
来源:MyScale
编译:活水智能
向量索引不仅仅是存储数据,它是通过智能组织向量嵌入来优化检索过程。
本文将介绍向量索引的基础知识以及不同技术的实现方法。
希望对想深入理解大模型关键技术的伙伴有所帮助。
在数据库发展的早期阶段,数据被存储在基本表格中。这种方法很简单,但随着数据量的增加,管理和检索信息变得越来越困难和缓慢。
随后,引入了关系型数据库,提供了更好的数据存储和处理方式。
关系型数据库中的一个重要技术是索引,这与书籍在图书馆中的存储方式非常相似。与其在整个图书馆中寻找,不如直接前往特定的区域找到所需的书。
数据库中的索引也是类似的方式,加快了找到所需数据的过程。
在这篇文章中,我们将介绍向量索引的基础知识以及不同技术实现方法。
什么是向量嵌入
向量嵌入是从图像、文本和音频转换而来的数值表示。简单来说,每个项目都会创建一个单一的数学向量,用来捕捉该项目的语义或特征。
这些向量嵌入更容易被计算系统理解,并且与机器学习模型兼容,以理解不同项目之间的关系和相似性。
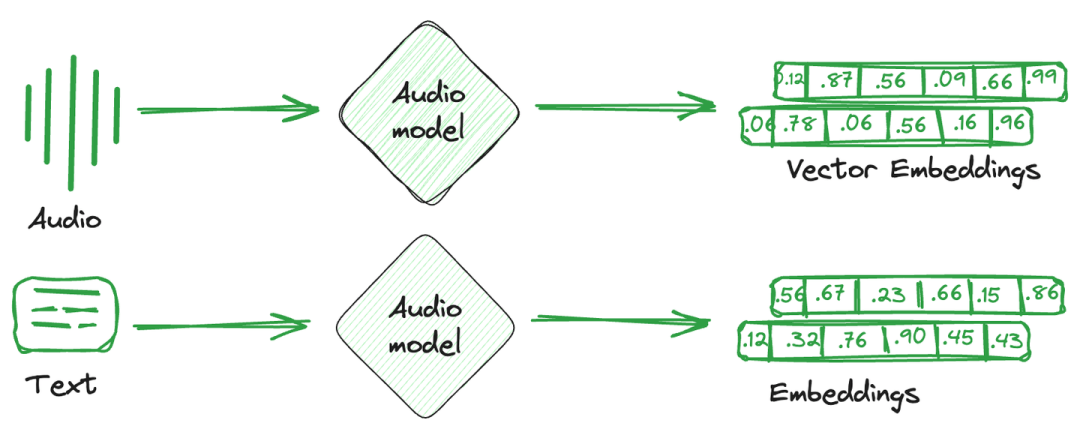
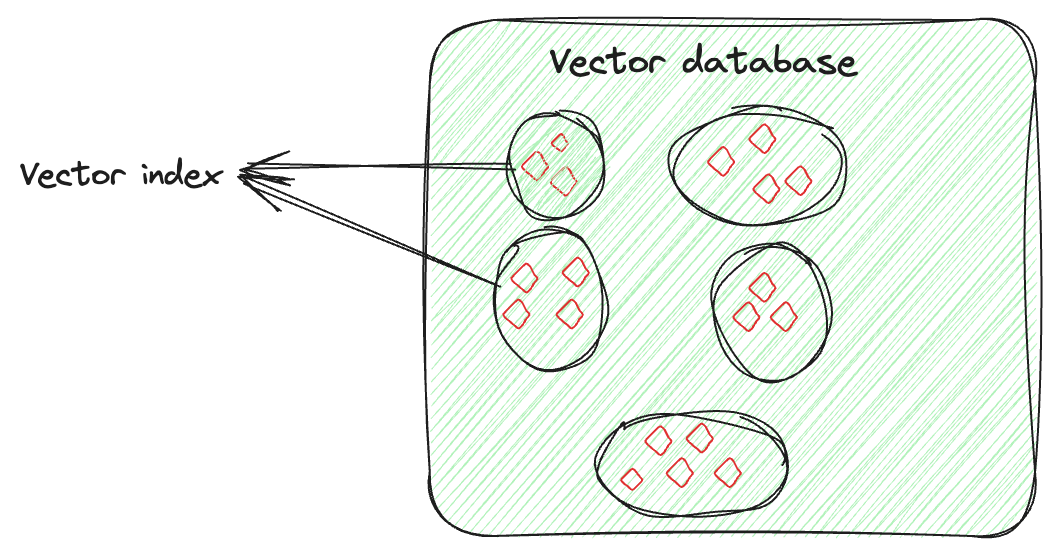
用于存储这些嵌入向量的专门数据库被称为向量数据库。这些数据库利用嵌入的数学特性,使相似的项目能够存储在一起。
不同的技术用于将相似的向量存储在一起,而将不相似的向量分开。这些就是向量索引技术。
什么是向量索引
向量索引(Vector Index)不仅仅是存储数据,它是通过智能组织向量嵌入来优化检索过程。
这种技术涉及高级算法,将高维向量整齐地排列成一种可搜索且高效的方式。这种排列不是随机的,而是以相似的向量分组的方式进行的。
向量索引允许快速且准确的相似性搜索和模式识别,特别是在搜索大规模和复杂的数据集时。
假设你有一个向量表示每张图片的特征。向量索引会组织这些向量,使得查找相似图片变得更容易。
你可以将其想象为按人组织照片,这样如果你需要某个特定事件中的某个人的照片,你不需要浏览所有的照片,只需在那个人的集合中寻找即可。
常见的向量索引技术
根据具体需求,使用不同的索引技术。让我们讨论一些常见的技术。
倒排文件(IVF)
这是最基本的索引技术。它使用如K-means聚类等技术将整个数据分成多个簇。数据库中的每个向量被分配到一个特定的簇。
这种结构化的向量排列使得搜索查询更快。当有新查询时,系统不会遍历整个数据集,而是识别最近或最相似的簇,并在这些簇内搜索特定的文档。
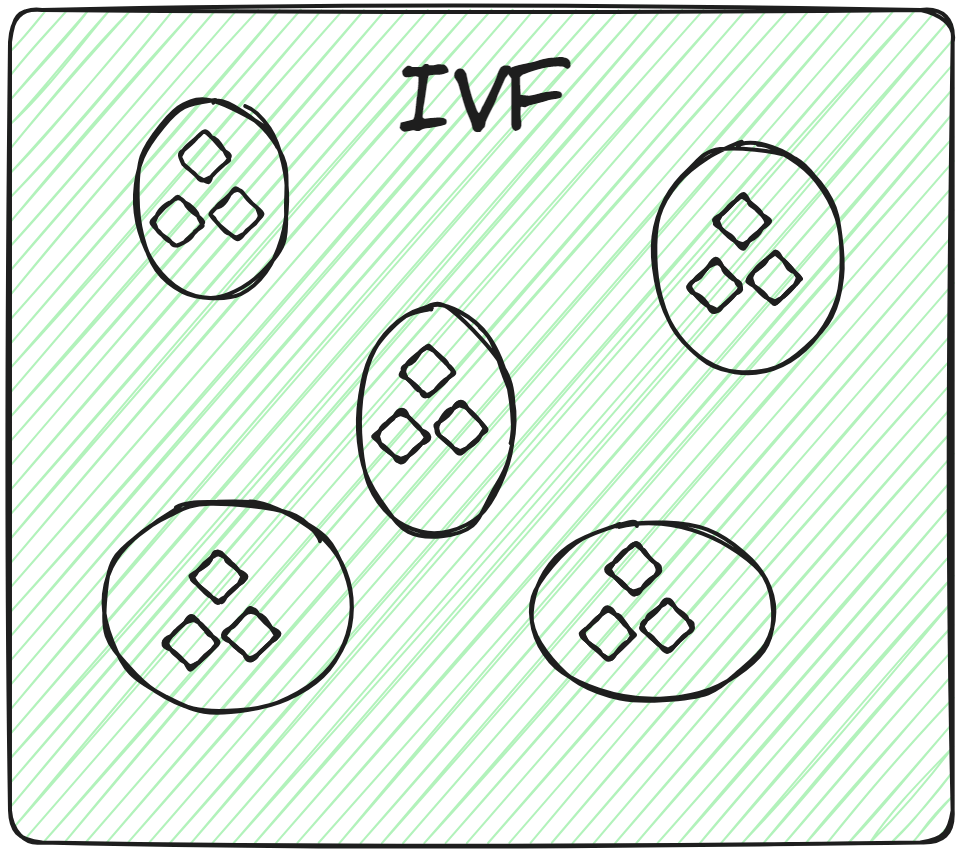
在相关簇内进行蛮力搜索,而不是在整个数据库中搜索,不仅提高了搜索速度,还显著减少了查询时间。
IVF的变体:IVFFLAT、IVFPQ和IVFSQ
根据应用的具体要求,IVF有不同的变体。让我们详细看看它们。
IVFFLAT
IVFFLAT是IVF的一种简单形式。它将数据集分成多个簇,但在每个簇内,使用平坦结构(因此得名“FLAT”)存储向量。IVFFLAT旨在优化搜索速度和准确性之间的平衡。
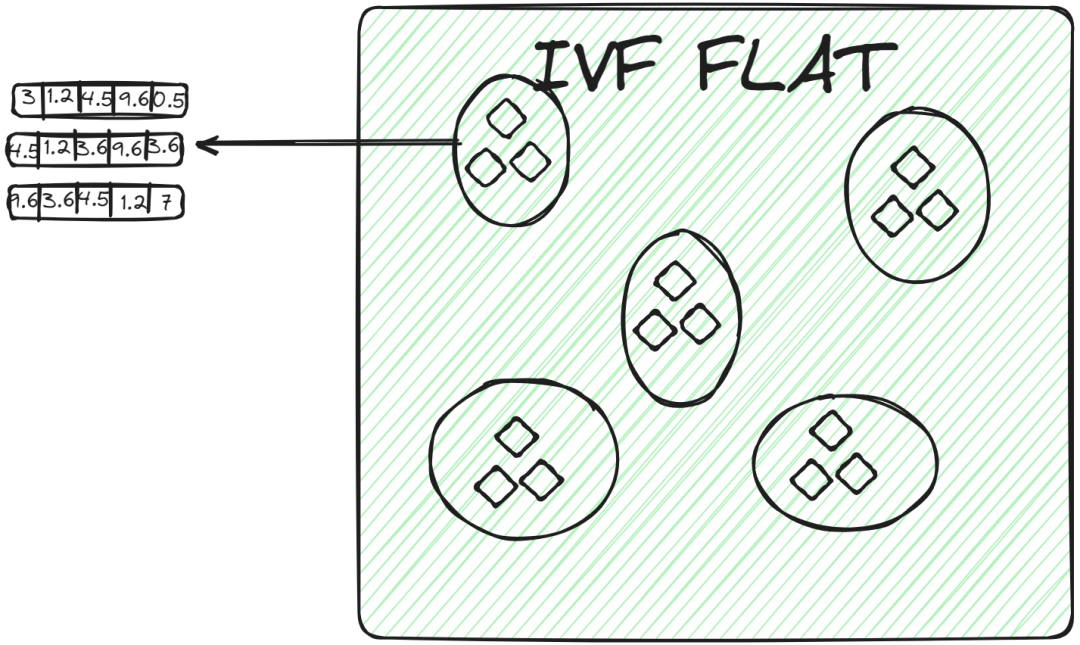
在每个簇中,向量以简单的列表或数组形式存储,没有额外的细分或层次结构。当查询向量分配到一个簇时,通过蛮力搜索找到最近的邻居,检查该簇列表中的每个向量并计算其与查询向量的距离。
IVFFLAT适用于数据集不是特别大且目标是实现高搜索准确性的场景。
IVFPQ
IVFPQ是IVF的高级变体,代表倒排文件与乘积量化。它也将数据分成簇,但每个簇中的向量被分解成更小的向量,每部分通过乘积量化 编码或压缩成有限数量的比特。
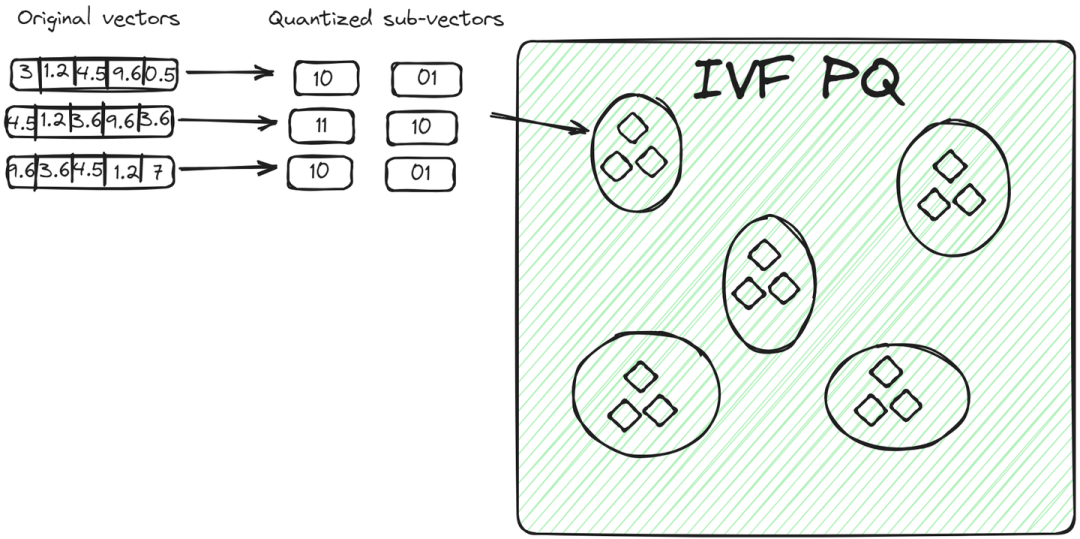
对于查询向量,一旦识别出相关簇,算法将查询的量化表示与簇内向量的量化表示进行比较。
由于通过量化实现的降维和大小减少,这种比较比比较原始向量更快。这种方法相对于前一种方法有两个优点:
-
• 向量以紧凑的方式存储,占用的空间比原始向量少。
-
• 查询过程更快,因为它不是比较所有原始向量,而是比较编码后的向量。
IVFSQ
IVFSQ(标量量化文件系统)与其他IVF变体一样,也将数据分成簇。但其主要区别在于量化技术。在IVFSQ中,每个簇中的向量通过标量量化处理。
这意味着向量的每个维度分别处理。
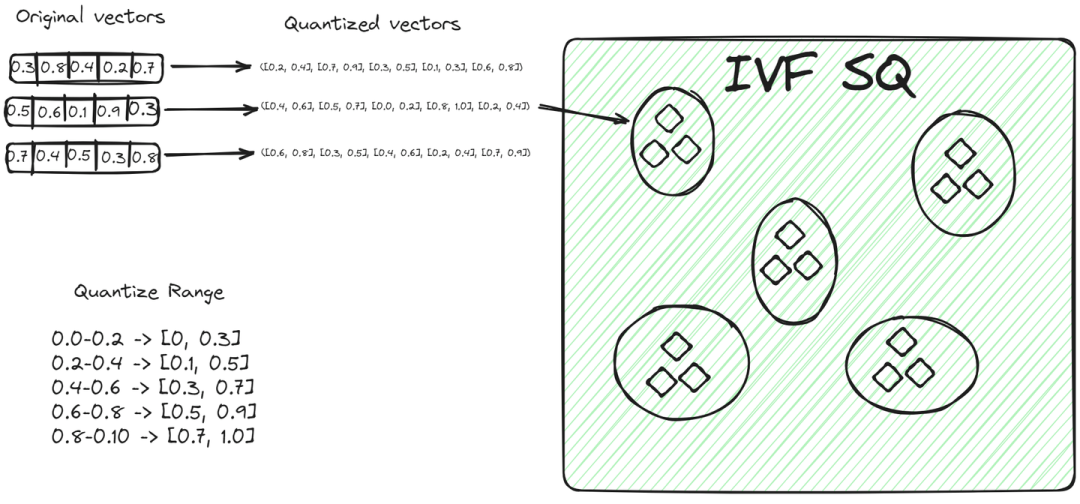
简单来说,对于向量的每个维度,我们设置一个预定义值或范围。这些值或范围帮助决定向量属于哪个簇。
然后将向量的每个分量与这些预定义值匹配,找出其在簇中的位置。将每个维度单独分解和量化的方法使过程更加简单。
对于低维数据,这种方法尤其有用,因为它简化了编码并减少了存储所需的空间。
分层可导航小世界(HNSW)算法
分层可导航小世界(HNSW)算法是一种高效存储和获取数据的复杂方法。
其图结构受两个不同技术的启发:概率跳表 和可导航小世界(NSW) 。为了更好地理解HNSW,首先让我们尝试理解与该算法相关的基本概念。
跳表
跳表(skip list)是一种先进的数据结构,它结合了两种传统结构的优点:链表的快速插入能力和数组的快速检索特性。
它通过多层架构实现这一点,数据在多个层次上组织,每个层次包含一部分数据点。
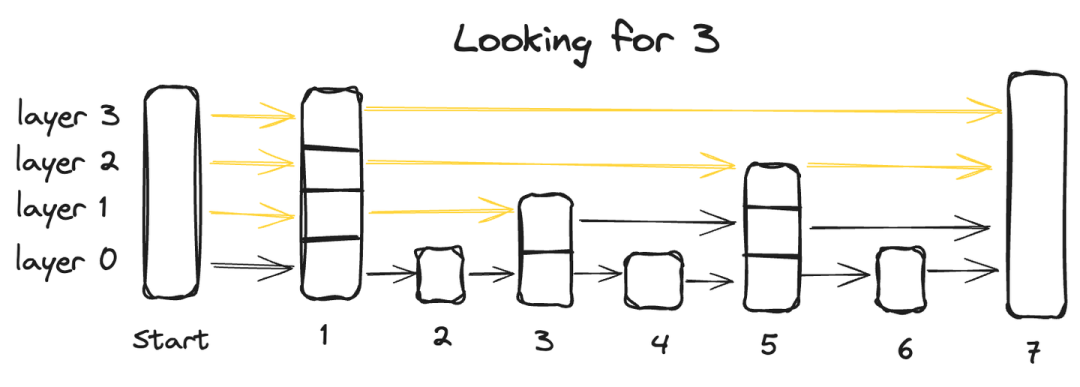
从包含所有数据点的底层开始,每个后续层次都会跳过一些点,因此数据点更少,最顶层的数据点数量最少。
在跳表中搜索数据点,我们从最高层开始,从左到右探索每个数据点。在任何时候,如果查询值大于当前数据点,我们就回到下一层的前一个数据点,然后从左到右继续搜索,直到找到准确的点。
可导航的小世界(NSW)
可导航的小世界(NSW)类似于一个近似图 ,其中节点根据它们之间的相似度连接在一起。使用贪婪 方法搜索最近邻点。
我们总是从一个预定义的入口点开始,它连接到多个附近的节点。我们确定哪些节点离我们的查询向量最近,并移动到那里。
这个过程反复进行,直到没有节点比当前节点更接近查询向量,这就是算法的停止条件。
现在,让我们回到主题,看看它是如何工作的。
HNSW的开发过程
在HNSW中,我们从跳表中得到启示,它像跳表一样创建层。但对于数据点之间的连接,它在节点之间建立了类似图的连接。每一层的节点不仅连接到当前层的节点,还连接到下层的节点。
顶部的节点非常少,当我们向下移动到较低的层次时,节点的密度会增加。最后一层包含数据库的所有数据点。这就是HNSW架构的样子。
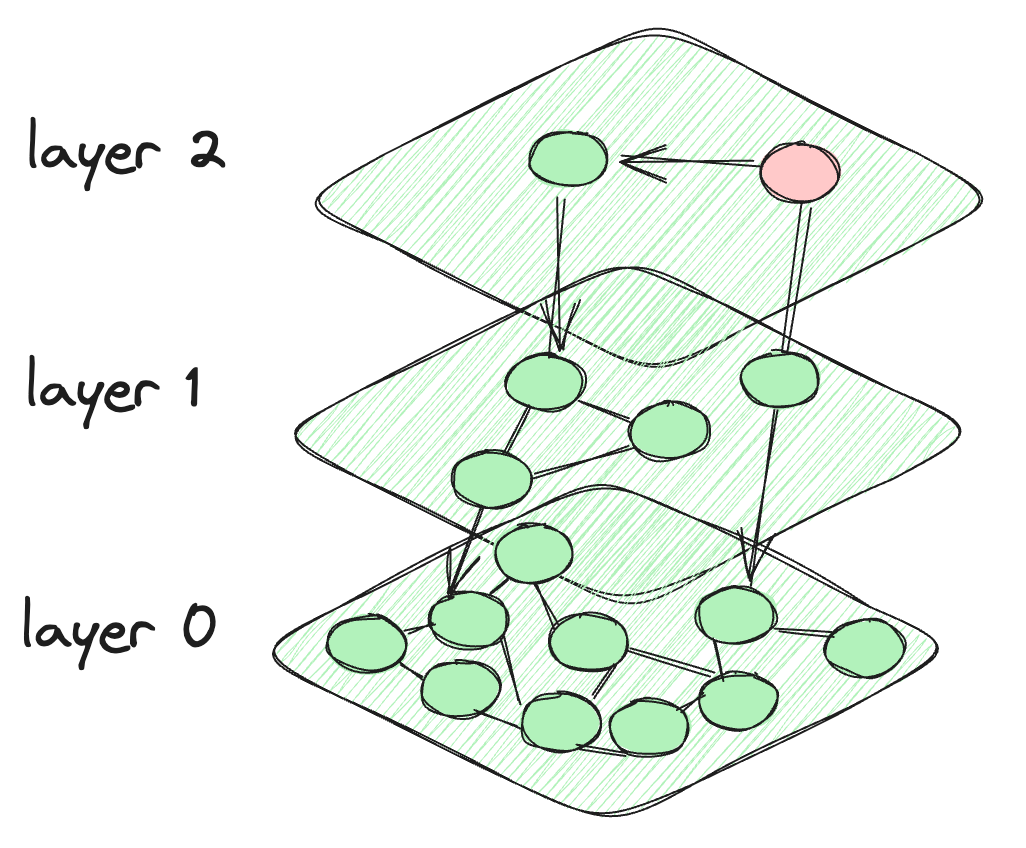
HNSW算法的架构
HNSW中的搜索查询如何工作
算法从最顶层的预定义节点开始。然后计算当前层的连接节点和下一层的节点之间的距离。
如果到下一层的某个节点的距离小于到当前层节点的距离,算法就转移到较低的层。这个过程一直持续到达到最后一层,或者到达一个与所有其他连接节点的距离最小的节点。
最后一层,也就是第0层,包含所有的数据点,为数据集提供了全面和详细的表示。这一层对于确保搜索包含所有可能的最近邻是至关重要的。
HNSW的不同变体:HNSWFLAT和HNSWSQ
就像IVFFLAT和IVFSQ一样,其中一个存储原始向量,另一个存储量化范围,HNSWFLAT和HNSWSQ也采用相同的过程。
在HNSWFLAT中,原始向量按原样存储,而在HNSWSQ中,向量以量化的形式存储。
除了这个关于数据存储的关键差异外,HNSWFLAT和HNSWSQ的索引和搜索的整体过程和方法是相同的。
多尺度树图(MSTG)算法
标准的倒排文件索引(IVF)将向量数据集划分为许多簇,而分层可导航小世界(HNSW)为向量数据构建一个层次图。
然而,这些方法的一个显著限制是,对于大规模数据集,索引大小的大幅增长,需要将所有向量数据存储在内存中。
虽然像DiskANN这样的方法可以将向量存储卸载到SSD,但它构建索引慢,过滤搜索性能非常低。
多尺度树图(MSTG)由MyScale开发,它通过结合层次树聚类和图遍历,内存和快速的NVMe SSDs,克服了这些限制。
MSTG显著降低了IVF/HNSW的资源消耗,同时保持了出色的性能。它构建快,搜索快,而且在不同的过滤搜索比例下仍然快速准确,同时资源和成本效率高。
结 论
向量数据库革新了数据存储的方式,不仅提高了速度,而且在人工智能和大数据分析等多个领域提供了巨大的实用性。
在数据呈指数级增长的时代,特别是在非结构化形式的数据,向量数据库的应用是无限的。
定制的索引技术进一步增强了这些数据库的力量和效果,例如,提升过滤向量搜索。
MyScale通过独特的MSTG算法优化过滤向量搜索,为复杂的大规模向量搜索提供了强大的解决方案。