
原子层沉积研究 + 知识图谱 + 大语言模型(LLM)——图片由作者利用 ChatGPT 生成。
原子层沉积(Atomic Layer Deposition, ALD)[1] 是一种用于以极薄层逐原子层涂覆材料的技术。该工艺能够对涂层的厚度和组成进行非常精确的控制,非常适合电子学和纳米技术等需要高精度的应用。本质上,这就像用原子“作画”,通过逐步堆叠层来实现所需的涂层效果。
在 ALD 中,“工艺材料”和“工艺反应物”是关键元素。工艺材料是沉积原子层的基底,其化学组成、表面结构和温度显著影响薄膜的附着性和质量。而工艺反应物则是用于构建这些层的化学物质。ALD 涉及基底与这些反应物的顺序接触,每次反应都以自限制的方式与表面作用,从而实现每个循环沉积一层原子。这种精确的相互作用决定了薄膜的最终组成。例如,创建氧化铝(Al₂O₃)薄膜可能需要使用三甲基铝和水作为反应物。这种细致的控制对于电子学、光学和其他领域的应用至关重要,能够确保薄膜厚度和组成的均匀性和精确性。
基于此,本文介绍并讨论了一种在知识图谱(Knowledge Graph, KG)中记录 ALD 工艺的新方法,特别是开放研究知识图谱(Open Research Knowledge Graph, ORKG)[2],使得生成的数据为人工智能(AI)所准备。此外,还探讨了一种轻量级但有效的方法,利用大语言模型(LLM)从现有研究文章中回溯提取信息,以填充聚焦于 ALD 工艺信息的 AI 可用 ORKG。
利用语义网(Semantic Web)[3] 工具(如知识图谱)创建 AI 可用的 ALD 数据库,能够变革传统的 ALD 工艺报告方式,提升数据的可发现性、互操作性和语义丰富性。这些结构化数据库支持更动态的更新与协作,允许自动推理以推导新知识并对 ALD 工艺进行预测。知识图谱通过以机器学习模型可直接使用的方式结构化 ALD 数据,使其更具 AI 可用性。这种方法能够更高效地预测新材料的特性或优化工艺参数,相较于传统的统计方法具有显著优势。通过使 ALD 数据更易获取和操作,知识图谱赋能研究人员利用先进的分析和预测能力,推动该领域的可能性边界。
知识图谱用于存储实体(对象、事件或概念)的互联描述,其数据既对人类操作员又对机器可语义理解。它们利用语义网技术(如本体论、RDF(资源描述框架)和 SPARQL)跨领域链接数据,并实现更好的数据集成、查询和推理。通过这样做,知识图谱在使数据对 AI 和机器学习应用可操作和可访问方面发挥了关键作用。
创建与 ALD 工艺相关的知识图谱的第一步是定义一个模式,即一组捕捉 ALD 工艺关键信息的属性。下方的 JSON 文件展示了一个包含 41 行代码的模式。
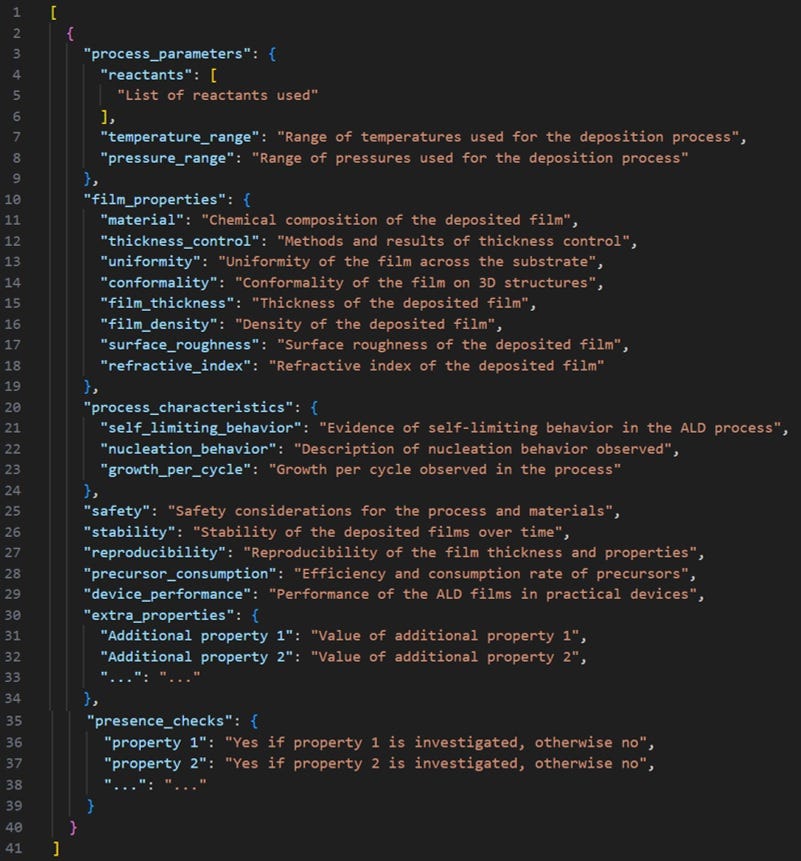
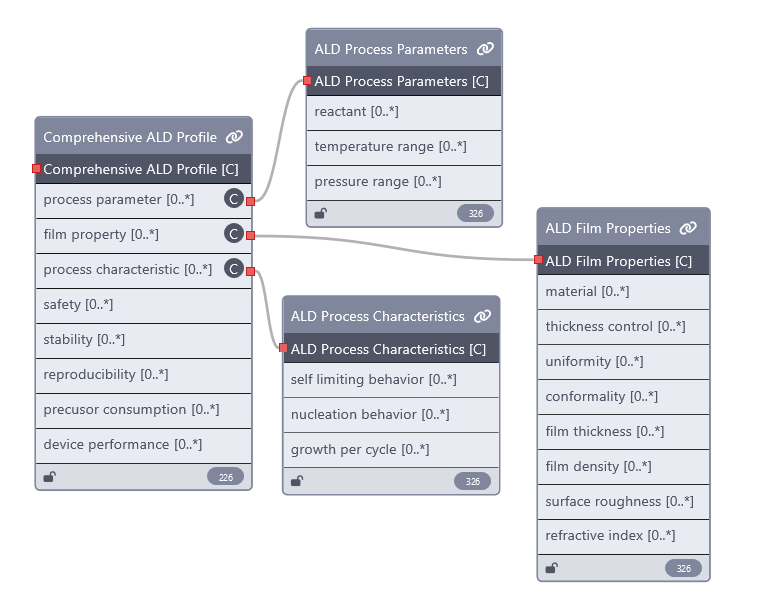
虽然该模式在“将温度和压力单位链接到标准单位本体(如 QUDT 本体)或材料科学本体(如 EMMO、MatOnto)”[4] 方面仍有改进空间,但它为以结构化方式记录 ALD 工艺信息提供了良好的起点。由于本次练习的最终目标是创建 ORKG 中的 AI 可用数据库,我已将此模式定义为 ORKG 中的模板。以下是该模板的链接:https://orkg.org/template/R733029。下方图 2 提供了一个类似 UML 的类图说明。
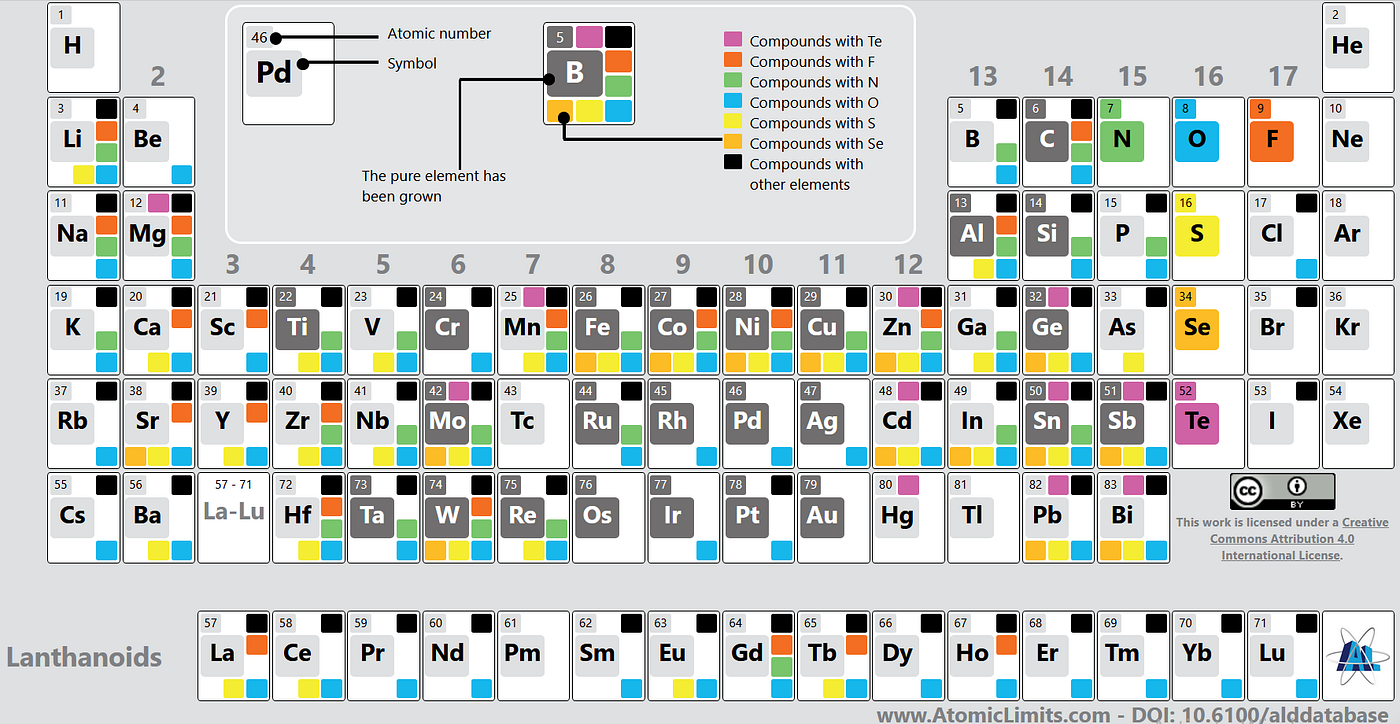
接下来,需要从 ALD 数据库中编制 ALD 研究论文列表,以基于该模式提取结构化的 ALD 工艺描述。我利用了 AtomicLimits ALD 数据库——这是由该领域专家精心策划的备受推崇的资源。您可以在此处探索:https://www.atomiclimits.com/alddatabase/。该数据库解决了 ALD 工艺的爆炸性增长问题,涵盖了不断扩展的材料范围,从而提高了相关研究的可发现性。由于为大量材料开发了大量 ALD 工艺,荷兰埃因霍温理工大学(由 Erwin Kessels 教授领导)创建了一个在线数据库,专家社区可以在其中提交与研究论文相关的材料和反应物。以下是向社区介绍此数据库的帖子。此外,该数据库被创意性地可视化为一个 ALD 元素周期表,使其不仅是一个实用工具,也为用户提供了视觉上的吸引力。
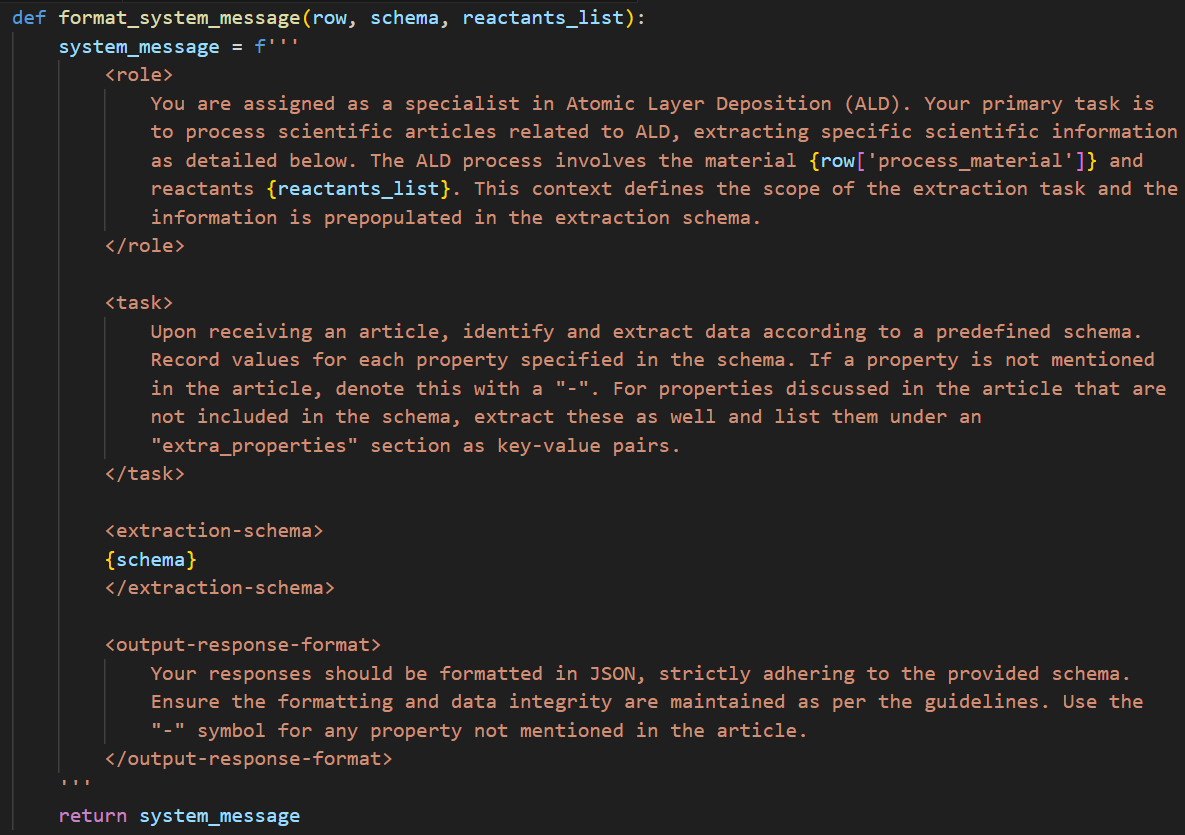
在从 ALD 数据库编制论文列表并执行知识提取支持任务(如获取论文全文以利用 ORKG Ask API 挖掘知识)后,我将重点转向大语言模型(LLM),特别是定义知识提取提示词。OpenAI 的 GPT 模型是一个相对易于设置的起点,因为用户可以直接使用其 API 查询模型,而无需担心托管 LLM 所需的 GPU 资源。在此,我选择使用最近的 GPT-4o LLM,并利用 Assistants API。我定义了系统提示词。系统提示词定义了 GPT 助手的角色,以使其行为(“身份”)与最终任务对齐。另一方面,用户提示词则用于与该角色对齐的 GPT 助手交互,提供查询、语句或输入文本,从中提取数据并期望其成功完成任务。根据 GPT-3 论文(Brown 等人)首次提出的上下文学习范式,用户提示词还可以包含少样本学习示例,展示任务成功完成的方式。回到与 ALD 工艺结构化信息提取相关的系统提示词定义,下方图 3 展示了最终使用的提示词。
以下是您可以尝试的练习:作为对上述工作流程的快速增强,使用 Instructor Python 库修改代码,使其更容易处理来自 LLM 的结构化输出。另一个练习:用 LiteLLM 替换 OpenAI API,使其更容易查询其他 LLM。
总结一下,到目前为止,这篇文章涵盖了使用 LLM 在复杂科学领域中编制研究知识的端到端工作流程的多个方面。文章首先介绍了 ALD 领域,并概述了知识提取的模式,该模式将塑造研究知识图谱。随后探讨了主要工具——LLM,它凭借其庞大的参数空间和生成式 AI 能力,成为在这一复杂领域中执行知识提取任务的强大工具,并有望以合理的准确性完成任务。关于评估 LLM 输出和定义知识管理工作流程的具体话题,我将在另一篇文章中讨论。
拥有结构化知识后,最后一步是将其存储在 ORKG 中,作为 AI 可用数据库。为此,可以利用 ORKG Python Package 的各种模块以编程方式上传结构化数据,并使其与 Comprehensive ALD Profile ORKG 语义模板对齐。如此,我们便使用 LLM 为复杂科学领域编制了一个研究知识图谱!
成果与影响
ORKG 示例论文:查看一篇导入的 ORKG 示例论文,标题为“CsI 和 CsPbI3 的原子层沉积”,其中包括这两种材料(CsI 和 CsPbI3)的结构化 ALD 工艺描述,分别作为详细的机器可操作数据。
- CsI 贡献:https://orkg.org/paper/R732976/R739356
- CsPbI3 贡献:https://orkg.org/paper/R732976/R739360
ORKG 比较:ALD 工艺研究概述:探索 167 项 ALD 工艺贡献的比较概述,如下方图 4 所示的快照。此比较提供了结构化摘要,便于快速审阅 ALD 工艺的研究发现和方法。
- 查看比较:https://orkg.org/comparison/R739481

本文中的工作流程定义于“AI 感知的可持续半导体工艺与制造技术路径 (AWASES)”研究项目的背景下。该项目由默克和英特尔合作资助。与埃因霍温大学、L3S 研究中心和华威大学的研究人员合作,我们的目标之一是通过从 ALD/E(原子层沉积/刻蚀)工艺中提取和整合知识来开发 AI 可用数据库。我们基于现有的众包数据库,例如 TU/e 于 2019 年推出的数据库(TU/e Atomic Limits ALD Database, DOI: 10.6100/alddatabase)。我们的目标是使这些数据库为 AI 应用做好准备,从而推动材料设计、自主实验和 AI 驱动的工艺开发方面的创新。作为朝这一目标迈出的重要一步,通过将结构化 ALD 工艺数据导入 ORKG,用户可以通过 ORKG 平台访问论文或比较。特别是相关论文可以在我们的 AWASES 项目观测站中找到。此集成支持增强的发现和研究分析能力,促进对 ALD 技术的深入理解和进一步研究。
最后,我已将用于重现本文工作流程的脚本公开在 Github:https://github.com/jd-coderepos/awases-ald/
作为结束语,我想为处理文本数据挖掘任务(尤其是科学文章)提供一些我发现特别相关且有效的工具推荐……
文本数据挖掘的附加资源——工具小清单(参考:强烈推荐这一出色的资源 https://matextract.pub/index.html [4])
- crossrefapi —— 一个 Python 库,用于通过 CrossRef 从各种来源获取相关科学文章的元数据。示例用法:提取并保存关于“Buchwald-Hartwig 偶联”主题的 100 个来源的元数据到 JSON 文件中。https://matextract.pub/content/obtaining_data/crossref_search.html
- pygetpapers —— 使用该库可以从开放访问数据库中收集文章,支持多个开放访问 API,包括 eupmc、crossref、arXiv、bioRxiv、medRxiv 和 rxivist-bio。
- paperscraper —— 一个 Python 包,用于从 PubMed 或预印本服务器(如 arXiv、medRxiv、bioRxiv 和 chemRxiv)抓取出版物元数据或完整 PDF 文件。示例用法:从 ChemRxiv 下载关于“Buchwald-Hartwig 偶联”主题的全文文章。https://matextract.pub/content/obtaining_data/data_mining.html
- marker —— 一个 Python 库,可快速高精度地将 PDF 转换为 Markdown;已与 nougat 进行比较。
- docTR(文档文本识别) —— 一个无缝、高性能且易于访问的 OCR 相关任务库,由深度学习驱动。支持从 PDF 或图像中解释文档。
参考文献
- Steven M. George (2010). 原子层沉积:概述。 化学评论,110(1),111–131。
- Sören Auer, Allard Oelen, Muhammad Haris, Markus Stocker, Jennifer D’Souza, Kheir Eddine Farfar, Lars Vogt, Manuel Prinz, Vitalis Wiens, and Mohamad Yaser Jaradeh (2020). 通过知识图谱改善科学文献的访问。 Bibliothek Forschung und Praxis,第 44 卷,第 3 期,第 516–529 页 https://doi.org/10.1515/bfp-2020-2042
- Tim Berners-Lee, James Hendler, and Ora Lassila (2023). 语义网:一种对计算机有意义的新型 Web 内容形式,将释放新的可能性革命。 收录于 链接世界信息:关于 Tim Berners-Lee 发明万维网的论文,第 91–103 页 https://doi.org/10.1145/3591366.3591376
- Mara Schilling-Wilhelmi, Martiño Ríos-García, Sherjeel Shabih, María Victoria Gil, Santiago Miret, Christoph T. Koch, José A. Márquez, and Kevin Maik Jablonka (2024). 从文本到洞察:用于材料科学数据提取的大语言模型。 arXiv preprint arXiv:2407.16867。
- Adrie Mackus, Bart Macco, Bora Karasulu, Jennifer D’Souza, Sören Auer, & Erwin Kessels. 将在线 ALD 和 ALE 数据库转化为 AI 可用工具,用于开发新型可持续材料和制造工艺。 在 AVS 第 24 届国际原子层沉积会议(ALD 2024)上展示的海报。查看海报