来源:Everypixel Journal
编译:Gavin
原文:https://journal.everypixel.com/basics-of-image-recognition
在人工智能领域,图像识别就像是机器看世界、理解视觉数据的一扇大门,就像人类那样。
本文将探讨图像识别的工作原理,简要回顾其发展历史,并介绍一些应用案例。
关键术语
图像识别领域有许多术语经常被混淆和互换使用。为了让话题更清晰,我们来快速解释一下这些关键术语,并突出它们之间的区别:
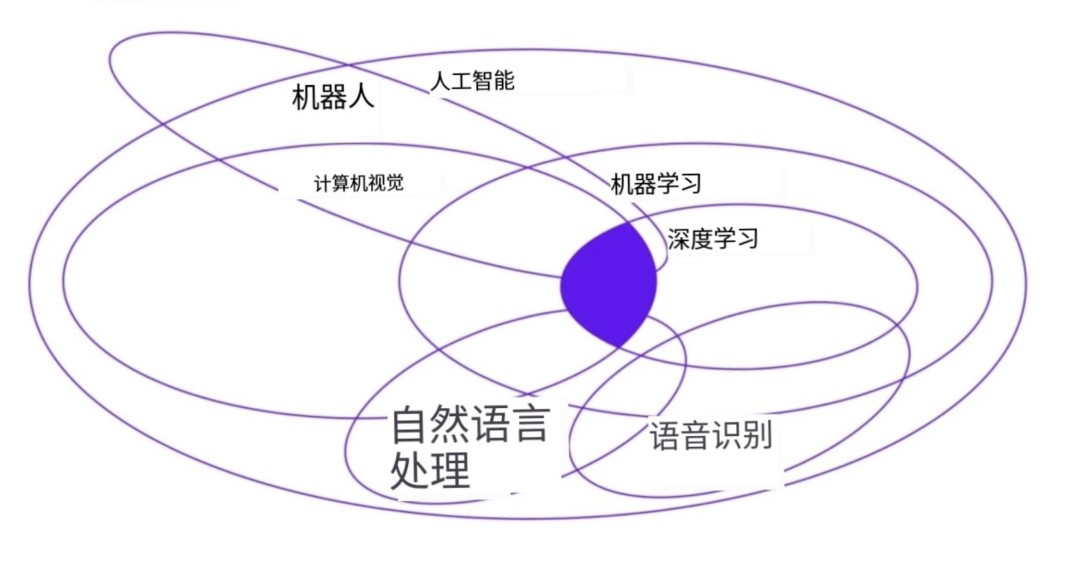
来源:EECS 498-007 / 98-005
计算机视觉 vs. 图像识别 vs. 视觉识别
关于计算机视觉、图像识别、视觉识别这些术语,存在许多不同的理解方式,因此最容易引起混淆。
我们坚持认为,计算机视觉(CV) 是人工智能的一个分支,致力于让计算机能够识别、理解视觉输入的信息,并根据这些信息采取行动。
计算机视觉有许多任务,规定了计算机视觉程序如何处理图像并返回信息。其中一些任务包括:
-
• 图像分类 :将图像分配到预定义的类别之一。
-
• 图像关键词提取(或图像标签) :为图像分配关键词或标签。
-
• 目标检测 :识别照片、视频或图像中的特定目标,并用边界框(精确勾勒目标的矩形)框住它。
-
• 光学字符识别(OCR) :识别图像中的字母和数字,并将其转换为机器编码的文本。
-
• 图像分割 :将图像分割成更小的部分(分割),以更详细地理解图像。该任务的结果是一个图像掩码,表示每个识别类的具体边界和形状。
-
• 目标跟踪 :随时间处理视频中移动目标的位置。

因此,图像识别(IR) 是计算机视觉的一个应用,可以针对不同目的使用不同的任务。视觉识别 则是图像识别的一个更广泛的术语,涵盖了更广泛的视觉数据类型,扩展到视频和实时流。
在科技类文章中,你更有可能看到计算机视觉这个术语,开发人员也更青睐这个术语。而图像识别则倾向于在商业和实际应用中找到自己的位置。
下图比较了计算机视觉和图像识别的搜索结果量,可以更清楚看到这一趋势。但总的来说,这些术语有时会互换使用。
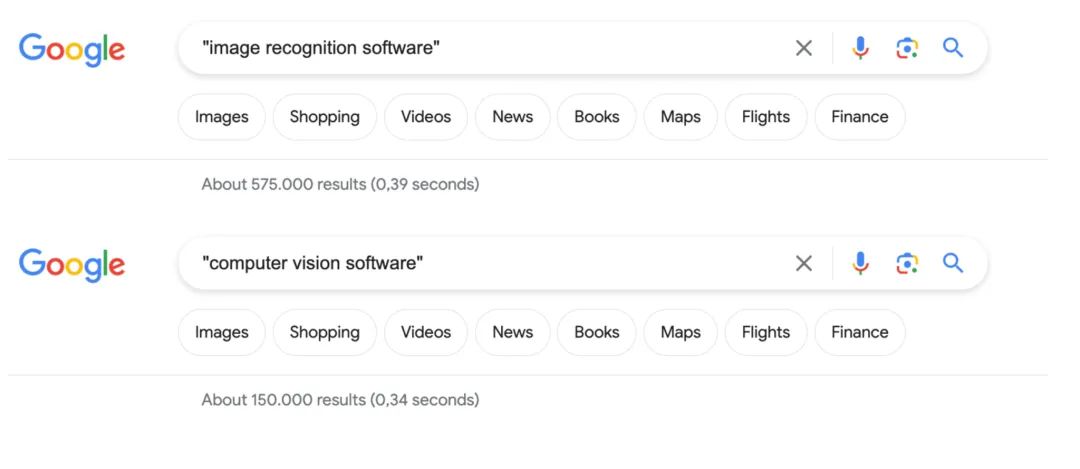
图:CV 和 IR 搜索结果比较
图像识别简史
20世纪50年代末,神经生理学家Hubel和Wiesel的猫实验为理解视觉处理和图像识别奠定了基础。
这个对猫进行的实验意外发现了”简单细胞”——对不同方向的边缘有反应的神经元。
后来在定向柱中发现的这些简单细胞,对计算机视觉算法产生了深远影响,强调图像识别始于处理直边等简单形状。
大约在同一时期,第一台计算机图像扫描技术出现,允许计算机数字化和捕获图像。
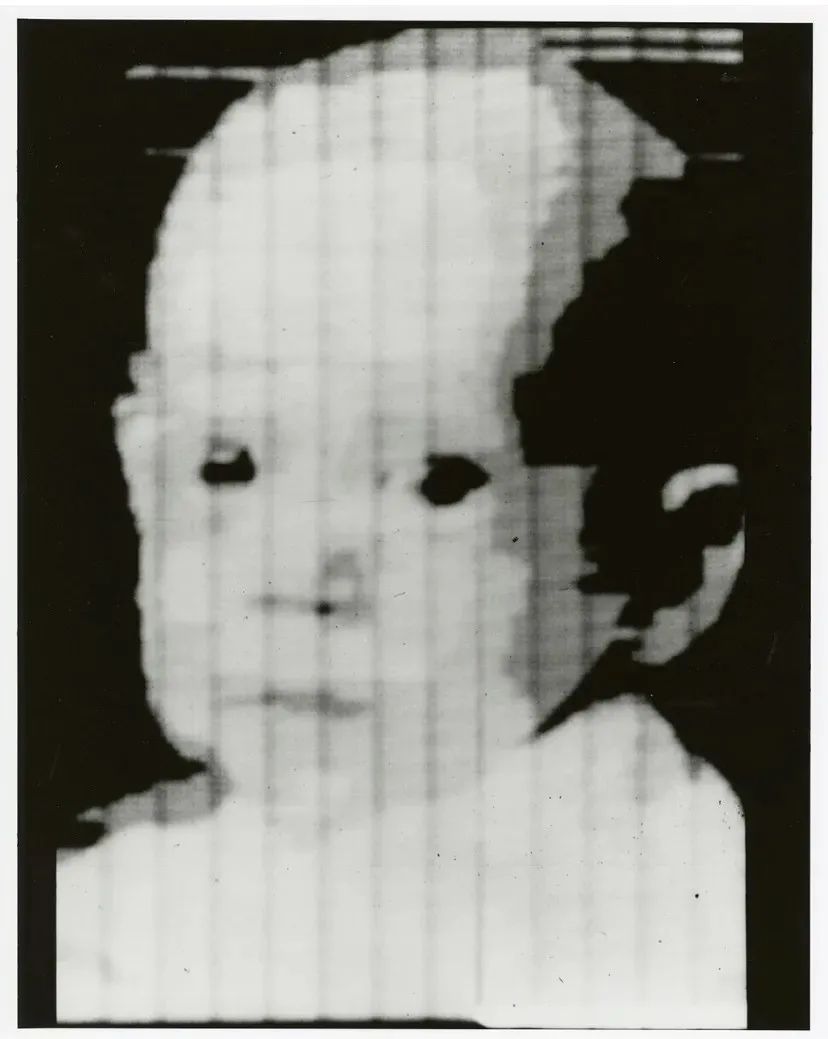
图:第一张数码照片
20世纪60年代,人工智能作为一个学术领域出现,开始了解决人类视觉问题的探索。
1974年,光学字符识别(OCR)和更先进的智能字符识别(ICR)出现,后来催生了ABBYY开发的OCR应用程序FineReader。
20世纪80年代,科学家引入了机器检测边缘、角点、曲线和类似基本形状的算法。
21世纪初,研究重点转向目标识别,到2001年出现了第一个实时人脸识别应用。21世纪初还见证了视觉数据集如何标记和注释的标准化建立。

图:机器学习在视觉领域的第一次成功应用
2010年,ImageNet数据集变得可被获得。由Olga Russakovsky和Jia Deng等研究人员领导的ImageNet项目,包含了数百万张跨越一千个目标类别的手工标记图像。
作为模型的基础,ImageNet不仅可以比较检测进展,还有助于衡量计算机视觉领域大规模图像检索和注释的进展。
2012年,多伦多大学的一个团队开发了AlexNet模型,大大降低了图像识别的错误率。

图:ImageNet的2010年测试图像和模型认为最可能的标签
随着该领域的发展,谷歌做了一个最有趣的项目。通过收购reCAPTCHA(一种区分人类和自动访问网站的技术),谷歌显著增强了其OCR算法和AI训练方法。
利用基于图像和文本的验证码(完全自动化的公开图灵测试,用于区分计算机和人类),谷歌开始积累大量带标签的样本数据集。
每当用户解决验证码以访问网站时,他们实质上是在为谷歌的数据集标记图像或文本。这个数据集允许谷歌使用监督式机器学习(一种AI从大量分类样本中学习的方法)来训练其AI。
本质上,现在每个谷歌用户都在为开发更智能、更强大的AI做出贡献,特别是在计算机视觉领域。
图像识别的工作原理
值得澄清的是,图像识别技术有不同的方法,其中最常见的是卷积神经网络(CNN)——一种使用卷积的神经网络架构变体。例如,在前面提到的AlexNet以及我们的项目中,都采用了CNN作为图像识别算法。
首先,图像由”像素”组成,每个像素由一个数字或一组数字表示,其中包括一组表示其颜色的值。
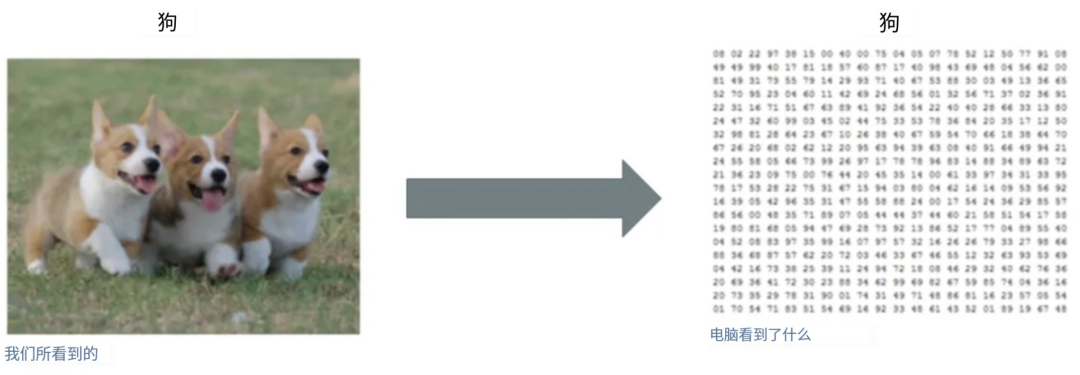
图:二值图像可视化
简而言之,在CNN能够识别物体及其关系、模式和整体图像结构之前,它们需要经过训练过程。
在训练期间,CNN会接触到大量带标签的图像数据集,学习将特定模式和特征与相应的物体标签(如”狗”或”鼠标”)关联起来。
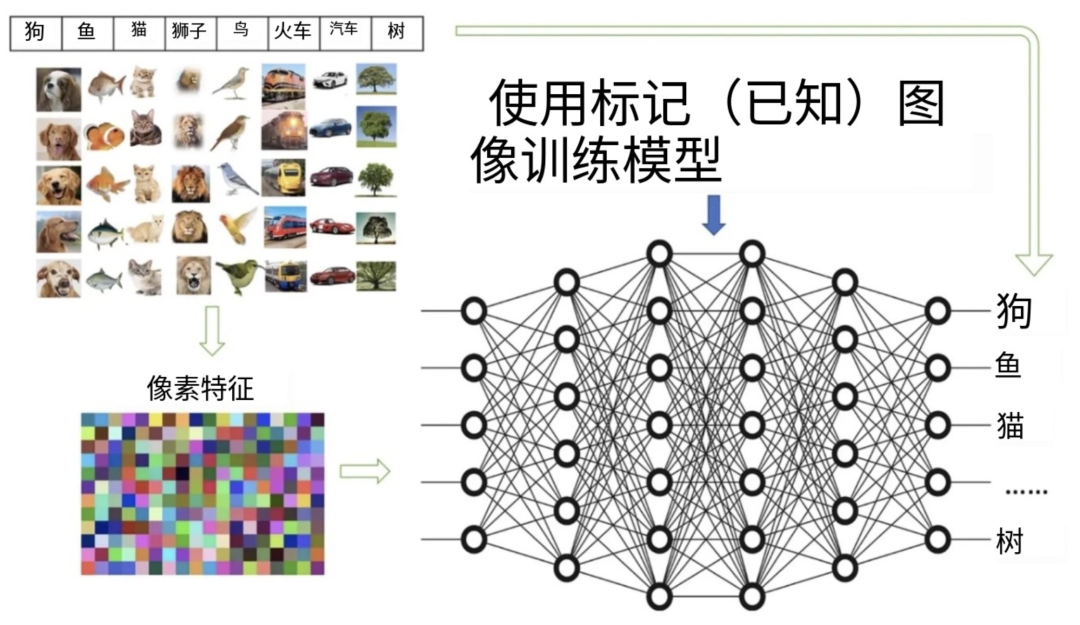
图:模型如何使用预先标记的图像进行训练
经过训练后,CNN会在内部将输入图像压缩成隐藏表示,丢弃无关紧要的信息。这些隐藏表示包含了模式、物体之间的关系、重要像素等。
原始图像经过转换,从图片演变成一张独特特征的地图——一组数值。利用从训练过程中获得的知识,CNN利用这些表示对新图像的内容进行预测。
为了更好地理解CNN的运作,这里我们对CNN中的每个阶段进行简单易懂的解释。CNN网络层通常分为四种不同类型:
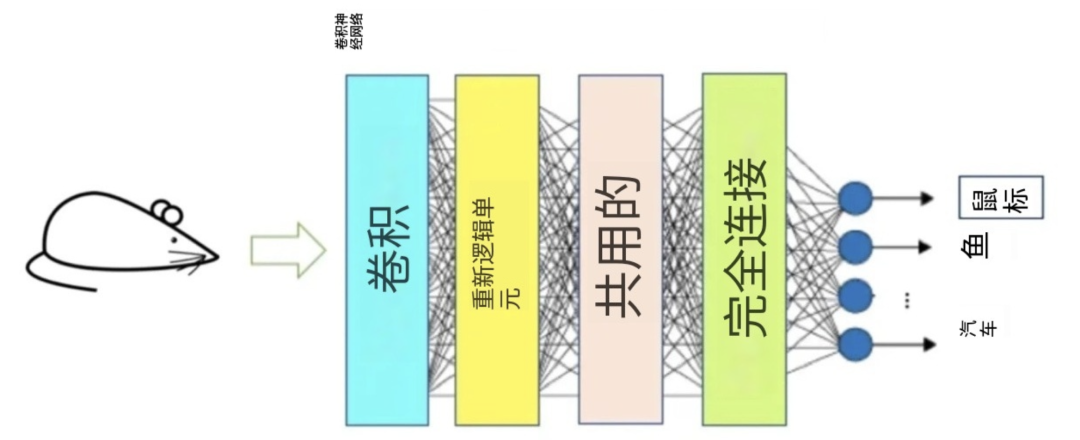
图:CNN的网络层
卷积层
在卷积层中,CNN将图像转换为称为特征的小块。这些特征捕获有关特定形状、边缘、纹理、颜色信息或其他对进一步扫描至关重要的视觉模式的信息。
目标是识别这些特征与训练中已学习的模式之间的匹配。这个过程称为过滤,为完全匹配的特征分配高分,为不太准确的特征分配低分或零分。
它涉及通过扫描尝试每一个可能的匹配——这种操作称为卷积。这个卷积层的输出结果是一张特征图。
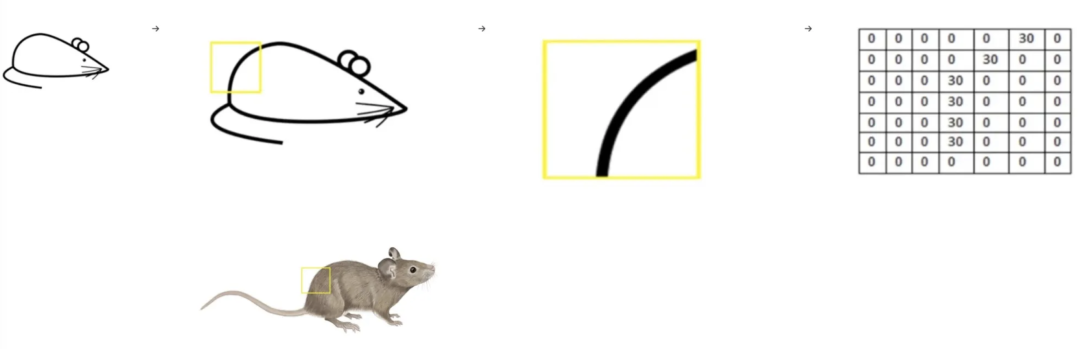
图:图像上滤波器的可视化及其像素表示
激活函数层
在卷积层将图像转换为特征并对其进行过滤以识别模式之后,生成的信息会移动到激活函数层。它评估是否存在特定模式。这一层对于引入非线性至关重要,使网络能够捕获数据中更复杂的依赖关系和模式。
这个激活步骤有助于网络专注于重要的视觉元素,同时过滤掉不太相关的信息。CNN中最常用的激活函数是整流线性单元(ReLU)。
池化层
池化有多种类型,包括MaxPool、AvgPool和MinPool,其中MaxPool是最常用的。池化层获取到目前为止识别出的特征,并减小特征图的尺寸。
池化(尤其是最大池化)背后的目的在于丢弃一些信息,以便神经网络更有效地搜索模式。
最大池化的主要功能是减小特征图的维度。例如,一个2×2的窗口(或3×3,或其他维度)扫描每个过滤后的特征,选取它遇到的最大值,并将其放置在一个新的、更小的1×1框中。
选择最大值很重要,因为它通常包含关键细节,如独特的颜色或物体边界,这对有效的模式识别至关重要。因此,使用2×2窗口的最大池化将特征图的维度减小2倍。
简单来说,池化层有助于保留关键信息,同时使数据更易于管理。
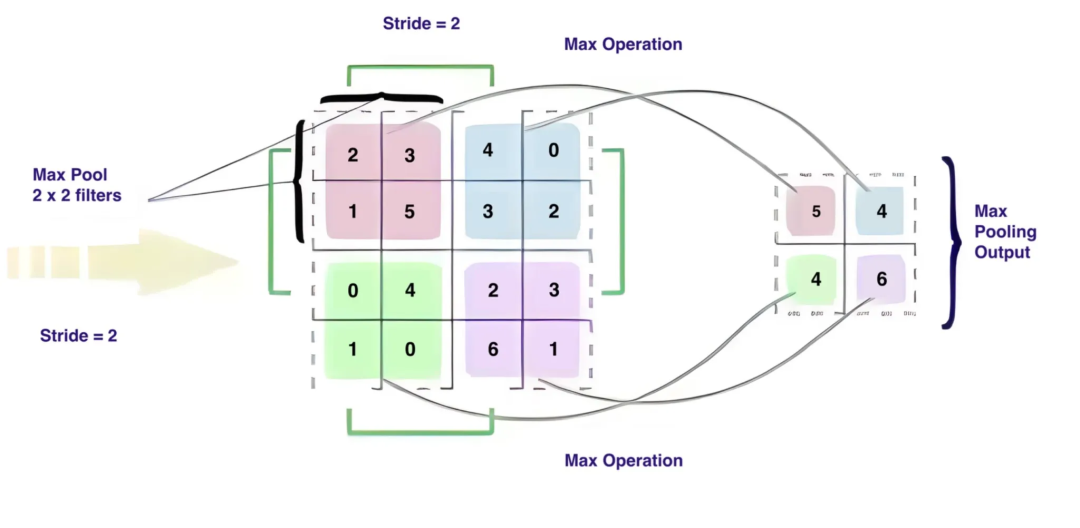
图:池化操作
全连接层
在全连接层中,较小的过滤后的图像经过一个拆分和堆叠成单个列表的过程。这个列表中的每个值在预测不同结果的概率方面都发挥作用。
简单来说,想象一下将池化层突出显示的关键特征以一种有助于网络做出最终决策的方式组织起来。
例如,如果网络正在决定一张图像是否有老鼠,全连接层将查看诸如尾巴、胡须或圆形身体等特征。它为这些特征分配特定的权重,有点像在说:”尾巴在确定它是否是老鼠方面有多重要?”
通过计算这些权重与前一层信息的乘积,全连接层帮助模型生成准确的概率。最后,这就像网络在说:”根据这些特征,我非常确信这是或不是一只老鼠。”这一步确保网络对图像中的内容做出精确的预测。
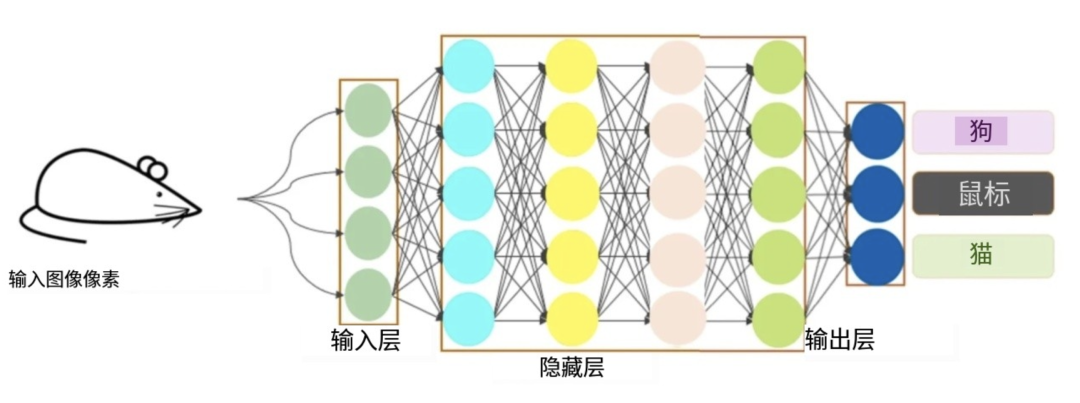
图:图像识别如何工作的
虽然CNN被广泛采用,但也有视觉变换器(ViT),它们更新颖,在某些情况下更有效。
ViT不是直接处理整个图像(如CNN所做的),而是将其分解成更小的”图像块”,并将它们视为结构化序列。
直接应用于图像块序列的纯变换器可以表现得非常好,特别是在图像分类任务中。
当在大型数据集上进行预训练并迁移到各种图像识别基准(如ImageNet)时,与最先进的卷积网络相比,ViT在需要显著更少的计算资源进行训练的同时取得了出色的结果。然而,更深入地探讨这些细微差别和细节可能需要更广泛的讨论。

图:视觉变换器演示
图像识别运用广泛,如识别图像中的对象、人物、地点和动作并将其转换为关键词,便于图像审核;对人脸图片分析一个人的年龄,用于定制广告,提供个性化内容增强用户体验。
在这里,我们只展示了该技术巨大潜力的冰山一角。
虽然围绕图像生成有非常多的炒作,但重要的是要认识到技术的深远重要性,特别是在医学和无障碍等领域,如残障人士。
这些应用不仅展示了图像识别的多功能性,而且强调了它在显著影响和改善我们生活各个方面方面的潜力。