涌动的思维,流淌的灵感,滴滴涓流汇聚成创造力的瀑布。本期为你带来全新版块「活水创意Flow」,不仅分享创意,还邀请你跟随这股 Flow,一同探索、体验和传递源源不断的创意。
热点回顾
微软推出开源的 Gorilla LLM,在 API 调用方面超越 GPT-4
据伯克利大学研究页面显示,微软研究院近日联手加州大学伯克利分校的研究者推出了一款全新的大语言模型 Gorilla,一种可以提供适当 API 调用的 LLM,在三个庞大的机器学习中心数据集上进行训练:Torch Hub、TensorFlow Hub 和HuggingFace。研究论文显示,Gorill 在准确性、灵活性等 API 调用方面的表现比 GPT-4更出色。即使 API 文档发生更改,Gorilla 也可以在调用 API 时保证生成语言的准确性。此。Gorilla还可以为没有训练数据集的 API,生成正确的 API 调用。ref. https://gorilla.cs.berkeley.edu/探索之问: Gorill 如何解决大型语言模型的幻觉问题,提高其输出的可靠性和适用性?Gorill 在与API 调用结合方面的优势是什么?与 GPT-4 等现有模型相比,它的优势和局限性是什么?
OpenAI 推出网络爬虫 GPTBot,可以自动从整个互联网上抓取数据
OpenAI 推出了一个网络爬虫工具 GPTBot,能够自动抓取网站的数据。OpenAI 称网络爬虫将过滤删除需要付费强访问的来源,同时也会删除个人身份信息(PII)或违反其政策的文本,得到的数据则会被用来训练 GPT-4 和 GPT-5 等大模型。GPTBot 的推出展示了 OpenAI 在 AI 模型训练方面的新尝试,也引发了有关数据使用和道德的讨论,还有人表示“信息被爬走就很可能意味着永远无法删除”。如果你不希望 GPTBot 访问你的网站,你可以将 GPTBot 添加到你网站的 robots.txt 文件中。ref. https://platform.openai.com/docs/gptbothttps://www.infoq.cn/article/IzPVkcZg0jeHGcD4xP7H探索之问: GPTBot 如何确保数据的合法和道德抓取?GPTBot 的推出可能会改变 AI 模型训练的数据收集方式,这将如何影响 AI 领域的未来发展和创新?网站所有者如何在支持 AI 发展与保护自身利益之间找到平衡?
Google 推出 Project IDX,把全栈多平台应用程序开发的整个流程带到云端
Google 推出一个名为 Project IDX 的实验项目,旨在改善全栈、多平台应用开发的工作流程。Project IDX 是构建在 Google Cloud 上的一个基于浏览器的代码环境,由 Codey(一种基于PaLM 2的AI模型)提供支持。Project IDX 内置了代码生成、在不同编程语言之间翻译代码、解释代码等 AI 功能,允许从 GitHub 导入现有项目,或使用流行的框架和语言创建新项目。Project IDX 支持 Angular、Next.js、React、Svelte 和 Flutter 等主流的框架和语言,支持预览多应用平台的程序,如安卓、iOS和 Web。此外,通过集成 Firebase Hosting,IDX 还简化了应用的部署过程,开发者不需要配置环境,直接打开浏览器就能进入开发流程。Project IDX 希望开发人员应能够在任何地方、任何设备上进行开发,具有本地开发的全部功能。可在这里加入等待列表:https://idx.dev/ref. https://developers.googleblog.com/2023/08/introducing-project-idx-experiment- to-improve-full-stack-multiplatform-app-development.html探索之问: Project IDX 如何与现有开发工具集成?文章提到的 Codey 和 PaLM 2 等AI模型如何帮助开发人员更快地编写更高质量代码?
Stability AI 推出StableCode,首个用于编程的生成式AI产品
继文生图 Stable Diffusion、SDXL1.0、语言模型 StableLM 之后,独角兽 Stability AI 宣布推出,首个用于编码的生成式AI产品——StableCode。StableCode 提供了三种不同模型:通用基本模型、指令模型,已经支持多达16,000个 token 的长上下文窗口模型。旨在帮助程序员进行日常工作,同时也为新的开发人员提供了一个很好的学习工具。基础模型首先在BigCode 的堆栈数据集(v1.2)上的多种编程语言上进行训练,然后进一步使用 Python、Go、Java、Javascript、C、Markdown 和 C++ 等流行语言进行训练。在基础模型建立后,指令模型针对特定用例进行了调整,以帮助解决复杂的编程任务。ref. https://stability.ai/blog/stablecode-llm-generative-ai-coding探索之问: StableCode 如何通过三种不同的模型结合来提高开发人员的编程效率?StableCode 的训练过程是如何确保其能够适应各种编程语言和复杂任务的?StableCode 在未来可能会如何影响新开发人员的学习路径和专业程序员的工作流程?
英伟达开源了可定制虚拟角色的 AI 模型 CALM,可零样本学习人类复杂动作
英伟达 NVIDIA 开源了名为 CALM(Conditional Adversarial Latent Models)的 AI 模型,这是一种用于生成用户可控交互式虚拟角色的多样化和可指导行为的方法,可以模仿“人类的动作”,无需额外训练就能自由合成和控制虚拟角色的动作。通过模仿学习,CALM 学习到了一种可以捕捉人类动作复杂性和多样性的动作表征,并能直接控制角色的动作。该方法可以联合学习控制策略和动作编码器,对给定动作的关键特征进行重建,而不仅仅是复制。CALM 的训练分为三个阶段:底层训练、方向控制和推理。在底层训练阶段,CALM 学习了一个编码器和解码器,将运动映射到低维潜在表示。方向控制阶段训练了一个高级任务驱动策略来选择潜在变量,从而实现运动方向的控制。最后的推理阶段将前两个阶段训练的模型组合起来,无需额外训练就能组成复杂的动作。结果表明,CALM 可以通过学习语义动作表征,控制生成的动作,并为更高层的任务训练提供风格调整。训练完成后,用户可以在类似电脑游戏的界面上,直观地控制角色。ref. https://research.nvidia.com/labs/par/calm/探索之问: CALM 如何捕捉人类运动的复杂性,允许用户通过类似视频游戏的界面直接控制虚拟角色?除了视频游戏,CALM 可否用于电影制作、虚拟现实或其他类型的交互式媒体?与现有的虚拟角色控制技术相比,CALM 提供了哪些新的可能性和挑战?
智源推出开源的中英文语义向量模型 BGE,与LangChain 结合可定制本地知识问答助手
智源发布了开源的中英文语义向量模型 BGE(BAAI General Embedding),在中英文语义检索精度与整体语义表征能力方面表现出色。BGE 保持同等参数量级模型中的最小向量维度,降低了使用成本。若将 LangChain 与智源 BGE 结合,可以轻松定制本地知识问答助手,从而降低训练成本。目前,BGE 中英文模型均已开源,代码及权重均采用 MIT 协议,支持免费商用。FlagEmbedding:https://github.com/FlagOpen/FlagEmbeddingBGE 模型链接:https://huggingface.co/BAAI/BGE 代码仓库:https://github.com/FlagOpen/FlagEmbeddingC-MTEB 评测基准链接:https://github.com/FlagOpen/FlagEmbedding/tree/master/benchmarkref. https://www.51cto.com/article/763059.html探索之问: BGE 模型在商业和科研领域的具体应用是什么?智源如何平衡开源社区和商业利益?C-MTEB 作为一个全面的评测基准,将如何促进中文语义向量模型的研究和创新?
百川智能发布闭源大模型 Baichuan-53B,主要面向B端用户
百川智能宣布推出新一代大模型 Baichuan-53B,定位闭源大模型,官方表示该大模型目前在写作、文本创作能力方面,已经“达到行业最好的水平”。百川智能强调了 Baichuan-53B 的三个技术优势:预训练数据、搜索增强和对齐能力,其中预训练数据和搜索增强与百川团队的搜索引擎经验有较强相关性。百川智能此前已经开源了 Baichuan-7B、Baichuan-13B 两个通用大语言模型,此次发布的 Baichuan-53B 主要面向 B 端用户提供服务。百川智能创始人、CEO王小川表示,由于模型变大后部署成本会增加,所以选择使用闭源并让大家在线调用。发布后,该大模型也将启动内测,并计划下个月开放 API。王小川还透露,百川智能还将发布千亿参数规模的大模型对标 GPT-3.5。ref. https://chat.baichuan- ai.com/home探索之问: 闭源的大模型对于开发者和企业来说意味着什么?百川智能如何利用其搜索引擎经验来加强模型的预训练数据和搜索增强?随着各大公司纷纷发布大模型,这是否预示着 AI 领域的一个新的竞争时代?
英伟达推出新一代超级 AI 芯片 GH200 和一系列重磅更新,宣布与 Hugging Face 建立合作伙伴关系
在SIGGRAPH 2023的特别演讲中,NVIDIA 的创始人兼 CEO Jensen Huang 强调了生成 AI 在数字化、高度互联世界中的迅速扩展。他宣布了一系列重要的新产品和合作,包括下一代 GH200 Grace Hopper Superchip 平台、NVIDIA AI Workbench(一种简化模型调整和部署的统一工具包)以及NVIDIA Omniverse的重大升级,其中包括生成 AI 和 OpenUSD。NVIDIA 还宣布了与 Hugging Face 建立合作伙伴关系,将生成AI超级计算能力带到数百万开发大型语言模型(LLMs)和其他先进AI应用的开发者手中。ref. https://blogs.nvidia.com/blog/2023/08/08/siggraph-2023-special- address/https://nvidianews.nvidia.com/news/nvidia-and-hugging-face-to-connect- millions-of-developers-to-generative-ai-supercomputing探索之问: NVIDIA 推出的 Grace Hopper Superchip、AI Workbench 和 Omniverse 升级等技术如何共同推动生成 AI 的创新和应用?NVIDIA 如何看待图形和人工智能之间的关系?NVIDIA 如何通过建立合作关系,共同推动 AI 和3D 图形领域的开放创新和协作?
本周精选
让25个AI代理居住在数字化的「西部世界」沙盒城镇中,2023年最具启发性的 AI Agent 实验性项目 StanfordSmallville
开源了
斯坦福的 Smallville 项目现已正式开源!其中包括 25
个AI智能体,它们居住在一个数字化的西部世界中,无意识地生活在模拟环境中。它们上班、聊天、组织社交活动、结交新朋友,甚至坠入爱河。每个智能体都有独特的个性和背景故事。这一项目揭示了
AGI 无限的可能性,游戏或许将是首先感受到影响的领域。通过这个项目,还可以学习 Prompt
设计方法。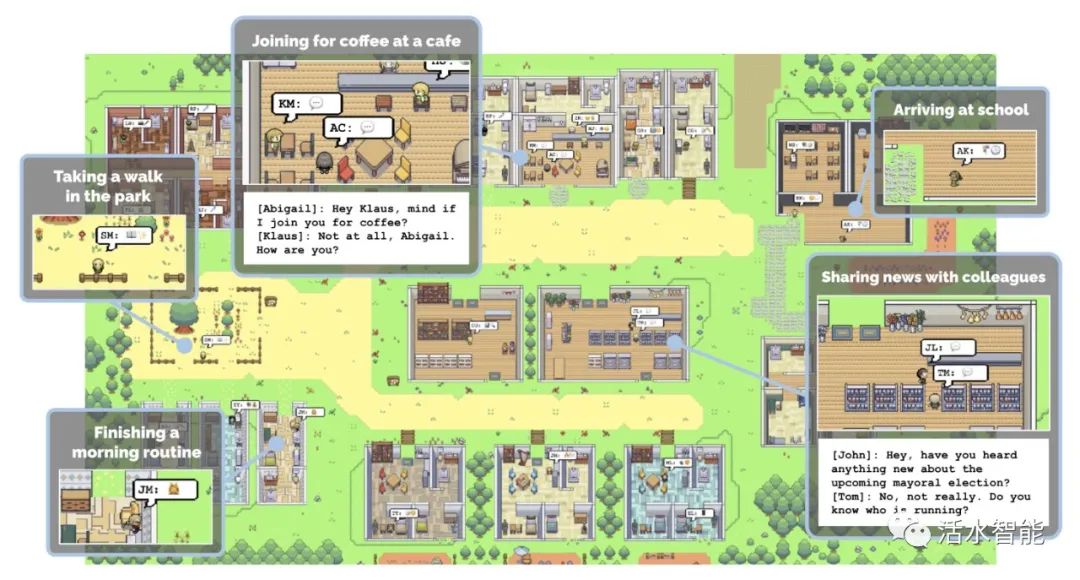 全文阅读:https://twitter.com/DrJimFan/status/1689315683958652928教程:https://mp.weixin.qq.com/s/tiZTxYn6Qo0ciizV5N5Irg几天之后,著名投资机构
a16z 用 NextJS + Tailwind 重写了这个 25
个AI小人的虚拟小镇,并将代码开源。项目地址:https://github.com/a16z-infra/ai-
town演示地址:https://www.convex.dev/ai-town
全文阅读:https://twitter.com/DrJimFan/status/1689315683958652928教程:https://mp.weixin.qq.com/s/tiZTxYn6Qo0ciizV5N5Irg几天之后,著名投资机构
a16z 用 NextJS + Tailwind 重写了这个 25
个AI小人的虚拟小镇,并将代码开源。项目地址:https://github.com/a16z-infra/ai-
town演示地址:https://www.convex.dev/ai-town
一份关于开源 LLM 研究历史的调查
 这份关于开源
LLM 研究历史的调查,涵盖从早期(如 OPT 和 BLOOM)到最近(如
LLaMA-2)的模型,对LLM感兴趣的同学一定不要错过。全文阅读:https://cameronrwolfe.me/home
这份关于开源
LLM 研究历史的调查,涵盖从早期(如 OPT 和 BLOOM)到最近(如
LLaMA-2)的模型,对LLM感兴趣的同学一定不要错过。全文阅读:https://cameronrwolfe.me/home
4 张图表展示人工智能进展为何不可能放缓
过去十年,人工智能技术发展速度极快。从2016年击败围棋大师的突破,到现在能够超越人类识别图像和语音,AI 的进展令人震惊。文章强调了三个主要因素推动AI的进展:计算能力、数据和算法。其中,计算能力的增长允许AI系统消化更多的数据,从而学习更多的例子。数据的增长意味着 AI 系统可以更准确地建立变量之间的关系模型。算法的进展使 AI 开发人员能够更有效地使用计算和数据。这三个因素共同推动了 AI 的快速进展,并且大多数人预计这一趋势不会很快放缓。全文阅读:https://time.com/6300942/ai-progress-charts/
Tatiana Tsiguleva 从 Midjourney Discord 中统计出最受欢迎的68个提示词
Tatiana Tsiguleva 从 MJ Discord 频道中抓取了 15,943 条消息,将 JSON 上传到 ChatGPT 代码解释器提取
13,682 个唯一令牌,并按照受欢迎程度排序,选出了最受欢迎的 68 个 MJ
提示词。 全文阅读:https://twitter.com/ciguleva/status/1688778552253218816
全文阅读:https://twitter.com/ciguleva/status/1688778552253218816
『活水创意Flow』
想要阅读计算机领域的英文论文却无从下手?第一期「活水创意Flow」带来的是活水社群成员 Excelsior 关于“借助 GPT 进行英文论文的三轮式结构阅读”的精彩探索。借助 GPT 进行英文论文的三轮式结构阅读斯坦福大学 S. Keshav 在《How to Read a Paper》中提出三轮阅读法,可辅助进行论文的结构阅读:1.第一轮:快速扫描,阅读摘要,回答核心问题,决定是否深入阅读。2.第二轮:深度阅读:读懂图表,把握重要观点及其关联。3.第三轮:深入理解:反思论文的假设,复现论文的思路过程。借助 GPT,快速应用这套方法的门槛显著降低。我们先让 GPT 阅读《How to Read a Paper》,提炼方法论,再用来阅读计算机领域的英文论文。总结方法并阅读:https://42share.com/gpt/TYJJQMZf1m单独开新窗口阅读:https://42share.com/gpt/TYJJQMZf1m
这是 GPT网页链接:https://chat.openai.com/c/e5ff11d9-050b-4e89-be22-e68dc1e01c4d
需要插件
WebPilot——用于读取《How to Read a Paper》
txyz.ai——用于读取arxiv ID,查询对应的论文
对话要点
为了保证 GPT 不忘记上文,在进行第二三轮时:
- 每次都提及“请阅读本文”,最好给出标题和ID。
- 指明本次阅读的要点(从GPT输出的内容中复制)。
GPT辅助阅读的深度始终有限,在第一轮的辅助效果最好。
应用
1.可以为需要细读的论文单独开一个聊天窗口,也可以让 GPT 只辅助快速扫描,进行文献批量速读(需要批量获取ID)。2.在进行速读后,即可为论文撰写文献笔记、卡片笔记。3.除了计算机领域的论文,其它领域的论文也可以借助三轮阅读法进行结构性阅读。

欢迎加入阳志平老师创办的「玩转GPT」知识星球,了解更多前沿论文、使用技巧、原创产品,与 2100+ 成员一起碰撞无限创意。还有有趣有料的「冰桶挑战赛」等活动等你来参与!
👇 加入知识星球,一起玩转GPT!