作者:Myscale原文:https://myscale.com/blog/prompt-engineering-vs-finetuning-vs-rag/
本文将探讨提示工程(Prompt Engineering) 、微调(Fine- tuning)和检索增强生成(RAG)的优缺点,旨在帮助你理解何时以及如何有效地运用这些技术。
自大型语言模型(LLMs)和先进聊天模型问世以来,人们采用多种技术从这些AI系统中获得所期望的输出结果。一些方法通过改变模型的行为使其更好地符合我们的预期,而另一些方法则专注于优化我们对LLMs的查询方式,以获取更精确和相关的信息。检索增强生成(Retrieval- Augmented Generation,RAG)、提示工程(Prompting) 和微调(Fine- tuning)是目前最常用的技术。下面我们将比较每种技术的优缺点。这非常重要,因为它将帮助你理解何时以及如何有效地使用这些技术。让我们开始比较,探索每种方法的独特之处。
提示工程
提示词是与大模型交互的最基本方式。它就像给出指令一样。当你使用一个提示词时,你实际上是在告诉模型,你希望它提供哪类信息。这也被称作提示工程(prompt
engineering)。它有点像学会提出正确的问题,以获得最佳答案。但是你从中获取到的信息是有限的,因为模型只能回馈它在训练过程中已经学到的知识。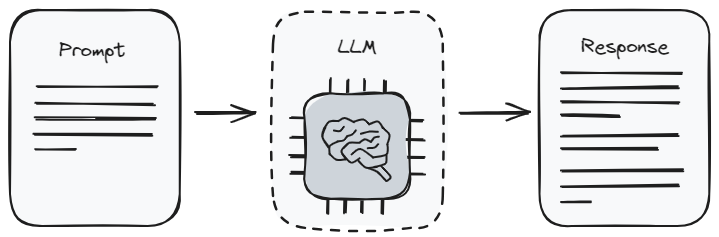 提示工程的使用流程相当直接。你无需成为技术专家即可以开始使用,这对大多数人来说是个好消息。但由于它很大程度上依赖于训练好的模型,它可能无法总是提供你所需的最新或最具体的信息。提示工程最适合处理一般性话题,或者在你需要快速获得答案而不需要深入了解细节时使用。优点:
提示工程的使用流程相当直接。你无需成为技术专家即可以开始使用,这对大多数人来说是个好消息。但由于它很大程度上依赖于训练好的模型,它可能无法总是提供你所需的最新或最具体的信息。提示工程最适合处理一般性话题,或者在你需要快速获得答案而不需要深入了解细节时使用。优点:
-
易用性:容易上手,不需要高级技术技能,因此被广泛接受。
-
成本效益:由于利用了预训练模型,与微调相比,其计算成本非常低。
-
灵活性:可以快速调整,以探索不同的输出,而无需重新训练模型。
缺点:
-
不一致性:输出的质量可能会因提示词而产生明显差异。
-
定制限制:调整模型响应的能力受限于写提示词的创造力和技能。
-
依赖模型知识:输出仅限于模型在初始训练期间学到的内容,高度专业化或最新信息输出效果不佳。
微调
微调是指你让语言模型学习一些新的或特殊的东西。可以将其想象为,更新手机上的应用程序以获得更好的功能。但在这种情况下,应用程序(模型)需要大量的新信息和时间来正确学习一切。这有点像是让模型回到学校学习。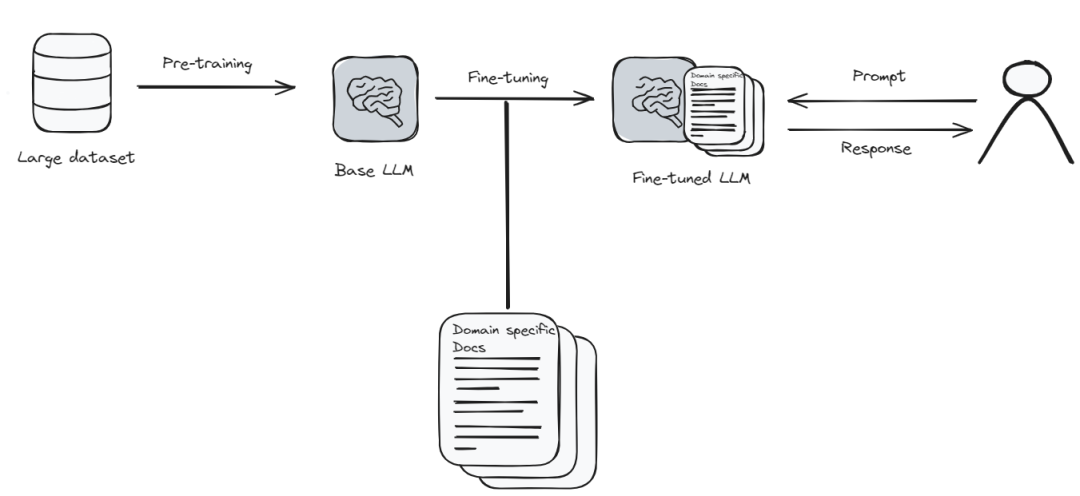
由于微调需要大量的计算资源和时间,可能会很昂贵。但是,如果你需要让模型非常了解特定主题,那么微调很有必要。这就像是教模型成为你感兴趣的领域的专家,微调后的模型可以给出更准确、更接近你想要寻找的答案。
优点:
-
定制化:可以定制,使模型能够生成特定领域或风格的内容。
-
提高准确性:通过在特定的数据集上训练,模型响应更准确。
-
适应性:微调后的模型可以更好地处理小众主题、原始训练中未涵盖的最新信息。
缺点:
-
成本:微调需要大量的计算资源,使其比提示工程更昂贵。
-
技术技能:需要更深入地理解机器学习和语言模型架构。
-
数据需求:高质量的微调需要大量且精心准备的数据集,这可能很难编译。
检索增强生成(RAG)
检索增强生成(RAG)类似将语言模型与知识库相结合。当模型需要回答问题时,它会首先从知识库中查找并收集相关信息,然后基于这些信息回答问题。这就像模型快速检查信息库,以给出最佳答案。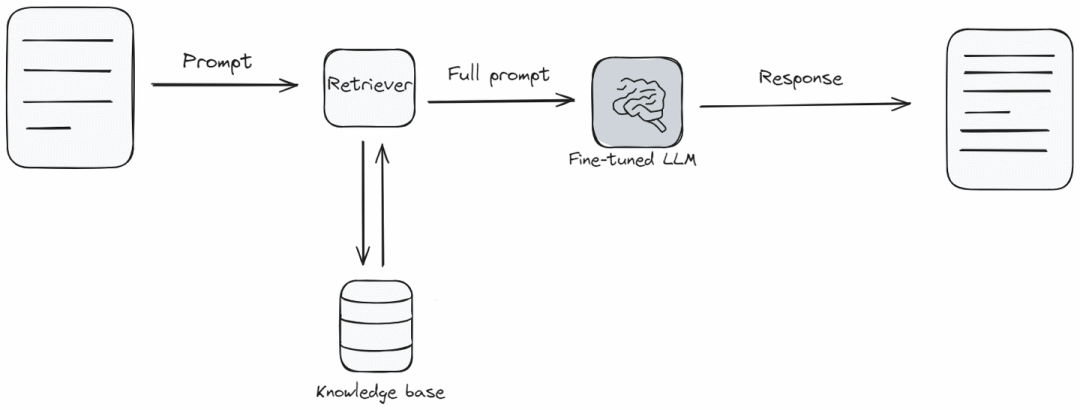
在需要获取最新信息,或者需要回答超出模型原始学习范围的更广泛话题时,RAG尤其有用。在技术实现难度和成本方面,RAG是中等难度。它之所以出色,是因为它帮助语言模型提供新鲜且详细的答案。但是,和微调一样,它需要额外的工具和信息才能很好地工作。RAG系统的成本、速度和响应质量严重依赖于向量数据库——RAG系统非常重要的一部分。MyScale
就是这样一个向量数据库,与其他向量数据库相比,使用费用几乎减半,且性能提升3倍。你可以在这里查看基准测试。最重要的是,你不需要学习任何外部工具或语言来访问MyScale。
优点:
-
动态信息:通过利用外部数据源,RAG可以提供最新和高度相关的信息。
-
平衡:兼具提示工程的便捷性和微调的定制化。
-
上下文相关性:通过额外的上下文增强模型的响应,输出更准确和细致。
缺点:
-
复杂性:实施RAG可能很复杂,需要集成语言模型和检索系统。
-
资源密集型:虽然比完整的微调资源消耗少,但RAG仍然需要相当大的计算资源。
-
数据依赖性:输出的质量严重依赖于输入信息的相关性和准确性。
提示工程 vs 微调 vs RAG
现在让我们对比一下提示工程、微调和RAG。这个表格列出了它们之间的差异,你可以依此决定哪种方法更满足你的需求。
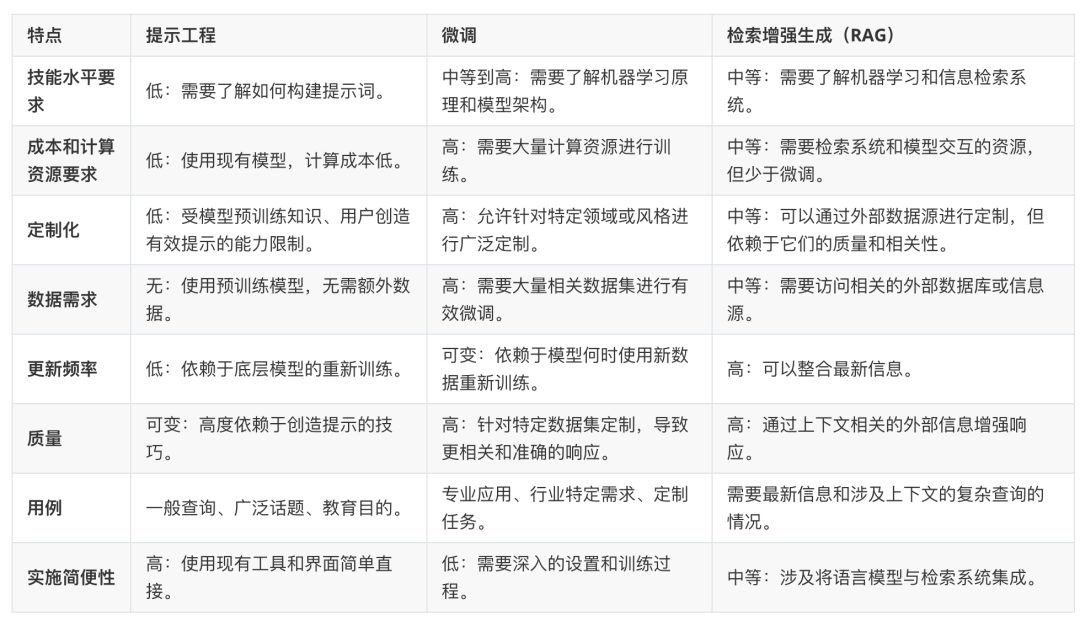
这个表格分解了提示工程、微调和RAG的关键点。它应该能帮助你理解哪种方法在不同情况下可能效果最好。我们希望这个比较能帮助你为你的下一个任务选择合适的工具。
RAG - 提升你的AI应用的最佳选择
RAG是一种独特的方法,它将传统语言模型的强大功能与外部知识库的精确性结合起来。这种方法在几个方面脱颖而出,使其在特定情境下比单纯的提示词或微调更具优势。首先,RAG通过实时抓取最新数据,保障了信息的及时更新与相关性,这一点在新闻查询等需要即时信息的应用中尤为重要。其次,RAG在个性化定制和资源消耗之间取得了恰当的平衡。它不像完全微调那样需要巨大的计算资源,而是提供了一种更为灵活、更为节省资源的运作方式。这降低了使用门槛,使得更多的用户和开发者能够轻松地利用这一技术。
最后,RAG的混合特性成功弥合了大型语言模型(LLMs)广泛的生成能力和知识库中具体、详细信息之间的差距。这使得输出结果不仅相关和详尽,而且在上下文层面也得到了丰富。一个优化的、可扩展的、成本效益高的向量数据库解决方案能够极大地提升RAG应用的性能和功能性。
结论
总之,无论你选择提示工程、微调还是检索增强生成(RAG),取决于你的具体需求、可用资源和期望结果。每种方法都有其独特的优势和局限性。提示工程易于访问且成本效益高,但定制化程度较低。微调提供详细的定制化,但成本和复杂性较高。RAG则取得了平衡,提供最新和特定领域的信息,实现复杂度适中。
参考资料
什么是RAG:https://research.ibm.com/blog/retrieval-augmented-generation-RAG RAG是如何工作的:https://myscale.com/blog/how-does-retrieval-augmented-generation- system-work/__提示词基础知识:https://www.promptingguide.ai/introduction/basics 微调的方法及最佳实践:https://www.turing.com/resources/finetuning-large-language-models 大模型训练流程及四个关键要素:https://www.run.ai/guides/machine-learning-engineering/llm- training
- 本文由活水智能编译,转载请注明出处