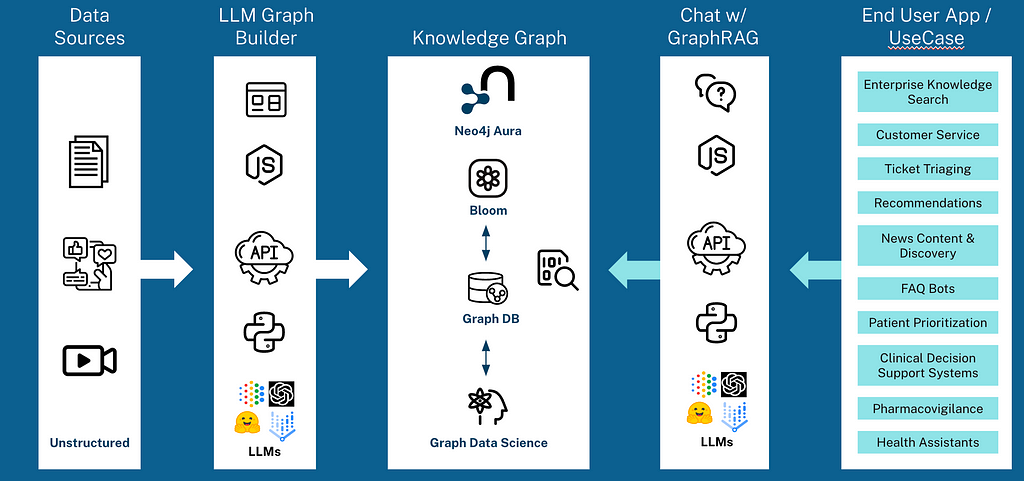
在您的生成式 AI 应用中使用 LLM 知识图谱构建器提取并利用知识图谱。

LLM 知识图谱构建器(https://llm-graph-builder.neo4jlabs.com/) 是 Neo4j 的 GraphRAG 生态系统工具之一,使您能够将非结构化数据转换为动态知识图谱。它与增强检索生成(RAG)聊天机器人集成,能够进行自然语言查询并提供可解释的数据洞察。
什么是 Neo4j LLM 知识图谱构建器?
Neo4j LLM 知识图谱构建器是一款创新的在线应用,可以无需代码和 Cypher 将非结构化文本转换为知识图谱,提供了神奇的文本到图谱体验。
它使用机器学习模型(LLM:OpenAI、Gemini、Diffbot)将 PDF、网页和 YouTube 视频转换为实体及其关系的知识图谱。
前端是基于我们的 Needle Starter Kit的 React 应用,后端是一个基于 Python FastAPI 的应用。它使用了 Neo4j 向 LangChain 贡献的 llm-graph-transformer 模块。
该应用提供了无缝体验,分为四个简单步骤:
- 数据摄取 — 支持多种数据源,包括 PDF 文档、维基百科页面、YouTube 视频等。
- 实体识别 — 使用 LLM 从非结构化文本中识别并提取实体和关系。
- 图谱构建 — 将识别的实体和关系转换为图谱格式,利用 Neo4j 的图谱功能。
- 用户界面 — 提供直观的 Web 界面,用户可以与应用进行交互,上传数据源、可视化生成的图谱,并与 RAG 代理互动。这一功能特别令人兴奋,因为它允许像与知识图谱本身对话一样直观地与数据进行交互 — 无需技术知识。
让我们试试看
我们在 Neo4j 托管环境(https://llm-graph-builder.neo4jlabs.com/) 提供了该应用,无需信用卡,无需 LLM 密钥 — 零门槛。
或者,您也可以在本地或您的环境中运行它,访问公共 GitHub 仓库(https://github.com/neo4j-labs/llm-graph-builder) 并按照我们将在本文中介绍的分步说明进行操作。
在打开并使用 LLM 知识图谱构建器之前,让我们创建一个新的 Neo4j 数据库。为此,我们可以通过以下步骤使用免费的 AuraDB 数据库:
- 登录或创建一个账户在 https://console.neo4j.io。
- 在实例下,创建一个新的 AuraDB 免费数据库。
- 下载凭证文件。
- 等待实例运行。
现在我们的 Neo4j 数据库已运行并获取了凭证,我们可以打开 LLM 知识图谱构建器,并点击右上角的 Connect toNeo4j 按钮。
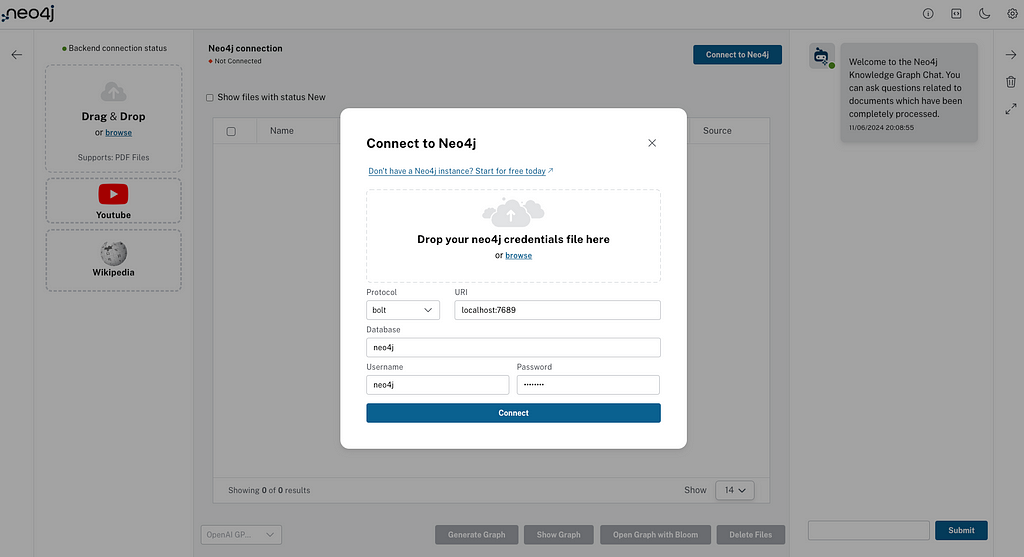
在连接对话框中拖放先前下载的凭证文件。所有信息都会自动填写。您也可以手动输入所有内容。
构建知识图谱
这个过程从非结构化数据的摄取开始,然后通过 LLM 识别关键实体及其关系。
您可以将 PDF 和其他文件拖放到左侧的第一个输入区域。第二个输入区域允许您复制/粘贴 YouTube 视频的链接,第三个输入区域则接受维基百科页面的链接。
在这个示例中,我将加载一些关于一家名为 GraphACME 的供应链公司的 PDF 文件,以及一篇来自 Forbes 的新闻文章、一个关于公司可持续性尽职调查指令(CSDDD)的 YouTube 视频,还有两篇维基百科页面:公司可持续性尽职调查指令(https://en.wikipedia.org/wiki/Corporate_Sustainability_Due_Diligence_Directive) 和 孟加拉国(https://en.wikipedia.org/wiki/Bangladesh)。
在上传文件时,应用程序会使用 LangChain 文档加载器和 YouTube 解析器将上传的源文件存储为图中的文档节点。上传完所有文件后,您会看到类似如下的界面:
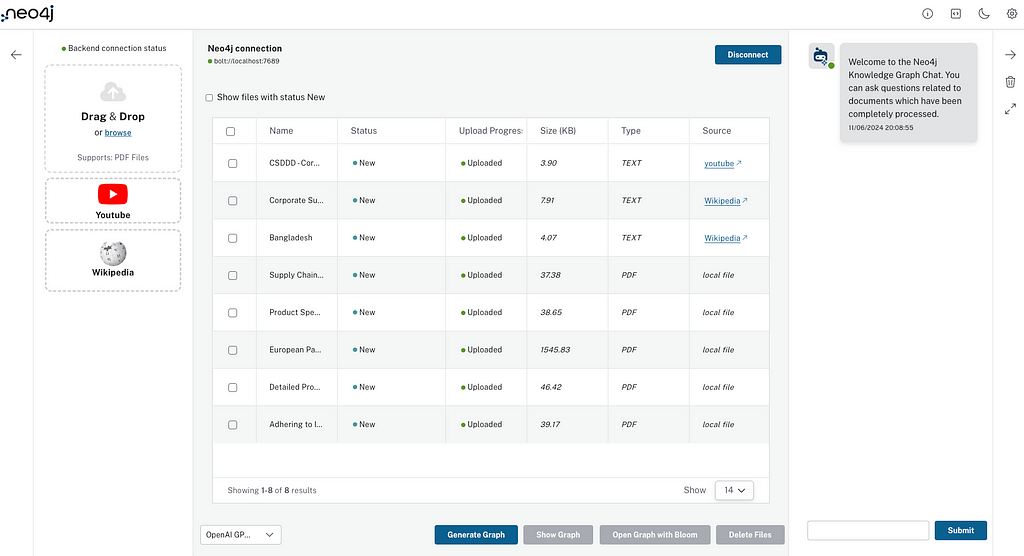
现在我们只需要选择要使用的模型,点击 Generate Graph,剩下的交给魔法吧!
如果您只想生成选定的文件,可以先勾选文件(表格第一列的复选框中)并点击 Generate Graph。
⚠️ 请注意,如果您想使用预定义的或自定义的图谱架构,可以点击右上角的设置图标,并从下拉菜单中选择一个预定义架构、使用自定义的节点标签和关系、从现有的 Neo4j 数据库中提取架构,或复制/粘贴文本并请求 LLM 进行分析并提出建议的架构。
在处理文件并创建您的知识图谱时,以下是后台的主要步骤:
- 内容被分割成块。
- 这些块被存储在图谱中,并与文档节点和其他块连接,以用于高级 RAG 模式。
- 高度相似的块通过 SIMILAR(相似)关系连接起来,形成 K-近邻图。
- 在块和向量索引中计算并存储嵌入。
- 使用 llm-graph-transformer 或 diffbot-graph-transformer,从文本中提取实体和关系。
- 实体被存储在图中,并连接到来源块。
探索您的知识图谱
从文档中提取的信息被结构化为图谱格式,其中实体成为节点,关系则成为连接这些节点的边。使用 Neo4j 的优势在于它能够有效地存储和查询这些复杂的数据网络,使生成的知识图谱能够立即应用于各种场景。
在我们使用 RAG 代理提问之前,您可以选择一个或多个文档,并点击 Show Graph 来展示文档生成的实体;您也可以在该视图中显示文档和块节点。
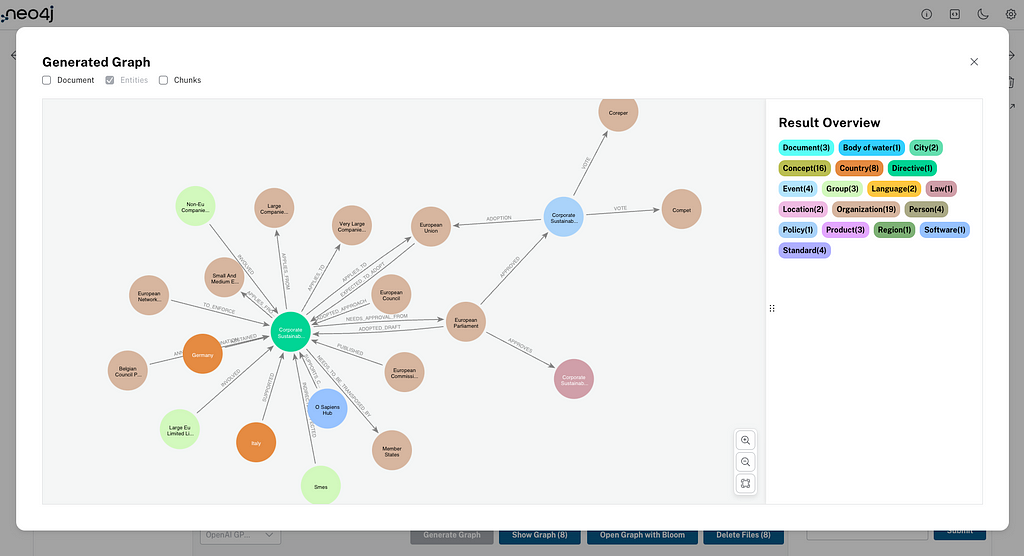
Open Graph with Bloom 按钮将打开 Neo4j Bloom,帮助您可视化和探索新创建的知识图谱。接下来的操作 Delete files 将从图谱中删除选定的文档和块(如果在选项中选择了它们,还会删除实体)。
与知识对话
现在到了最后一步:您可以在右侧面板中看到 RAG 代理。
检索过程 — 它是如何工作的?
下图展示了 GraphRAG 过程的简化视图。
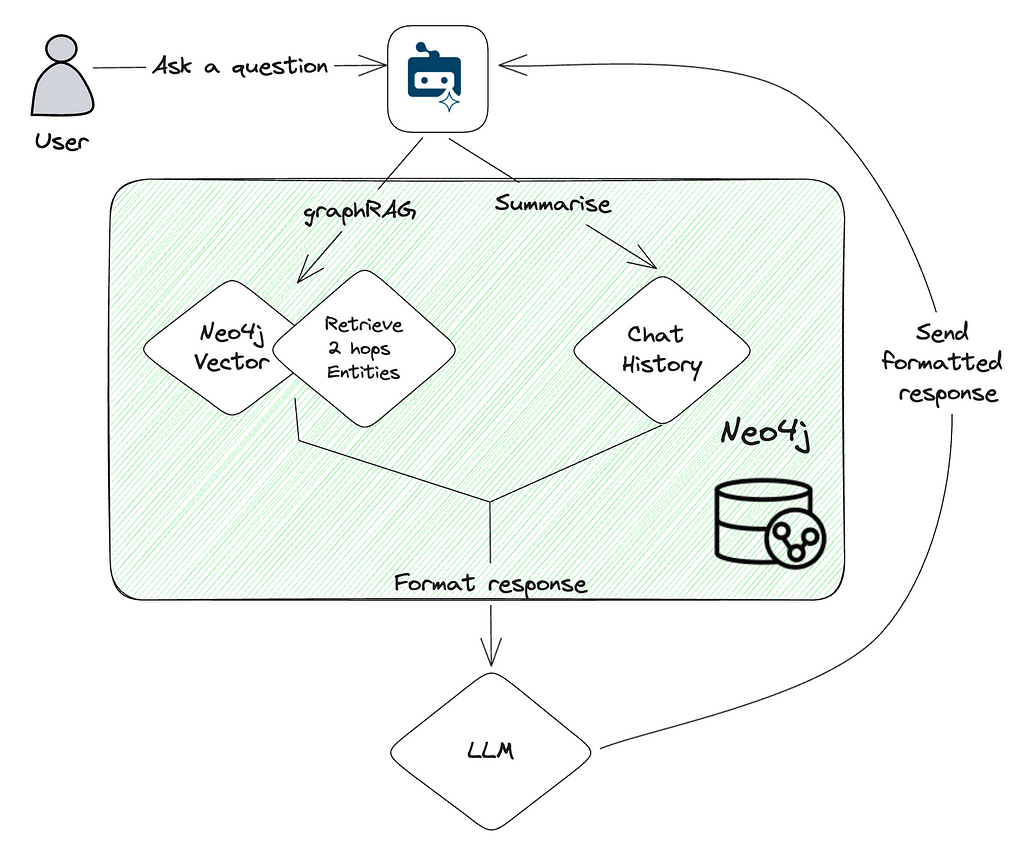
当用户提出问题时,我们使用 Neo4j 向量索引进行检索查询,找出与问题最相关的块及其连接的实体,最多可达两跳。我们还会总结聊天记录,并将其作为丰富上下文的元素。
各种输入和来源(问题、向量结果、聊天记录)都被发送到选定的 LLM 模型中,通过自定义提示词请求模型基于提供的元素和上下文生成并格式化答案。当然,提示词中还有更多的设计,如格式化、要求引用来源、在不确定时不进行猜测等。完整的提示词和指令可以在 QA_integration.py(https://github.com/neo4j-labs/llm-graph-builder/blob/main/backend/src/QA_integration.py#L59) 中找到,名为 FINAL_PROMPT。
询问与您的数据相关的问题
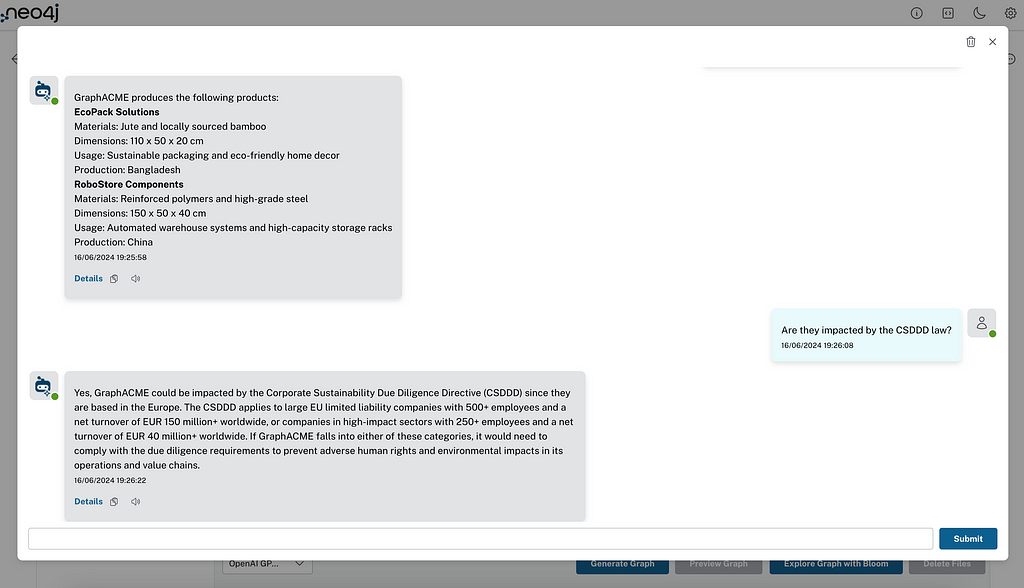
在这个例子中,我加载了关于虚拟公司 GraphACME 的内部文件,该公司位于欧洲,记录了其整个供应链战略和产品。我还加载了一篇新闻文章和一个 YouTube 视频,解释了新的 CSDDD 法规及其影响。现在,我们可以向聊天机器人提问有关虚拟公司内部知识的问题 — 关于 CSDDD 法律的问题,甚至是跨越两者的问题,例如询问 GraphACME 生产的产品清单,它们是否会受到 CSDDD 法规的影响,以及如果会,如何影响公司。
聊天功能
在主屏幕的右侧,您会注意到三个按钮附加在聊天窗口上:
- Close 将关闭聊天机器人界面。
- Clear chat history 将删除当前会话的聊天记录。
- Maximize window 将以全屏模式打开聊天机器人界面。
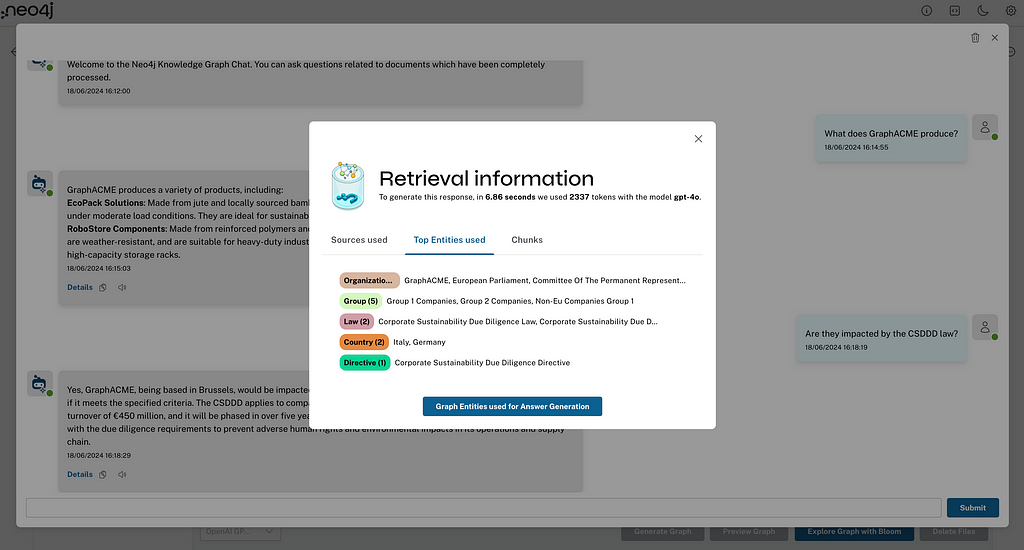
在 RAG 代理的回答中,您会在回复后找到三个功能:
- Details 将打开一个检索信息弹出窗口,显示 RAG 代理如何收集和使用来源(文档)、块和实体。还包括关于使用的模型和 Token 消耗的信息。
- Copy 将把响应内容复制到剪贴板。
- Text-to-Speech 将朗读响应内容。
总结
要深入了解 LLM 知识图谱构建器,GitHub 仓库(https://github.com/neo4j-labs/llm-graph-builder) 提供了丰富的信息,包括源代码和文档。此外,文档(https://neo4j.com/labs/genai-ecosystem/llm-graph-builder/) 提供了详细的入门指南,GenAI 生态系统(https://neo4j.com/labs/genai-ecosystem/) 提供了更广泛的工具和应用程序的深入见解。