使用奖励模型通过近端策略优化(proximal policy optimization)更新预训练和微调过的GPT-3模型(第三步)。
顺便说一句,这篇论文也被称为描述ChatGPT背后思想的论文——根据最近的传言,ChatGPT是InstructGPT的放大版本,已在更大的数据集上进行了微调。
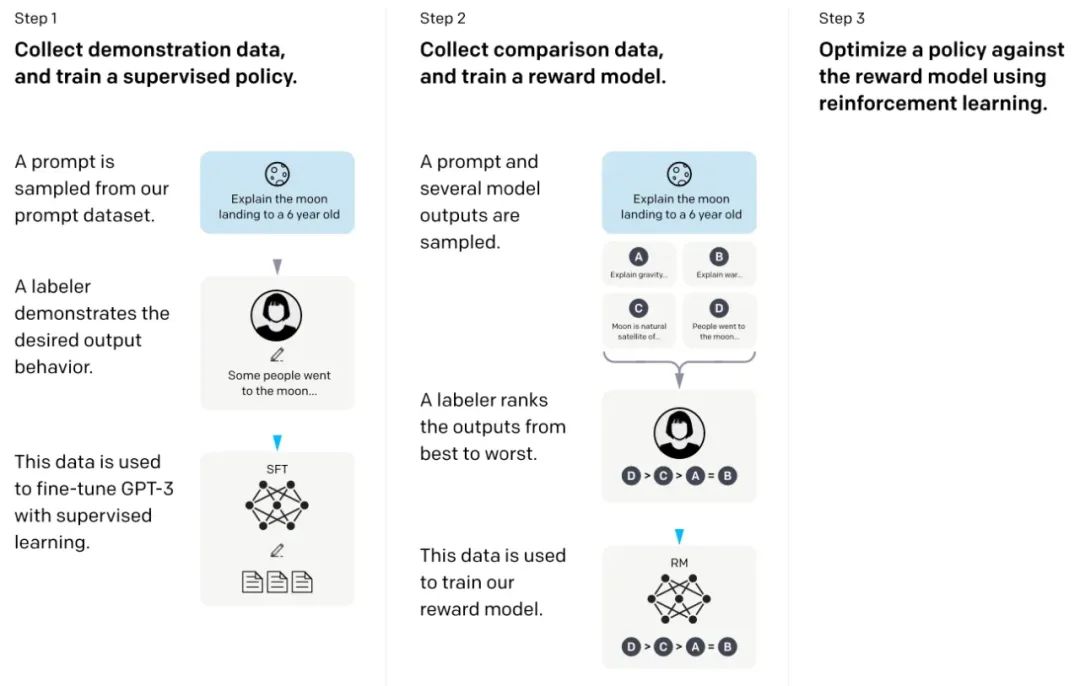
来源:https://arxiv.org/abs/2203.02155
(18) 宪法AI:来自AI反馈的无害性 (2022) 由Yuntao, Saurav, Sandipan, Amanda, Jackson, Jones, Chen, Anna, Mirhoseini, McKinnon, Chen, Olsson, Olah, Hernandez, Drain, Ganguli, Li, Tran-Johnson, Perez, Kerr, Mueller, Ladish, Landau, Ndousse, Lukosuite, Lovitt, Sellitto, Elhage, Schiefer, Mercado, DasSarma, Lasenby, Larson, Ringer, Johnston, Kravec, El Showk, Fort, Lanham, Telleen-Lawton, Conerly, Henighan, Hume, Bowman, Hatfield-Dodds, Mann, Amodei, Joseph, McCandlish, Brown, Kaplan, https://arxiv.org/abs/2212.08073.
在这篇论文中,研究人员将对齐理念推向更远,提出了一种创建“无害”AI系统的训练机制。与上述InstructGPT论文不同,研究人员提出了一种基于规则列表(由人类提供)的自我训练机制。与上述InstructGPT论文类似,所提出的方法使用了一种强化学习方法。
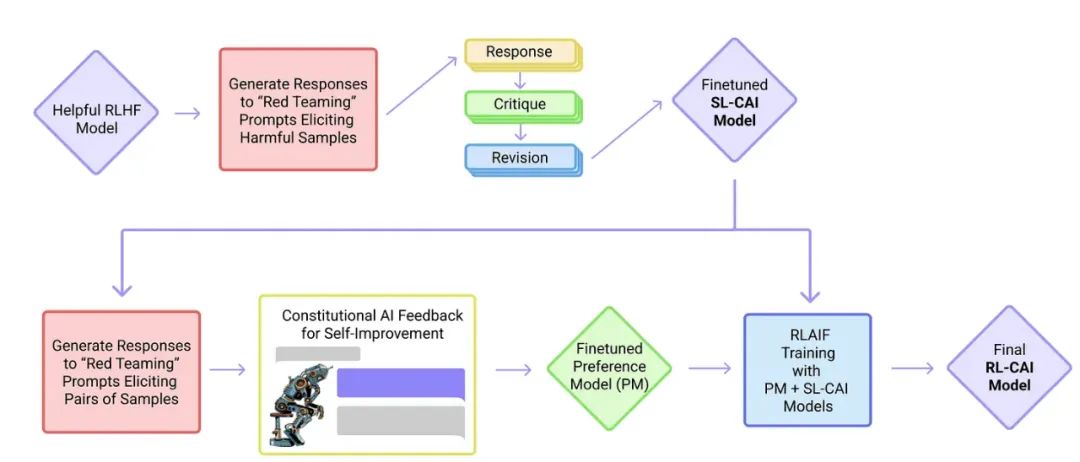
来源:https://arxiv.org/abs/2212.08073
(19) 自我指令:通过自我生成的指令与语言模型对齐 (2022) 由Wang, Kordi, Mishra, Liu, Smith, Khashabi和Hajishirzi撰写, https://arxiv.org/abs/2212.10560.
指令微调是我们如何从类似GPT-3的预训练基础模型转变为更有能力的LLM,如ChatGPT。而开源的人类生成的指令数据集,如databricks- dolly-15k,可以帮助实现这一目标。但我们如何扩大规模呢?一种方法是利用LLM自身的生成进行引导。
Self-Instruct是一种(几乎无需注释的)方式,可以将预训练的LLM与指令对齐。
这是如何工作的?简而言之,这是一个四步过程:
-
1. 使用一组人类编写的指令(本例中为175条)和样本指令填充任务池。
-
2. 使用预训练的LLM(如GPT-3)确定任务类别。
-
3. 根据新的指令,让预训练的LLM生成响应。
-
4. 收集、修剪和过滤响应,然后将它们添加到任务池中。
-
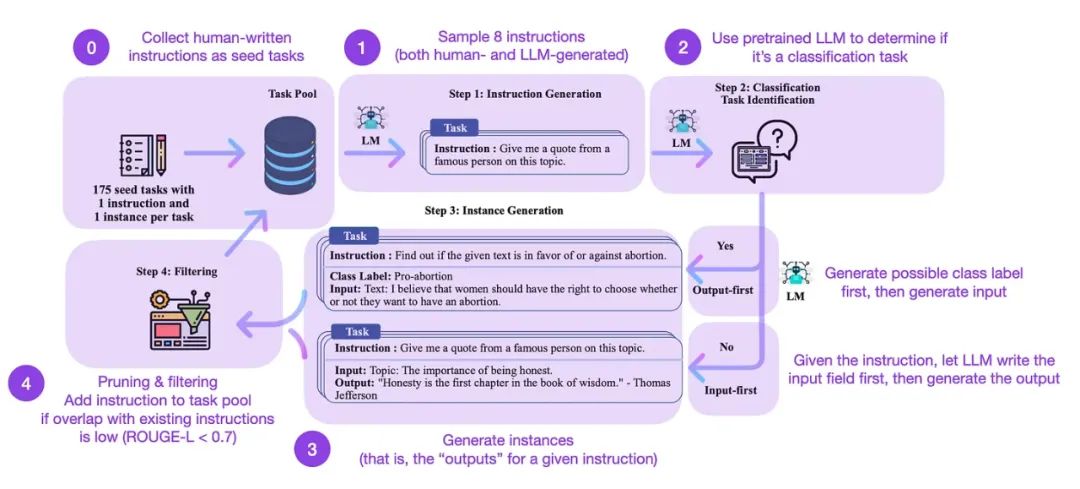
来自 https://arxiv.org/abs/2212.10560 的 self-instruct 方法的注释版本.
实际上,这种方法基于ROUGE分数表现相对良好。
例如,经过Self-Instruct微调的LLM优于基础LLM(1),并且可以与在大型人类编写的指令集上预训练的LLM竞争(2)。Self- Instruct还可以使已经在人类指令上进行过微调的LLM受益(3)。
但当然,评估LLM的黄金标准是询问人类评估者。根据人类评估,Self-Instruct优于基础LLM和在监督方式下训练的LLM(SuperNI, T0 Trainer)。但有趣的是,Self-Instruct在性能上不及通过人类反馈的强化学习(RLHF)训练的方法。
人类生成的指令数据集和自我指令数据集哪个更有前景?我选择两者。为什么不从databricks- dolly-15k这样的人类生成的指令数据集开始,然后用self-instruct来扩展呢?
结论和进一步阅读
我试图保持上述列表简洁明了,重点介绍前10篇论文(加上3篇有关RLHF的额外论文),以理解当代大语言模型的设计、限制和演变。
如需进一步阅读,我建议您参考上述论文中的参考文献。或者,为了给您一些额外的指南,这里是一些额外的资源(这些列表不是全面的):
GPT的开源替代品
• BLOOM:一个1760亿参数的开放获取多语言语言模型 (2022), https://arxiv.org/abs/2211.05100
• OPT:开放预训练的Transformer语言模型 (2022), https://arxiv.org/abs/2205.01068
• UL2:统一语言学习范式 (2022), https://arxiv.org/abs/2205.05131
ChatGPT的替代品
• LaMDA:对话应用的语言模型 (2022), https://arxiv.org/abs/2201.08239
• (Bloomz) 通过多任务微调实现跨语言泛化 (2022), https://arxiv.org/abs/2211.01786
• (Sparrow) 通过有针对性的人类判断改进对话代理的对齐 (2022), https://arxiv.org/abs/2209.14375
• BlenderBot 3: 部署的对话代理,不断学习负责任地参与 https://arxiv.org/abs/2208.03188
计算生物学中的大语言模型
• ProtTrans:通过自我监督的深度学习和高性能计算破解生命代码的语言 (2021), https://arxiv.org/abs/2007.06225
• AlphaFold:高精度的蛋白质结构预测 (2021), https://www.nature.com/articles/s41586-021-03819-2
• 大型语言模型在多样化的蛋白质家族中生成功能性蛋白质序列 (2023), https://www.nature.com/articles/s41587-022-01618-2
推荐阅读
• AI是开源大模型太多怎么选?一文读懂,5个最好的开源大模型!