
来源:SciPhi
编译:活水智能
Triplex 是一款特别训练的三元组提取模型,可以将大量非结构化数据转化为结构化数据。
与 GPT-4o 相比,Triplex 在知识图谱构建方面性能更优,并且在零样本提示技术上表现更优,有效提升了知识图谱查询质量。而其成本却不到GPT-4o的十分之一。
Triplex 是开源的,可在 HuggingFace 和 ollama 上获取。
HuggingFace :https://huggingface.co/SciPhi/Triplex
ollama:https://ollama.com/sciphi/triplex
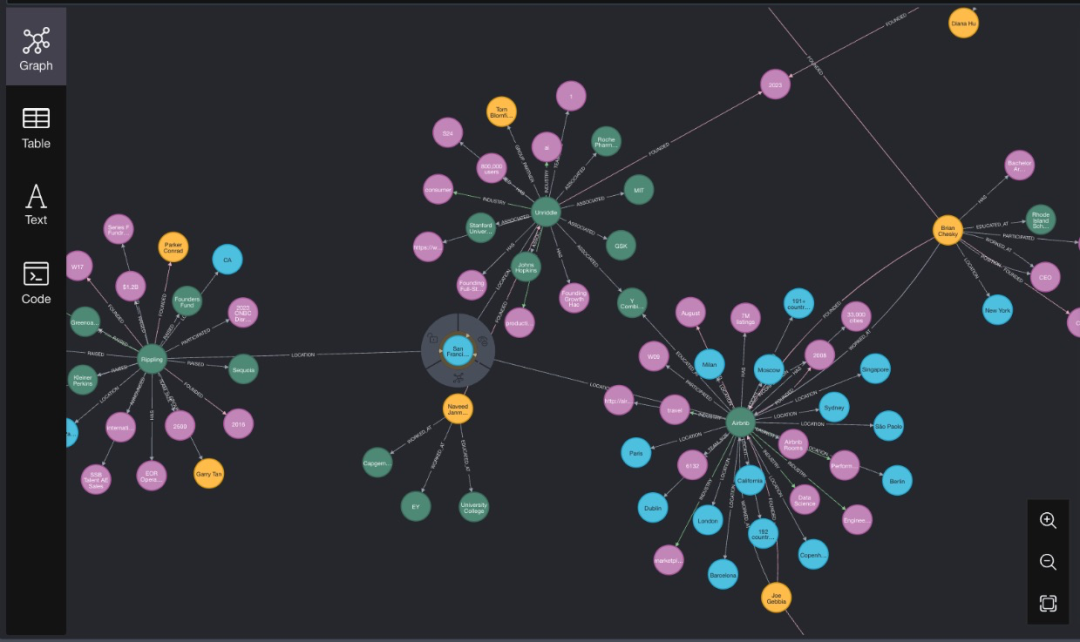 图1:知识图谱结构示意图
图1:知识图谱结构示意图
知识图谱在回答传统搜索引擎难以处理的复杂查询方面表现出色,尤其是涉及群体关系的查询。
例如,“提供科技学校毕业的 AI 从业人员名单。”微软最近发布的 GraphRAG 论文进一步提升了人们对知识图谱的兴趣。
然而构建知识图谱的过程一直以来都非常复杂且耗费资源,限制了其推广。据估计,微软的 GraphRAG 方法成本特别高,每个输入标记需要生成至少一个输出标记。这种高成本使得大多数应用难以承受。
Triplex 旨在通过将知识图谱生成成本降低十倍来颠覆这一现状。Triplex 通过将非结构化文本转化为“语义三元组”来降低成本,这些三元组是知识图谱的基本单元。
以下是 Triplex 处理简单句子的示例:
城市:巴黎 > 首都 > 国家:法国
城市:巴黎 > 位于 > 国家:法国
以及更复杂的输入:
艺术家:梵高 > 属于 > 艺术流派:后印象派
作品:星夜 > 创作于 > 艺术家:梵高
艺术家:梵高 > 属于 > 艺术流派:表现主义
艺术家:梵高 > 属于 > 艺术流派:野兽派
性 能
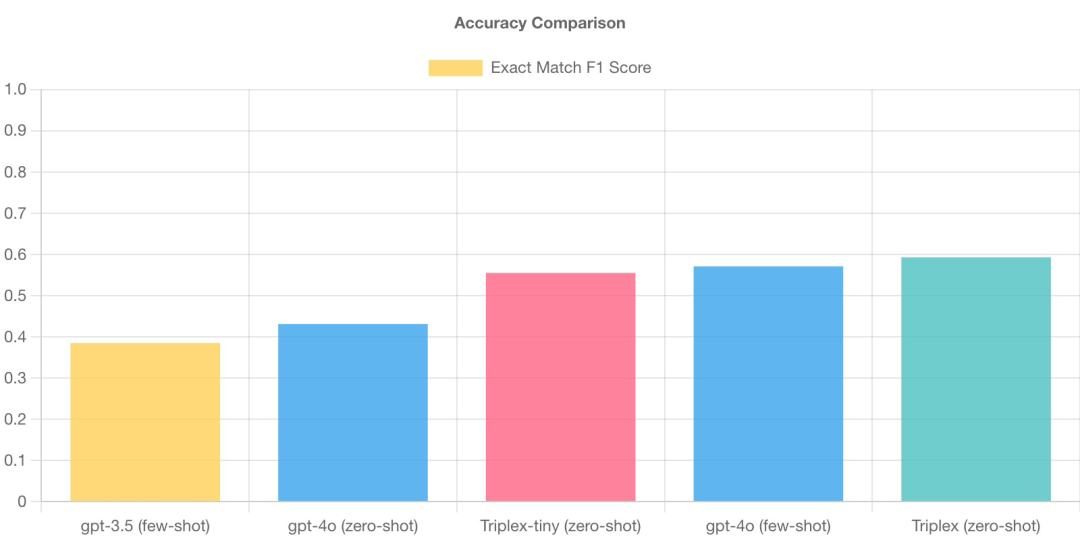
性能测试表明,Triplex 在成本和性能上都显著优于 GPT-4o。
准确性对比
价格对比
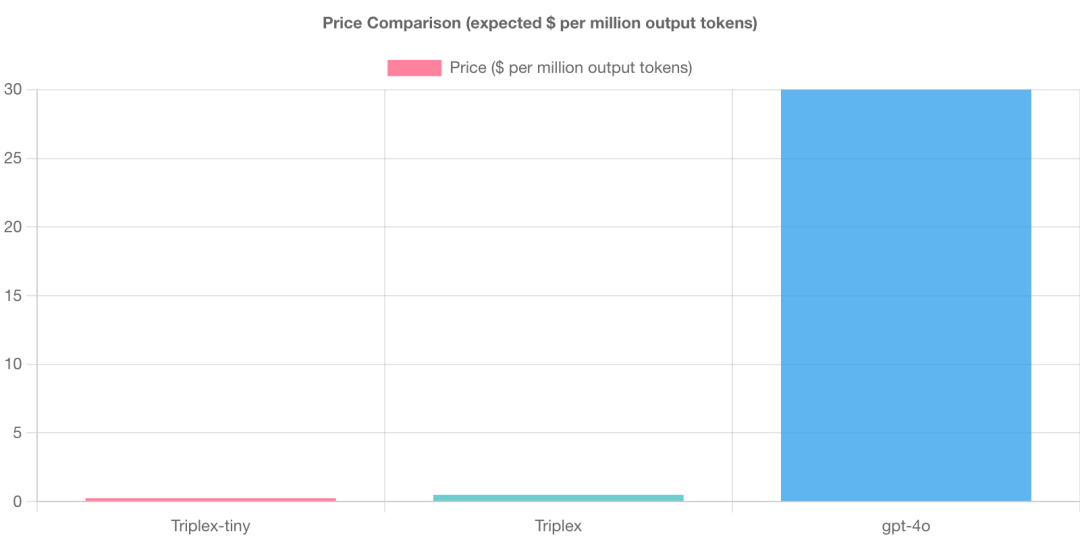
三元组提取模型的结果可与 GPT-4 相媲美,但成本却仅为其一小部分。这一显著的成本降低归功于 Triplex 的小型模型和无需少量示例上下文的能力。
在 SFT 模型的基础上,我们生成了更多基于偏好的数据集,通过多数投票和拓扑排序进一步使用 DPO 和 KTO 对 Triplex 进行训练。
这些额外的训练步骤显著提高了模型的性能。为了准确评估这些改进,我们使用 Claude-3.5 Sonnet 进行了严格评估。
评估中,我们对 Triplex-base、Triplex-kto 和 GPT-4o 进行了对比,结果如下表所示:
| 模型1 | 模型2 | 模型1胜 | 模型2胜 | 平局 |
|---|---|---|---|---|
| triplex-base | gpt-4o | 54% | 43% | 3% |
| triplex-kto | triplex-base | 66% | 26% | 8% |
| triplex-kto | gpt-4o | 56% | 40% | 4% |
Triplex 的卓越性能源于其在多样且全面的数据集上的进行训练。
模型利用了来自 DBPedia 和 Wikidata 等权威来源的专有数据集,以及基于网络文本和合成生成的数据集。
数据集来源确保了 Triplex 在各种应用中的多功能性和稳健性。
使 用
Triplex 还设计了 R2R RAG 引擎,结合 Neo4J 以立即利用 Triplex 进行本地知识图谱构建,这一用例因我们的工作而变得更加可行。
请阅读此处文档,了解如何开始使用,或直接试用Triplex。
文档:https://r2r-docs.sciphi.ai/cookbooks/knowledge-graph
获取更多信息可联系founders@sciphi.ai。
参考文献
[1] 自动知识图谱构建的全面调查:https://arxiv.org/abs/2302.05019
[2] 从本地到全球:一种面向查询的图 rag 方法:https://arxiv.org/abs/2404.16130
推荐阅读
超好用!五分钟内将文本转为图谱,可用于发现实体之间关系和规律,与文本对话
解读 Graph RAG:从大规模文档中发现规律,找到相互关系,速度更快,信息更全面!